

The Domain Name System (DNS) is a cornerstone of the Internet. By systematically measuring this protocol, we can improve our understanding of the Internet, find vulnerabilities, and provide data for informed decision-making. Yet, the ‘DNS Camel’ is a notoriously difficult protocol to measure efficiently due to its sheer size, complexity, and abundance of corner cases.
In a recent paper, my fellow Max Planck Institute for Informatics researchers and I presented yodns, a tool that collects extensive DNS data from all zones and nameservers that are potentially involved in the resolution of a name at scale. We have used this to collect data from 812M domain names and assess how certain optimizations affect data completeness and measurement results.
In this post, I want to highlight the challenges we faced during DNS data collection and discuss some of the tradeoff decisions that DNS measurement practitioners regularly have to make. Finally, we’ll also examine some instances where our collected data has proven to be useful.
Background
DNS is organized into a hierarchy of zones, with different nameservers (NSs) being responsible for different zones. To resolve a name, resolvers need to find a path through this hierarchy by sending a sequence of queries to different nameservers. However, because every zone must have multiple nameservers (RFC 1034) (that, again, can have multiple IP addresses), there is no single way to resolve a name.
In a perfect world, all of these potential resolutions would lead us to the same (or at least ‘correct’) result. But in reality, this is surprisingly often not the case, for example, when the nameservers of a zone are out-of-sync with one another or with their parent zone’s servers (delegation inconsistency). Intentional uses exist, for example, for A/AAAA records, where perceived inconsistency can be caused by load balancing mechanisms.
Many misconfigurations can cause problems, even if they only appear on a single resolution path. A single, misbehaving name server may leak private keys in TXT records, send clients off to stale or malicious IPs, or even make zones susceptible to hijacking attacks. Moreover, when not all resolution paths are affected, these issues may appear only for subsets of clients, making them hard to find and fix. But how prevalent are such issues? In order to find an answer, we need to collect extensive data, covering all potentially involved nameservers and zones.
Collecting all resolutions— how hard can it be?
The minimal case: Five queries
Let’s use an example to show how the complexity of the DNS protocol affects the number of queries needed to capture all potential resolutions of a name. For starters, we’ll try to resolve the A record of example.com. (the actual domain). This can be achieved with just five queries:
1. NS com. @a.root-servers.net.
2. NS example.com @a.gtld-servers.net.
3. NS net. @a.root-servers.net.
4. NS iana-servers.net. @a.gtld-servers.net.
5. A example.com @a.iana-servers.net.First, we ask a root server (in this case, a-root) for a referral to the .com zone.
Conveniently, it will not only tell us that a.gtld-servers.com is authoritative for com, but also include its IP address(es) in the response in the so-called glue records.
Next, we ask for a referral to example.com, but this time the response will not contain glue, so we will have to resolve the IP of a.iana-servers.net ourselves. You may have noticed that we do not ask for the A record of a.iana-servers.net. That is not needed here, as we can take it from the glue in the fourth response.
Of course, the number of queries used by an actual resolver may be larger and will depend on various factors, including the software, the settings, and which name server the software decides to use.
All cases: At least 1,988 queries?
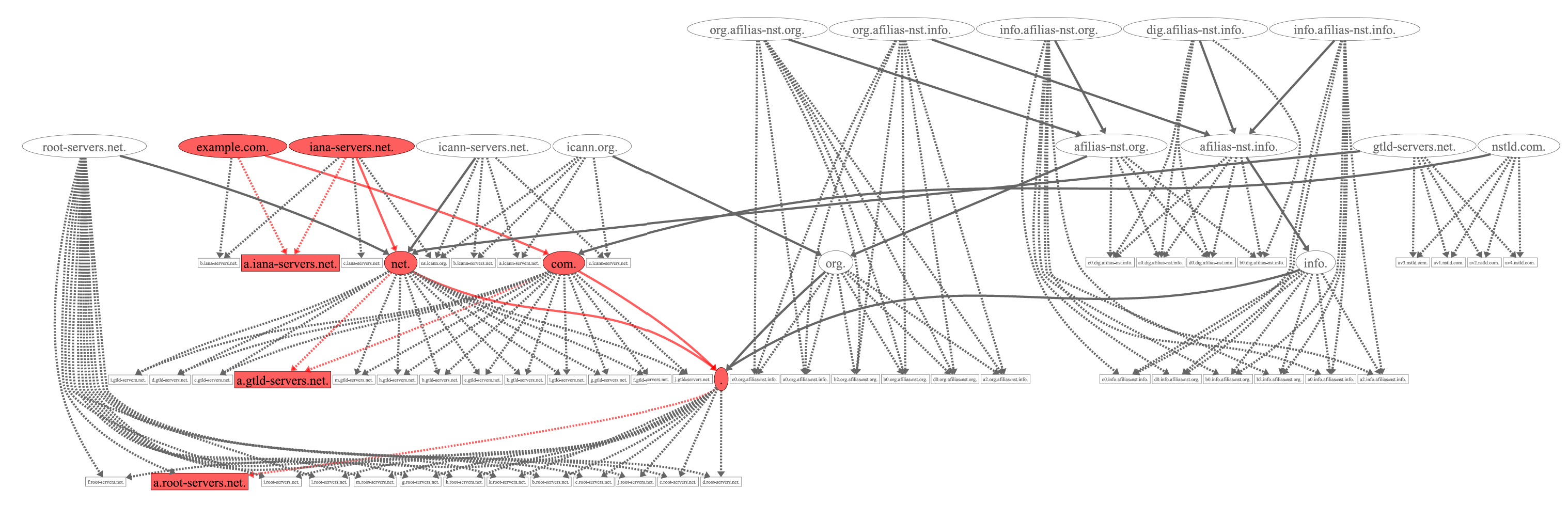
Now, we have seen the minimal resolution for example.com. But for our study, we wanted to have all possible resolutions. Figure 1 shows what happens if we visualize all nameservers and zones that can potentially be involved in the resolution of example.com. We see that the space of possible resolutions is an order of magnitude larger than the minimal resolution (red). In order to obtain a complete, or rather, a more complete, picture, we need to resolve this entire graph. But how many queries would that take?
