

Recently, I took a good look at the Babel protocol. I found a set of features there that I really appreciated. The first was a latency-aware routing protocol — this is useful for mesh (wireless) networks but it is also a good fit for IPng’s use case, notably because it makes use of carrier Ethernet which, if any link in the underlying MPLS network fails, will automatically re-route but sometimes with much higher latency. In these cases, Babel can re-converge on its own to a topology that has the lowest end-to-end latency.
But a second really cool find is that Babel can use IPv6 next hops for IPv4 destinations — which is super useful because it will allow me to retire all of the IPv4 /31 point-to-point networks between my routers. AS8298 has about half of a /24 tied up in these otherwise pointless (pun intended) transit networks.
In the same week, my buddy Benoit asked a question about OSPFv3 on the Bird users mailing list, which may or may not have been because I had been messing around with Babel using only IPv4 loopback interfaces. And just a few weeks before that, the incomparable Nico from Ungleich had a very similar question.
These folk have something in common — we’re all trying to conserve IPv4 addresses!
OSPFv3 with IPv4
Nico’s thread referenced RFC 5838, which defines support for multiple address families in OSPFv3. It does this by mapping a given address family to a specific instance of OSPFv3 using the instance id and adding a new option to the options field that tells neighbors that multiple address families are supported in this instance (and thus, that the neighbor should not assume all link state advertisements are IPv6-only).
This way, multiple instances can run on the same router, and they will only form adjacencies with neighbors that are operating in the same address family. This in itself doesn’t change much. Rather than using IPv4 multicast in the hello’s while forming adjacencies, OSPFv3 will use IPv6 link-local addresses for them.
RFC 5838, Section 2.5 says:
Although IPv6 link local addresses could be used as next hops for IPv4 address families, it is desirable to have IPv4 next-hop addresses. [ … ] In order to achieve this, the link’s IPv4 address will be advertised in the “link local address” field of the IPv4 instance’s Link-LSA. This address is placed in the first 32 bits of the “link local address” field and is used for IPv4 next-hop calculations. The remaining bits MUST be set to zero.
RFC 5838
First, my hopes are raised by saying IPv6 link-local addresses could be used as the next hops (just like Babel, yaay!), but then it goes on to say the link local address field will be overridden with an IPv4 address in the top 32 bits. That’s … gross. I understand why this was done; it allows for a minimal deviation of the OSPFv3 protocol, but this unfortunate choice precludes the ability for IPv6 nexthops to be used. Crap on a cracker!
OSPFv3 with IPv4
But wait, not all is lost! Remember in my VPP Babel article I mentioned that the Vector Packet Processor (VPP) has this ability to run unnumbered interfaces? To recap, this is a configuration where a primary interface, typically a loopback, will have an IPv4 and IPv6 address, say 192.168.10.2/32 and 2001:678:d78:200::2/128 and other interfaces will borrow from that. That will allow for the IPv4 address to be present on multiple interfaces, like so:
pim@vpp0-2:~$ ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
loop0 UNKNOWN 192.168.10.2/32 2001:678:d78:200::2/128 fe80::dcad:ff:fe00:0/64
e0 UP 192.168.10.2/32 2001:678:d78:200::2/128 fe80::5054:ff:fef0:1120/64
e1 UP 192.168.10.2/32 2001:678:d78:200::2/128 fe80::5054:ff:fef0:1121/64
VPP changes
Historically in VPP, broadcast mediums like Ethernet will respond to Address Resolution Protocol (ARP) requests only if the requestor is in the same subnet. With these point-to-point interfaces, the remote will never be in the same subnet, because we’re using /32 addresses here! VPP logs these as invalid ARP requests. With a small change though, I can make VPP tolerant of this scenario, and the consensus in the VPP community is that this is OK.
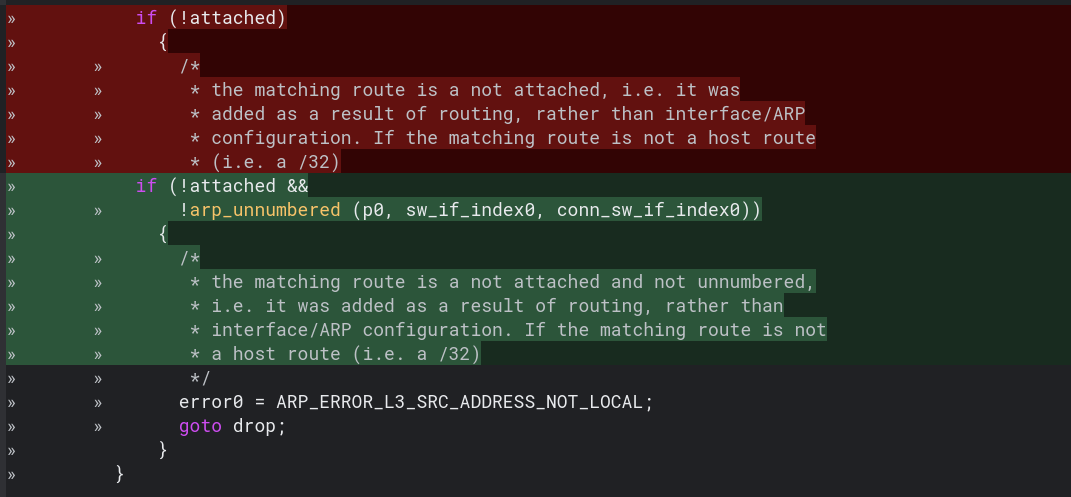
Check out 40482 for the full change, but in a nutshell, just before deciding to return an error because the requesting source address is not directly connected (called an attached route in VPP), I’ll change the condition to allow for it, if and only if the ARP request comes from an unnumbered interface.
