
Several Content Delivery Networks (CDNs) use DNS to assign clients to distributed edge servers that are hosting content. Using DNS redirection offers a fine-grained and unobtrusive method of load balancing compared with alternatives like anycast and application-layer redirects.
As there is no direct communication between clients and authoritative DNS servers, CDNs map clients to edge servers as a function of the recursive resolver source IP address. However, the DNS ecosystem has developed into a complex component model including pools, that is, several resolvers operating in a single resolution.
Figure 1 demonstrates the notion of pools and how they might cause a problem in mapping a client to a nearby edge server. For instance, in the example below, the DNS client is assigned to edge server B because it is closer to the resolver that sent the query (R3). However, a better mapping option for the client is edge server A due to its proximity to the DNS client.
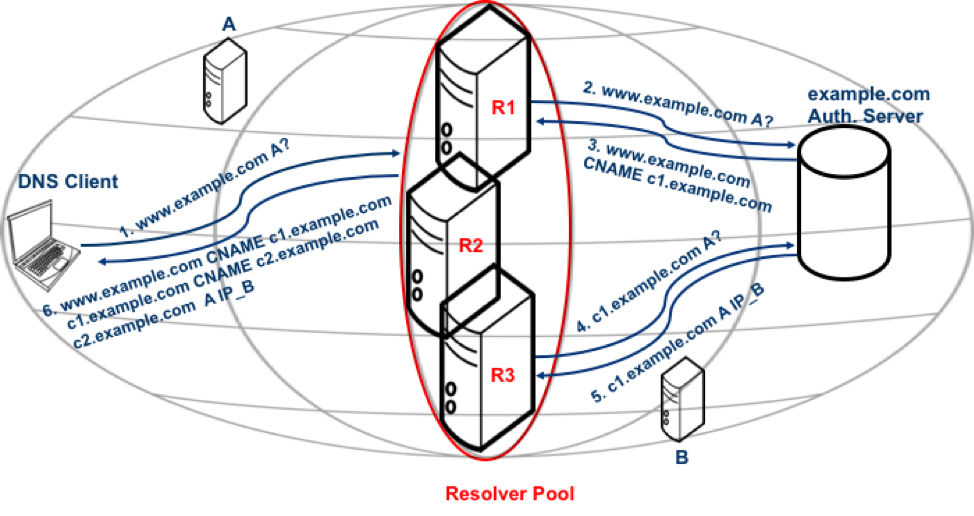 Figure 1 — The above diagram demonstrates the notion of resolver pools.
Figure 1 — The above diagram demonstrates the notion of resolver pools.
Pools are popular and come in all shapes and sizes
Using data we collected from the logs of the Akamai authoritative nameservers, we found that the use of small pools is common (as few as two IPs) while some very large pools, consisting of hundreds of IPs, exist.
We also studied the network properties of the resolver pools. We found that for 48% of the pools the covering IPv4 prefix length is shorter than 24-bits, showing that the pools are surprisingly distributed in IP space.
In IPv6, there are four common prefix lengths: 44, 60, 70, and 120-bits. Pools with prefix lengths of 44 and 60-bits are operated by Google, while the pools with a prefix length of 70-bits are operated by AT&T. The remaining are a scattering of other IPv6-enabled operators.
While the pools can be spread out in IP space, we observed that >99% of the pools contain IPs from, at most, two Autonomous Systems (ASes), suggesting that the pools are run by a single operator. Using the EdgeScape IP geolocation database, we noticed that 10% of the pools have large physical distances between the resolvers in the pool, greater than 160kms.
Turning to pool behaviour, we classify pools based on several patterns in the distribution of DNS queries between IPs in the pool. We identified the following behaviours and their frequencies.
- Uniform Load Balancing (14%). The pool spreads DNS queries evenly among all of the IPs. This behaviour suggests that the pool’s goal may be to minimize the load on each node within the pool.
- Off-Loading (26%). A single primary IP rarely assigns queries to other IPs in the pool, instead of handling most of the DNS traffic itself. We suspect this setup may be used to minimize the number of physical machines used during a steady state and only spin up additional nodes when needed.
- Uneven Distributions (23%). This category contains many unique behaviours, from uneven load splitting to having a combination of off-loading and uniform load balancing. The behaviours often appear to be operator specific. For instance, in a pool of three resolvers, the load may be unevenly distributed with percentages of 50%, 30%, and 20% respectively. Another example, in Level3’s AS, pools appear to be constructed by load balancing DNS queries between resolvers within the same IPv4 /24 prefix, and rarely off-loading DNS queries to resolvers in a second /24 prefix (roughly once out of every 500 queries).
We also found that 36% of the pools contain exactly two resolvers where one is IPv4 and the other is IPv6. These are very likely dual-stack resolvers that switch between interfaces.
Pools can benefit DNS resolution
In general, the concept of pools can be beneficial in improving the performance of DNS resolutions. For instance, using a number of collaborative resolvers that share a cache would result in better performance compared to using individual resolvers each with its own cache.
Moreover, the existence of pools aids in spreading the load over multiple resolvers instead of overloading a single resolver, especially in the presence of heterogeneous physical machines.
With all the potential benefits that pools could provide to both operators and clients, however, they can be problematic for CDNs that use recursive resolver network location as a proxy for end client network location when mapping the client to a nearby edge server, unless edns-client-subnet (ECS) is in use.
The above is a summary of a presentation given at the 2018 Passive and Active Measurement Conference (PAM 2018).
Contributors: Kyle Schomp
Rami Al-Dalky is a PhD candidate in the EECS department at Case Western Reserve University, Cleveland, USA. Kyle Schomp is a Performance Engineer at Akamai Technologies.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.