
On a BGP-routed network with multiple redundant paths, we seek to achieve two goals concerning reliability:
- A failure on a path should quickly bring down the related BGP sessions. A common expectation is to recover in less than a second by diverting the traffic to the remaining paths.
- As long as a path is operational, the related BGP sessions should stay up, even under duress.
Detecting failures fast: BFD
To quickly detect a failure, BGP can be associated with Bidirectional Forwarding Detection (BFD), a protocol for detecting faults in bidirectional paths, defined in RFC 5880 and RFC 5882. BFD can use very low timers, like 100 ms.
However, when BFD runs in a process on top of a generic kernel, notably when running BGP on the host, it is not unexpected to lose a few BFD packets under adverse conditions — the daemon handling the BFD sessions may not get enough CPU to answer in a timely manner. In this scenario, it is not unlikely for all the BGP sessions to go down at the same time, creating an outage, as depicted in the last case in the diagram below.
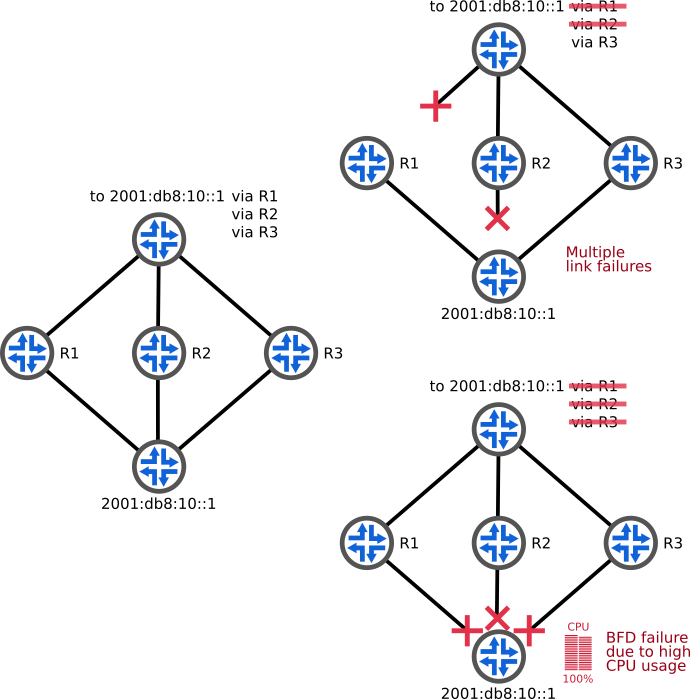 Figure 1: Examples of failures on a network using BGP as the underlying routing protocol. A link failure is detected by BFD and the failed path is removed from the Equal-Cost Multi-Path (ECMP) route. However, when high CPU usage on the bottom router prevents BFD packets from being processed in time, all paths are removed.
Figure 1: Examples of failures on a network using BGP as the underlying routing protocol. A link failure is detected by BFD and the failed path is removed from the Equal-Cost Multi-Path (ECMP) route. However, when high CPU usage on the bottom router prevents BFD packets from being processed in time, all paths are removed.
Notes on BFD
- With point-to-point links, BGP can immediately detect a failure without BFD. However, with a pair of fibres, the failure may be undirectional, leaving it undetected by the other end until the expiration of the hold timer.
- On a Juniper MX, BFD is usually handled directly by the
real-time microkernel running on the packet forwarding engine. The
BFD control packet contains a bit indicating if BFD is implemented
by the forwarding plane or by the control plane. Therefore, you
can check withtcpdumphow a router implements BFD. Here is an
example where10.71.7.1, a Linux host running BIRD, implements
BFD in the control plane, while10.71.0.3, a Juniper MX, does
not:$ sudo tcpdump -pni vlan181 port 3784 IP 10.71.7.1 > 10.71.0.3: BFDv1, Control, State Up, Flags: [none] IP 10.71.0.3 > 10.71.7.1: BFDv1, Control, State Up, Flags: [Control Plane Independent]
So far, we have two contradicting roads: lower the BFD timers to quickly detect a failure along the path, or raise the BFD timers to ensure BGP sessions remain operational.