I think this is a good direction, if only because most other popular implementations (including Linux, FreeBSD, Cisco IOS/XR and Juniper) will answer ARP requests that are onlink but not directly connected, in the same way.
Bird2 changes
Meanwhile, in the Bird community, we were thinking about solving this problem differently. Babel allows a feature to use IPv6 transit networks with IPv4 destinations, by specifying an option called extended next hop. With this option, Babel will set a next hop across address families. It may sound freaky at first, but it’s not too strange when you think about it. Take a look at my explanation in the Babel article on how IPv6 neighbor discovery can take the place of IPv4 ARP resolution to figure out the Ethernet next hop.
So our initial take was — why don’t we do that with OSPFv3 as well? We thought of a trick to get that Link LSA hack from RFC 5838 removed. What if Bird2, upon setting the extended next hop feature on an interface, would simply put the IPv6 address back like it was, rather than overwriting it with the IPv4 address? That way, we’d just learn routes to IPv4 destinations with next hops on IPv6 linklocal addresses. It would break compatibility with other vendors, but seeing as it is an optional feature that defaults to off, perhaps it is a reasonable compromise…
Ondrej from the Bird2 team started to work on it but came back a few days later with a different solution, which is quite clever. Any IPv4 router needs at least one IPv4 address anyway, to be able to send ICMP messages, so there is no need to put IPv4 addresses on links. Ondrej’s theory corroborates my previous comments on Babel’s IPv4-less routing:
I’ve learned so far that I (a) MAY use IPv6 link-local networks in order to forward IPv4 packets, as I can use IPv6 NDP to find the link-layer next hop; and (b) each router SHOULD be able to originate ICMPv4 packets, therefore it needs at least one IPv4 address.
These two claims mean that I need at most one IPv4 address on each router.
Ondrej’s proposal for Bird2 will, when OSPFv3 is used with IPv4 destinations, keep the RFC 5838 behaviour and try to find a working IPv4 address to put in the Link LSA:

He adds a function update_loopback_addr(), which scans all interfaces for an IPv4 address, and if there are multiple, preferred host addresses, then addresses from OSPF stub interfaces, and finally just any old IPv4 address. Now that IPv4 address can be simply used to put in the Link LSA. Slick!
His change also removes the next-hop-in-address-range check for OSPFv3 when using IPv4, and automatically adds onlink flag to such routes, which newly accepts next hops that are not directly connected:

I realized when reading the code that this change paired with the Gerrit change are perfect partners:
- Ondrej’s change will make the Link LSA be onlink, which is a way to describe that the next hop is not directly connected, in other words next hop
192.168.10.3/32, while the router itself is192.168.10.2/32. - My change will make VPP answer for ARP requests in such a scenario where the router with an unnumbered interface with
192.168.10.3/32will respond to a request from the not directly connected onlink peer at192.168.10.2.
Tying it together
With all of that, I am ready to demonstrate two working solutions now. I first compile Bird2 with Ondrej’s commit. Then, I compile VPP with my pending Gerrit. Finally, to demonstrate how update_loopback_addr() might work, I compile lcpng with my previous commit, which allows me to inhibit copying forward addresses from VPP to Linux when using unnumbered interfaces.
