

This is the second post in a two-part series on the the need to monitor; and best practices for how to monitor more effectively within a budget.
I’ve spent a lot of time thinking about how to go about network monitoring in an efficient way. This is a method that I’ve implemented in a few different types of networks (ISPs, enterprises, and live events) and I feel it’s a very focused way of gaining insight from network metrics.
The key idea to keep in mind when building a network monitoring system is to remain focused on the business goals – what does my business/event/network aim to achieve?
For most ISPs, this will be a measure of quality or performance for their customers. It’s up to you as the system designer and business analyst to figure out what constitutes a good experience and design your monitoring to detect when that goal isn’t being met.
What metrics should you monitor?
Due to the limitations mentioned above, it’s not possible (in most cases) to collect every possible metric from every device, therefore a subset must be carefully selected.
Start with your business goals and decide which metrics are required to accurately measure the state of these goals. For example, say an ISP wishes to ensure that their subscribers get the best performance possible during peak usage time — this can be monitored by measuring the oversubscription ratio and uplink utilization of the terminating device. The required metrics to do this are the number of connected sessions, ifHCInOctets, ifHCOutOctets, ifHCSpeed of the uplink from the terminating device.
Assuming a known average subscriber speed we can calculate an oversubscription ratio and uplink utilization (in percentage to normalize for varying uplink speed). Repeat this process across all aspects of the network that might affect business goals to build a list of metrics and measurements.
What’s a suitable alerting system?
Now that you have calculated focused measurements, business rules can be applied to create low-noise, useful and actionable alerts. There is nothing worse as an operations engineer than being woken up in the middle of the night for something that can wait until the next day.
Build a policy that defines exactly how to classify alert priorities and then map an appropriate alerting method to each priority. For example, free disk space reaching more than 80% doesn’t always justify an SMS alert; it can easily be dealt with via a ticket or email to the appropriate team. Avoid too much noise from high-priority alerts and save instant communication methods for potential service impacting conditions requiring immediate action.
Look to continually improve your system
An effective monitoring system should be a key part of ensuring that your organization is taking part in continual improvement. Whenever an unexpected outage or event occurs, go through the usual root cause investigation and perform those few steps to isolate the symptoms that indicate the issue and define appropriate priority alerts to prevent reoccurrence.
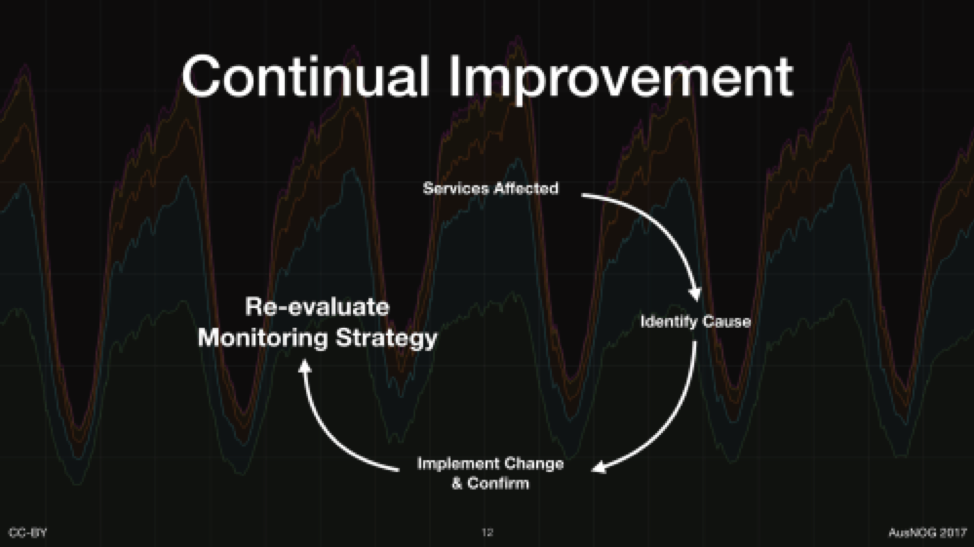
Figure 1: An effective monitoring system should be a key part of ensuring that your organization is taking part in continual improvement.
