

In the last three years, the Verizon network has supported hundreds of thousands of live-streamed sporting events, massive software downloads, billions of hours of streaming video content, and demands from thousands of web applications that all require real-time responsiveness and globally consistent performance. To support this massive growth, since 2015, our global network has grown to 71 Tbps, requiring thousands of new servers across our 135+ PoPs.
To keep up with the challenge of deploying a network footprint that is always growing and changing, our Operations teams developed an IT automation platform using StackStorm. It’s a giant leap forward that has transformed how our teams deploy, change, repair, and decommission server infrastructure, spanning more than 95% of the server population across our global network.
Here’s a look at how we built an automation platform that enabled us to:
- Add more than 12,000 servers to our network in under three years
- Automate ticket generation in some cases and resolve issues without tickets in others
- Give our teams tools so they can collaborate in real time
- Reduce engineer time spent following a manual series of steps.
Customizing StackStorm into project Crayfish
Recognizing the value and increasing maturity of IT automation platforms, in 2015, we formed the Infrastructure Automation team under the project name Crayfish and began developing an IT automation solution in earnest — no small task for an organization of our size. The choice of name for the project — which we are still using — was intentional. We’ve long had fish and nautical themes for our tools, but more than that, we chose Crayfish because they serve as filter-feeders, helping to keep the environment they live in clean.
Initially, we considered developing our own IT automation framework, but decided early on that StackStorm, with additional enhancements to support our unique requirements and scale, allowed us to move forward most effectively. StackStorm is an open source event-driven platform that supports an ‘infrastructure as code’ approach to DevOps automation. It excels at running workflows based on events and integrates with Slack, which we use across our operations teams, and it has native ChatOps support.
Some configuration changes have been made to StackStorm to enable it to run at the scale we need. Primarily, this involved increasing the number of running service instances and reducing data retention. When we started the project, our network consisted of 8,000 servers. Now we’re at 20,000 servers and counting. The key to our scalability has been the ability to run any number of StackStorm instances as workers, rather than trying to make a single StackStorm instance handle everything. As shown in the illustration below, this is made possible by something we’ve developed called Policy Engine, which gates the submission of requests to StackStorm based on our business logic. Policy Engine can optionally queue up requests and automatically run them when the policies determine it is safe to do so. These policies monitor concurrency, capacity, traffic, production status, infrastructure, blacklists, and failure rate.
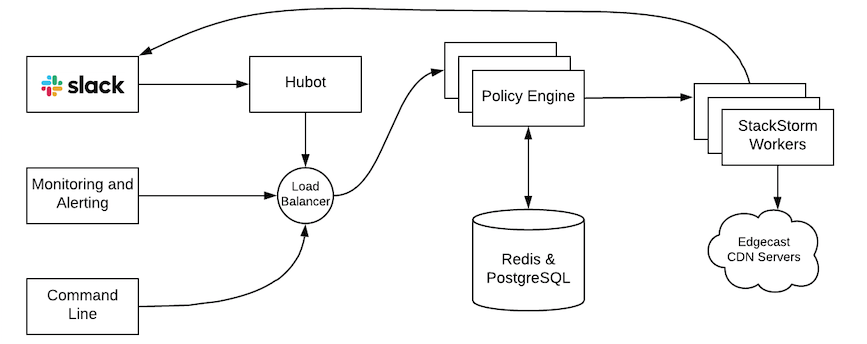
Figure 1 — Submission requests route through a Policy Engine instance to any number of StackStorm workers for virtually unlimited scalability.
Codifying tribal knowledge
The basic approach in any IT automation project is to capture existing processes and workflows, turn them into code that can implement the workflow steps without manual intervention, and store the codified workflows in a centralized repository where they can be called up as needed, either as part of other automation or through ChatOps commands.
Once the project got underway, the Crayfish team captured existing workflows and processes from across the organization. Fortunately, the majority of the most important processes used by different groups, such as the Network Operation Centre (NOC), Data Centre Operations or SysOps were well-documented and could quickly be codified using the Python programming language and added to Crayfish.
For example, if our NOC wanted to implement a reboot workflow, it would first need to verify that it is safe to work on the machine based on various policy checks. For example, if a server were in production, the system would take steps to drain connections and update the status. Next, it would perform the actual reboot and the steps necessary to verify that the machine is ready for production before finally returning it to production.
To be sure, there were plenty of edge cases. Among the most challenging were processes that had not made it to documentation. These tribal-knowledge cases required cross-functional collaboration and speaking to the individuals whose expertise ensured they were handled correctly. One side benefit of the automation effort was we were able to capture this knowledge, ensuring that it stays within our organization going forward.
In some cases, we were even able to identify more efficient ways of handling a particular task by connecting with several engineers and technicians who understood what was going on for a specific task or how to fix a particular problem. We found that in some cases, there were different levels of knowledge between various members of a team. That’s when we would gather everyone’s intelligence and come up with a single workflow that everyone agreed would provide the most efficient solution.