Fix false positives: BGP LLGR
Long-Lived Graceful Restart (LLGR) is a new BGP capability that retains stale routes for a longer period after a session failure, treating them as least-preferred. It also defines a well-known community to share this information with other routers. It is defined in the Internet-Draft draft-uttaro-idr-bgp-persistence-04 and several implementations already exist:
- Juniper JunOS (since 15.1, see the documentation),
- Cisco IOS XR (unfortunately only for VPN and FlowSpec families),
- BIRD (since 1.6.5 and 2.0.3, both yet to be released, sponsored by Exoscale), and
- GoBGP (since 1.33).
The following illustration shows what happens during two failure scenarios. Like without LLGR, in scenario 2, a link failure is detected by BFD and the failed path is removed from the route as two other paths remain with a higher preference. A couple of minutes later, the faulty path has its stale timer expired and will not be used anymore. Shortly after, in scenario 3, the bottom router experiences high CPU usage, preventing BFD packets from being processed in time. The BGP sessions are closed and the remaining paths become stale, but as there is no better path left, they are still used until the LLGR timer expires. In the meantime, we expect the BGP sessions to resume.
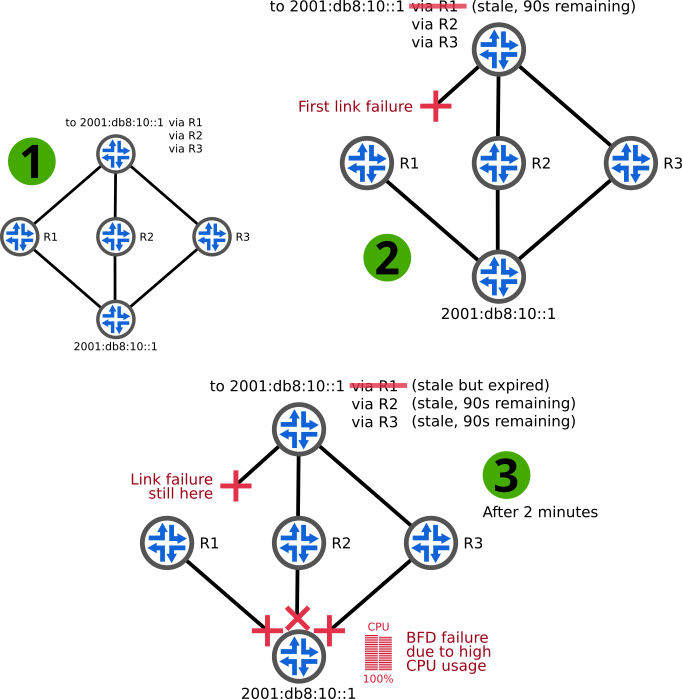
Figure 2: Examples of failures on a network using BGP as the underlying routing protocol with LLGR enabled.
From the point of view of the top router, the first failed path was considered stale because the BGP session with R1 was down. However, during the second failure, the two remaining paths were considered stale because they were tagged with the well-known community LLGR_STALE (65535:6) by R2 and R3.
Another interesting point of BGP LLGR is the ability to restart the BGP daemon without any impact — as long as all paths keep a steady state shortly before and during restart. This is quite interesting when running BGP on the host.
BIRD
Let’s see how to configure Bird Internet Routing Daemon (BIRD) 1.6. As BGP LLGR is built on top of the regular BGP graceful restart (BGP GR) capability, we need to enable both. The timer for BGP LLGR starts after the timer for BGP GR. During a regular graceful restart, routes are kept with the same preference. Therefore it is important to set this timer to 0.