Use the technology available to you
Most organizations will already have some sort of monitoring application in place (be it commercial or otherwise) and most platforms have enough knobs and dials to be coerced into behaving as I’ve described above. Take a step back, do the high-level analysis of your business and network goals and then think about how you can use what you already have to structure an effective monitoring solution.
Design for resilience
As an operations engineer, I am well aware of the ‘flying blind’ feeling when monitoring stops working – this is not a comfortable feeling.
Design your monitoring system to be as resilient as possible against network and underlying system outages. Even if you can’t get to monitoring data during an outage, ensure that metrics are preserved for later root cause analysis.
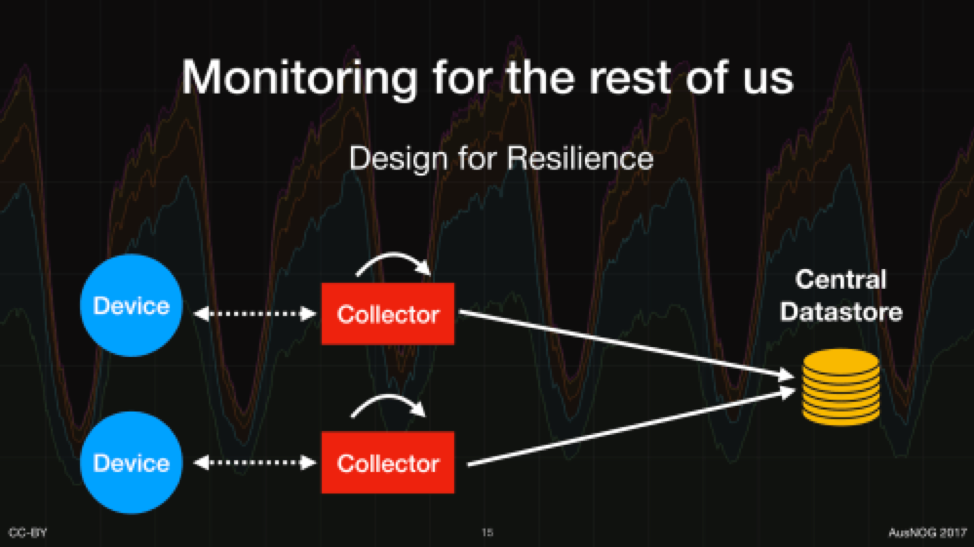
Figure 2: Design your monitoring system to be as resilient as possible against network and underlying system outages.
This can be achieved by decentralizing the collection mechanisms and placing collectors as close as possible to the data sources – this reduces the number of dependent systems and devices that could affect the metric collection process.
Storing information centrally is key to doing effective analysis and thus a means for bringing decentralized collector data into a central database is important.
Queues and buffers are an excellent way to ensure persistence if the connection between a collector and central store are disrupted – many software platforms have support for Apache MQ, Kafka or other internal buffering mechanisms.
As mentioned previously, limitations on current software and hardware prevent operators from collecting every single statistic possible, however, if you can store more than the minimum, then do so for future analysis. Ensure that any raw metrics used for further calculations are also stored as this can be key in doing historical analysis on new trends.
Note: meta monitoring is important – ensure your monitoring system is operating as expected by ensuring there is current data, services are in the correct state and network connections exist on expected ports. There is nothing worse than having a quiet day in operations to realise that monitoring hasn’t been working correctly.
I am really passionate about monitoring and I intend to go more into the ‘How’ in future posts. In the meantime let me know your thoughts and hacks on network monitoring in the comments below.
This is an adapted version of a post that was published on Tim Raphael’s personal blog.
Tim Raphael is a Peering Engineer at Internet Association of Australia Inc.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.