We can calculate the minimum number of queries for the full resolution of example.com as follows:
- For all zones, ask all authoritative NSs for the zones’ NS records.
- For all zones, ask all of their parents’ authoritative NSs for referrals to the zone.
- For all NS names, ask all NS authoritative for them for the A/AAAA records.
For example, the zone icann-servers.net has four authoritative NSs with eight IP addresses in total. Thus, we need to ask for NS icann-servers.net eight times. We need to ask for a referral to icann-servers.net at all 26 nameserver addresses of the net-zone. Finally, there are three NS names in the zone, namely {a,b,c}.icann-servers.net. Asking the four authoritative NSs (eight IP addresses) for six records (3xA and 3xAAAA) requires 48 queries. Summing the queries like this for each zone from Figure 1 leaves us with 1,988 queries, almost 400 times more than the minimal resolution we have seen before.
But wait, there’s more…
Unfortunately, it does not stop there. DNS has many parameters, and for a truly exhaustive study, we’d need to explore them all, resulting in a combinatorial explosion of the query volume. Because such a measurement is neither feasible nor ethical, we have to employ optimizations. Let’s quickly outline the most important parameters and how we handled them in our measurement.
IP version
With the increase of IPv6 deployment, the number of IPv6-related resource records in DNS has increased, and IPv6-only resolution is feasible for many domains. Our measurement is full dual-stack, in order to reason about IPv4-only, IPv6-only, as well as dual-stack resolution.
Transport
Authoritative nameservers must support queries over TCP. We use TCP as a fallback if the response does not fit in the announced EDNS-buffer size. This is necessary, as not using TCP may lead to considerable biases, especially in conjunction with DNSSEC, which increases response size.
DNSSEC
Requesting DNSSEC records (setting DO=1) can drastically change response sizes and lead to response truncation. Since we want these records for our study, we request DNSSEC by default. However, we retry queries without EDNS0 on FormErr responses.
QNAME minimization
QNAME minimization is a privacy-preserving way of sending queries. For us, it allows discovering zone cuts, even when parent and child zones are hosted on the same server. However, it has been shown that nameservers may respond inconsistently to minimized queries vs when the FQDN is included.
Vantage points
DNS responses differ by vantage point, for example, due to load balancing or anycast. To capture the influence of a client’s location, we’d need to repeat the data collection from different vantage points. But because the query volume scales linearly with the number of vantage points, it would quickly render our measurement infeasible. Therefore, we use a single vantage point in Germany. Consequently, we cannot quantify the influence of geographical location.
Implementation challenges
Having selected a set of parameters for our study design, the next step is to actually collect the data for 812M domains, which we obtain from zone files, certificate transparency logs, top lists and open data efforts. But even with the chosen optimizations, this data collection effort requires us to send ~90B queries in a way that does not put an undue burden on other people’s infrastructure. In the remainder of this post, I want to discuss the engineering challenges that come with this and how we managed them.
Scalability and rate-limiting bottlenecks
Resolving several domains in parallel is a different use case from ‘standard’ resolution, as we are not so much interested in individual end-to-end resolution times, but rather in the overall throughput of the system. This allows for different optimizations.
The fundamental scalability problem is that some nameservers are responsible for a lot of domains. But because we send queries to every IP address of every name server in each zone, there is no (client-side) load-balancing between these servers anymore. This creates activity hotspots where we have to push a lot of queries to some servers. At the same time, we want to respect rate limits to not put an undue burden on these servers.