Deploying new servers on demand
Crayfish has transformed our IT operations on many levels, such as simplifying server administration, reducing server downtime, and speeding server deployment. In 2018 alone, ITOps added 22 Tbps capacity to our global network. Adding thousands of servers would not have been possible without the automation of Crayfish. And it was accomplished without significantly increasing staff levels.
Currently, Crayfish provides robust automation for about 20 different server types. In our organization, we define a server type as a group of servers that run more or less the same service. Different applications run on different server types, and therefore each server type has different needs in terms of support when in production. Today, Crayfish supports the full server life cycle for about 10 server types and can also do most repairs, revisions, and patching for about 10 additional server types. It also provides varying degrees of support for about 40 or 50 more. Since we focused on the most widely deployed server types, Crayfish supports approximately 96% of our global server population.
The use of Crayfish has led to an overall increase in the performance of the CDN and its ability to accommodate unexpected events. Our network is well equipped to support massive, ever-increasing traffic from major sporting event streams and peak software downloads, for example, by keeping more servers in production and reducing the interruption of removing servers from production during peak traffic times.
Our scale contributes to why Crayfish is essential from a performance perspective. If your company has one data centre, you can schedule downtime, and you can stay on top of the needs of that data centre. But when you’re talking about a data centre in almost every time zone as shown in the network map below, you have to contend with different profiles, usage, and times of usage. Taking all those factors into account on a case-by-case basis can be extremely complex, but Crayfish handles it with ease.
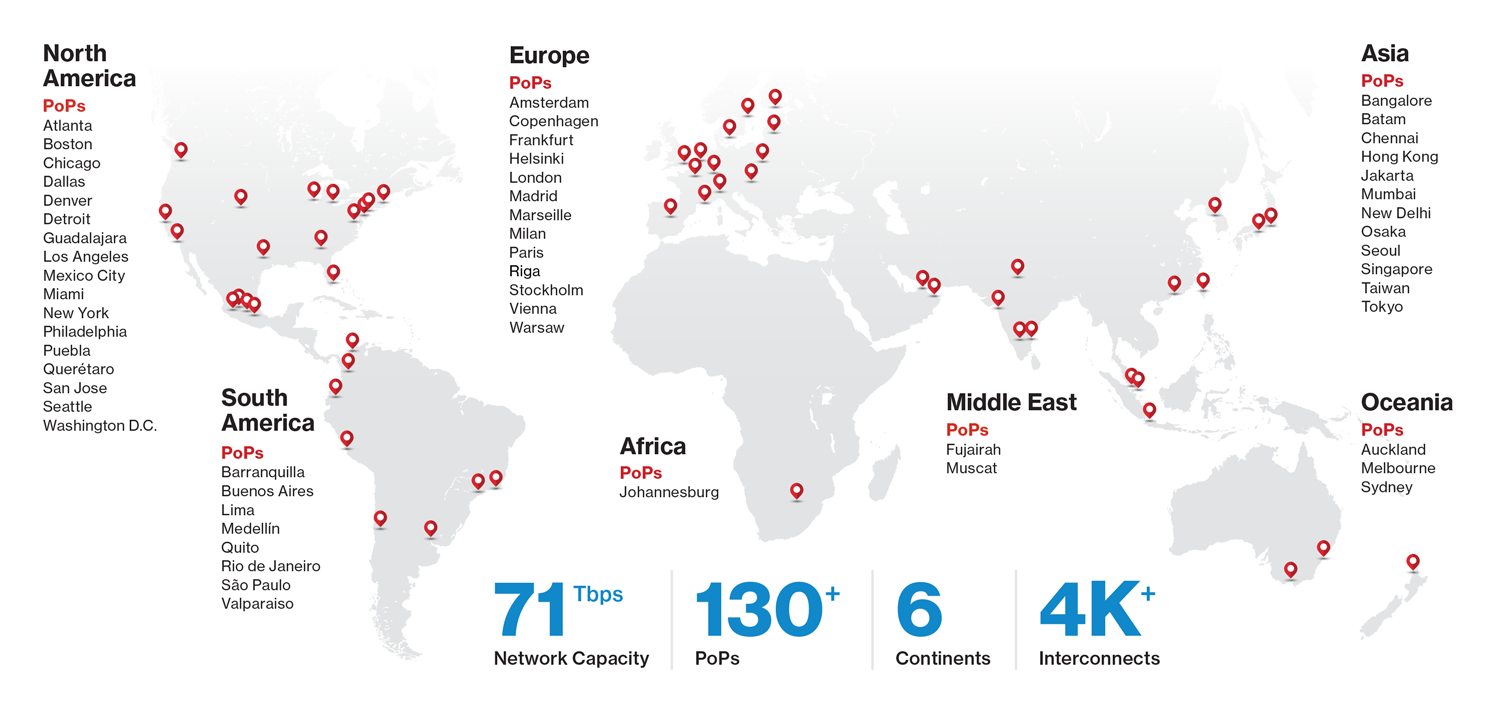
Figure 2 — Since 2015, our global network has grown to 71 Tbps, requiring thousands of new servers across our 135+ PoPs.