template bgp BGP_LLGR { bfd graceful; graceful restart yes; graceful restart time 0; long lived graceful restart yes; long lived stale time 120; }
When a problem appears on the path, the BGP session goes down and the LLGR timer starts:
$birdc show protocol R1_1 all name proto table state since info R1_1 BGP master start 11:20:17 Connect Preference: 100 Input filter: ACCEPT Output filter: ACCEPT Routes: 1 imported, 0 exported, 0 preferred Route change stats: received rejected filtered ignored accepted Import updates: 2 0 0 0 4 Import withdraws: 0 0 --- 0 0 Export updates: 12 10 0 --- 2 Export withdraws: 1 --- --- --- 0 BGP state: Connect Neighbor address: 2001:db8:104::1 Neighbor AS: 65000 Neighbor graceful restart active LL stale timer: 112/-
The related paths are marked as stale (as reported by the s in 100s) and tagged with the well-known community LLGR_STALE:
$birdc show route 2001:db8:10::1/128 all 2001:db8:10::1/128 via 2001:db8:204::1 on eth0.204 [R1_2 10:35:01] * (100) [i] Type: BGP unicast univ BGP.origin: IGP BGP.as_path: BGP.next_hop: 2001:db8:204::1 fe80::5254:3300:cc00:5 BGP.local_pref: 100 via 2001:db8:104::1 on eth0.104 [R1_1 11:22:51] (100s) [i] Type: BGP unicast univ BGP.origin: IGP BGP.as_path: BGP.next_hop: 2001:db8:104::1 fe80::5254:3300:6800:5 BGP.local_pref: 100 BGP.community: (65535,6)
We are left with only one path for the route in the kernel:
$ip route show 2001:db8:10::1 2001:db8:10::1 via 2001:db8:204::1 dev eth0.204 proto bird metric 1024 pref medium
To upgrade BIRD without impact, it needs to run with the -R flag and the graceful restart yes directive present in the kernel protocols. Then, before upgrading, stop it using SIGKILL instead of SIGTERM to avoid a clean close of the BGP sessions.
Juniper JunOS
With JunOS, we only have to enable BGP LLGR for each family — assuming BFD is already configured:
# Enable BGP LLGR edit protocols bgp group peers family inet6 unicast set graceful-restart long-lived restarter stale-time 2m
Once a path is failing, the associated BGP session goes down and the BGP LLGR timer starts:
> show bgp neighbor 2001:db8:104::4 Peer: 2001:db8:104::4+179 AS 65000 Local: 2001:db8:104::1+57667 AS 65000 Group: peers Routing-Instance: master Forwarding routing-instance: master Type: Internal State: Connect Flags: <> Last State: Active Last Event: ConnectRetry Last Error: None Export: [ LOOPBACK NOTHING ] Options: <Preference HoldTime Ttl AddressFamily Multipath Refresh> Options: <BfdEnabled LLGR> Address families configured: inet6-unicast Holdtime: 6 Preference: 170 NLRI inet6-unicast: Number of flaps: 2 Last flap event: Restart Time until long-lived stale routes deleted: inet6-unicast 00:01:05 Table inet6.0 Bit: 20000 RIB State: BGP restart is complete Send state: not advertising Active prefixes: 0 Received prefixes: 1 Accepted prefixes: 1 Suppressed due to damping: 0 LLGR-stale prefixes: 1
The associated path is marked as stale and is therefore inactive as there are better paths available:
> show route 2001:db8:10::4 extensive […] BGP Preference: 170/-101 Source: 2001:db8:104::4 Next hop type: Router, Next hop index: 778 Next hop: 2001:db8:104::4 via em1.104, selected Protocol next hop: 2001:db8:104::4 Indirect next hop: 0xb1d27c0 1048578 INH Session ID: 0x15c State: <Int Ext> Inactive reason: LLGR stale Local AS: 65000 Peer AS: 65000 Age: 4 Metric2: 0 Communities: llgr-stale Accepted LongLivedStale Localpref: 100 Router ID: 1.0.0.4 […]
Have a look at the GitHub repository for the complete configurations as well as the expected outputs during normal operations. There is also a variant with the configurations of BIRD and JunOS when acting as a BGP route reflector. Now that FRR has BFD support, I hope it will get LLGR support as well.
This article originally appeared on Vincent Bernat’s blog.
Vincent Bernat is a network engineer at Blade.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.