The solution to this problem is asynchronous resolution. We do not need to wait for all responses from one level before proceeding with resolving the next level. However, since we want to explore all resolution paths, we need to be able to ‘go back in time’ and enqueue more requests, for example, when additional NSs / IPs are discovered late. Therefore, yodns’ callback-based architecture and resolution algorithm is a consequence of the required scalability while also having to adhere to rate limits.
While we have observed considerable performance gains after switching to this architecture, it does not fully solve our problem. In the most extreme case, the .com and .net servers have to answer referral queries for almost 200M second-level domains. With 26 IP Addresses over 13 servers, this would mean pushing over 5B queries to these servers. Therefore, we use a trust-but-verify approach, where we only ask a single nameserver (over IPv4 and IPv6) for selected zones but do a complete scan for a random sample of 1M domains to verify that responses can be expected to be consistent.
Improving cache locality
The order of the target list greatly impacts performance and cacheability. If domain names that share a common suffix are scanned in temporal proximity on the same machine, more queries can be answered from the local cache. However, when too many related names are grouped together, this creates activity hotspots, putting strain on authoritative NSs.
To strike a balance between cacheability and randomization, we first group our input targets by their first non-public suffix, as determined using Mozilla’s public suffix list. For our input domains, 99.71% of these groups have 20 or fewer domains, whereas the remaining 0.29% contain 27.78% of all domains, potentially causing activity hotspots for shared nameservers. Thus, we split those large groups into subgroups of 20 and distribute them randomly within the target list.
In test runs, this strategy resulted in a 280% speed up and reduced the actual queries by 50% compared to a fully randomized target list, just by cleverly reordering the target list.
RFC (non)compliance and misconfiguration
Measurement tools should be RFC-compliant to avoid accidentally causing harm, such as crashing servers by sending malformed packets. However, as Internet measurement researchers, misconfiguration and non-compliance are often exactly what we are interested in. Therefore, we need to handle them, record them, and collect as much data around them as we can for later analysis. However, the handling of misconfigurations is hard, as one can never know what to expect. The only way around this is to try to avoid assumptions about the behaviour of remote servers as far as possible.
To account for remote servers deviating from DNS best practices, yodns is resilient to various non-standard behaviours. For example, it accepts CNAMEs at apex and NS records pointing at CNAMEs, as well as multiple CNAMEs at the same name. It chases and resolves these records, postponing the decision about their ‘validity’ to the data analysis steps. Similarly, it allows for out-of-zone glue and responses with invalid or incomplete flags, like lacking the AA bit.
To make this more specific, I’d like to give one example of a technically almost correctly configured domain that has caused us some headaches. While the domain has four authoritative NSs listed in its parent zone, the zone apex contains 300 in-domain authoritative NSs (each having an IPv4 and IPv6 address). The responses are far too large for a UDP packet, so we fall back to TCP. The fact that the NSs are in-domain implies sending queries for 300 names (and five record types) to 600 addresses. This leads to notable spikes in memory usage, as just the raw message bytes consume 18GB of memory. And if anyone has an idea which (il)legitimate use-cases for such a configuration exist, I would be happy to hear about them!
Data volume vs usability
Our scan sent 89B DNS queries over the course of 40 days. In theory, a compressed packet capture of these messages would contain enough information for all purposes.
In practice, to infer what a resolver would have seen at a certain time, this would require reconstructing the internal state of the software from the captures — a process that is very hard and prone to errors. Therefore, we implemented a binary format that captures all messages involved in a resolution (including cache hits) together with metadata that shows the resolver’s internal state. This greatly enhances usability, but also increases the data sizes.
Reusability
Use-cases for DNS measurement are diverse and hard to predict, making it hard to design the right extension points in the software. To account for this, we have separated DNS client functionality from the resolution logic, so even completely custom resolution logic can still benefit from asynchronicity, port reuse and rate-limiting. Furthermore, the tool is available under a permissive MIT license.
Conclusion
We have seen that following all possible resolution paths can require multiple orders of magnitude more queries than a ‘standard’ resolution. Nevertheless, such measurements can be made feasible by careful design choices and accepting certain limitations (for example, in the number of vantage points).
The collected data can provide rich insights into the DNS and has been proven useful already on several occasions. To name some examples:
- Categorizing and quantifying CDS/CDNSKEY inconsistencies among nameservers has proven useful in the context of RFC 9615 (see this post also), which requires retrieving CDS/CDNSKEY from all authoritative nameservers of a zone in order to avoid zone takeovers.
- In our recent paper, we used this data to quantify the effects that not exploring all resolution paths can have on DNS measurement studies. While we find many research questions eligible for optimizations, we also find inconsistencies that can have severe effects deeper in the tree, such as when measuring zones below the second level.
- The collected data provides a comprehensive picture of a sizable part of the DNS (as seen from a specific vantage point). Future studies can use this data to reason about new developments or changes.
Where can I find more information?
If you found this interesting, check out our paper, tool, and dataset.
Florian Steurer is a PhD student at the Max Planck Institute for Informatics. His research focuses on measuring DNS and resilience.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.