With Crayfish, we can still schedule tasks such as provisioning or upgrades to occur automatically, but the system is smart enough to accommodate local needs. Let’s say a news event in Latvia causes a large spike in video streaming right when we wanted to reprovision all the servers in Latvia. Because of the integration between Crayfish and our metrics collection system, the system would see the traffic increase and reprovisioning would stop. It could even put more servers into production if needed.
Catching infrastructure failures before they become service outages
Crayfish combined with other monitoring systems significantly reduces individual server downtime and repair time. Our systems continuously monitor the network for problems or failures and can automatically create tickets or directly apply fixes. With automated systems, staff are not required to have their ‘eyes on glass’ to spot network errors — computers never get bored or tired and monitor continuously.
There’s very little limitation to the amount of checking that can be done in this fashion. Our metrics system continuously runs hardware checks that don’t require taking machines out of production, while another system looks for bad values and will call Crayfish to check on the machine when problems are found. With this approach, we’re able to catch hardware failures very early on.
For instance, if metrics show that a hard drive is starting to fail, automated systems will kick off a workflow in Crayfish that verifies the error on the impacted machine and collects details about the failure, such as what hard drive failed in what slot, the shield number and so on. It then creates a specially crafted ticket for the Data Centre Operations group and a technician will be dispatched to install a replacement.
Historically, any manual workflow that required multiple departments to coordinate or hand off between steps introduced significant delay along the way. With an automated workflow, the time to completion can be minutes instead of days spent in a ticket queue waiting for the request to pop up. This puts more control in the hands of the individual operations teams who know their systems and applications the best.
Giving engineers tools that make them more productive
Our previous approach to NOC work involved issuing a command and waiting for things to happen. If a NOC technician is spending 10, 20 or 30 minutes waiting for a server to gracefully shut down, you have to ask why. Is that a good use of time? Crayfish can run many, many executions in parallel. And, as noted earlier, Crayfish was designed to scale horizontally. So, if we need to do more work, we can add a new node. If we suddenly find ourselves having to do a lot of work all at once, we can scale up a couple of nodes across the entire CDN and then scale it back down.
Also, technicians only have so much working memory in terms of how many machines they can be working on at any one time. Only the most exceptional multitasker can handle more than five or six machines in different states at a time without losing track or making errors. But with Crayfish, there’s no need to jump between various tasks, they can issue a command and move on.
Building on existing smart provisioning systems developed by the Software Infrastructure and Systems Operations teams, other aspects of server life cycles are fully supported within Crayfish and happen largely autonomously, including operating system updates, server provisioning or reprovisioning, firmware updates, and security patches. When a new patch is released, Crayfish speeds up validation testing to ensure that the patch is okay to be released.
Because Crayfish is integrated with Slack, it supports normal IT processes and facilitates collaborative work as needs and requirements change. Rather than waiting on a single department to implement a change, teams can now define their manual process as an automated workflow. They can then give the workflow to end users to run on demand. Any policies to limit when a workflow can safely run can also be implemented. This also allows an engineer who is standing in front of a server in a data centre to issue a command to change the production status of a server they would like to work on.
Final thoughts
With thousands of customers pushing terabytes of data over our global network of more than 20,000 servers daily, our implementation of StackStorm has become an essential operational tool to keep our services healthy and secure. It’s enabled us to scale our network more quickly to meet customer demand while offering better performance despite dynamic changes and unexpected traffic surges. This operational agility makes us a more reliable service provider that can scale to meet streaming media and web application demands.
While most organizations don’t operate on the same scale as we do, there are still a number of operational table stakes that can make automation attractive, including its ability to:
- Focus developers on work that generates a higher return.
- Standardize routine and mundane tasks.
- Improve collaboration across departments.
- Reduce server downtime.
- Improve security by implementing firmware updates and security patches.
Without question, the move to IT automation offers a very attractive return on investment, but it’s important to make sure you’re making the move for the right reasons. A good approach is to think of automation as a way to give engineers tools that will make them more productive and proficient, as well as allowing them to focus on improvements.
If done right, the transition to workflow-based automation is an excellent way to socialize and codify tribal knowledge. Instead of everyone having their own approach — we bring the tribe together, come up with a common workflow, and enable everyone to contribute future knowledge gained to a single bottom line.
Contributors:
Adapted from original post which appeared on Verizon Digital Media Services.
John Welborn is a Senior Software Engineer at Verizon Digital Media Services with experience with large-scale vfx renderfarms, CDNs, and automation.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.