I take an IPng lab instance out for a spin with this updated Bird2 and VPP+lcpng environment:

Solution 1: Somewhat unnumbered
I configure an otherwise empty VPP data plane as follows:
vpp0-3# lcp lcp-sync on
vpp0-3# lcp lcp-sync-unnumbered on
vpp0-3# create loopback interface instance 0
vpp0-3# set interface state loop0 up
vpp0-3# set interface ip address loop0 192.168.10.3/32
vpp0-3# set interface ip address loop0 2001:678:d78:200::3/128
vpp0-3# set interface mtu 9000 GigabitEthernet10/0/0
vpp0-3# set interface mtu packet 9000 GigabitEthernet10/0/0
vpp0-3# set interface unnumbered GigabitEthernet10/0/0 use loop0
vpp0-3# set interface state GigabitEthernet10/0/0 up
vpp0-3# lcp create loop0 host-if loop0
vpp0-3# lcp create GigabitEthernet10/0/0 host-if e0
Which yields the following configuration:
pim@vpp0-3:~$ ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
loop0 UNKNOWN 192.168.10.3/32 2001:678:d78:200::3/128 fe80::dcad:ff:fe00:0/64
e0 UP 192.168.10.3/32 2001:678:d78:200::3/128 fe80::5054:ff:fef0:1130/64
pim@vpp0-3:~$ ip route get 182.168.10.2
RTNETLINK answers: Network is unreachableI can see that VPP copied forward the IPv4/IPv6 addresses to interface e0, and because there’s no routing protocol running yet, the neighbor router vpp0-2 is unreachable. Let me fix that, next. I start Bird2 in the VPP data plane network namespace, and configure it as follows:
router id 192.168.10.3;
protocol device { scan time 30; }
protocol direct { ipv4; ipv6; check link yes; }
protocol kernel kernel4 {
ipv4 { import none; export where source != RTS_DEVICE; };
learn off; scan time 300;
}
protocol kernel kernel6 {
ipv6 { import none; export where source != RTS_DEVICE; };
learn off; scan time 300;
}
protocol bfd bfd1 {
interface "e*" {
interval 100 ms;
multiplier 20;
};
}
protocol ospf v3 ospf4 {
ipv4 { export all; import where (net ~ [ 192.168.10.0/24+, 0.0.0.0/0 ]); };
area 0 {
interface "loop0" { stub yes; };
interface "e0" { type pointopoint; cost 5; bfd on; };
};
}
protocol ospf v3 ospf6 {
ipv6 { export all; import where (net ~ [ 2001:678:d78:200::/56, ::/0 ]); };
area 0 {
interface "loop0" { stub yes; };
interface "e0" { type pointopoint; cost 5; bfd on; };
};
}This minimal Bird2 configuration will configure the main protocols device, direct, and two kernel protocols kernel4 and kernel6, which are instructed to export learned routes from the kernel for all but directly connected routes (because the Linux kernel and VPP already have these when an interface is brought up, this avoids duplicate connected route entries).
If you haven’t come across it yet, Bidirectional Forwarding Detection (BFD) is a protocol that repeatedly sends UDP packets between routers, to be able to detect if the forwarding is interrupted even if the interface link stays up. It’s described in detail in RFC 5880, and I use it at IPng Networks all over the place.
Then I’ll configure two OSPF protocols, one for IPv4 called ospf4 and another for IPv6 called ospf6. It’s easy to overlook, but while usually the IPv4 protocol is OSPFv2 and the IPv6 protocol is OSPFv3, here both are using OSPFv3! I’ll instruct Bird2 to erect a BFD session for any neighbor it establishes an adjacency with. If at any point the BFD session times out (currently at 20x100ms or 2.0s), OSPF will tear down the adjacency.
The OSPFv3 protocols each define one channel, in which I allow Bird2 to export anything, but import only those routes that are in the LAB IPv4 (192.168.10.0/24) and IPv6 (2001:687:d78:200::/56), and I’ll also allow a default to be learned over OSPF for both address families. That’ll come in handy later.
I start up Bird2 on the rightmost two routers in the lab (vpp0-3 and vpp0-2). Looking at vpp0-3, Bird2 starts sending IPv6 hello packets on interface e0, and pretty quickly finds not one but two neighbors:
pim@vpp0-3:~$ birdc show ospf neighbors
BIRD v2.15.1-4-g280daed5-x ready.
ospf4:
Router ID Pri State DTime Interface Router IP
192.168.10.2 1 Full/PtP 30.870 e0 fe80::5054:ff:fef0:1121
ospf6:
Router ID Pri State DTime Interface Router IP
192.168.10.2 1 Full/PtP 30.870 e0 fe80::5054:ff:fef0:1121Bird2 can sort out which is which on account of the ’normal’ IPv6 OSPFv3 having an instance id value of 0 (IPv6 Unicast), and the IPv4 OSPFv3 having an instance id of 64 (IPv4 Unicast). Further, the IPv4 variant will set the AF-bit in the OSPFv3 options, so the peer will know it supports using the Link LSA to model IPv4 nexthops rather than IPv6 nexthops.
Indeed, routes are quickly learned:
pim@vpp0-3:~$ birdc show route table master4
BIRD v2.15.1-4-g280daed5-x ready.
Table master4:
192.168.10.3/32 unicast [direct1 13:02:56.883] * (240)
dev loop0
unicast [direct1 13:02:56.883] (240)
dev e0
unicast [ospf4 13:02:56.980] I (150/0) [192.168.10.3]
dev loop0
dev e0
192.168.10.2/32 unicast [ospf4 13:03:04.980] * I (150/5) [192.168.10.2]
via 192.168.10.2 on e0 onlinkThey are quickly propagated both to the Linux kernel and by means of Netlink into the Linux ControlPlane plugin in VPP, which programs it into VPP’s Forwarding Information Base (FIB):
pim@vpp0-3:~$ ip ro
192.168.10.2 via 192.168.10.2 dev e0 proto bird metric 32 onlink
pim@vpp0-3:~$ vppctl show ip fib 192.168.10.2
ipv4-VRF:0, fib_index:0, flow hash:[src dst sport dport proto flowlabel ] epoch:0 flags:none locks:[adjacency:1, default-route:1, lcp-rt:1, ]
192.168.10.2/32 fib:0 index:23 locks:3
lcp-rt-dynamic refs:1 src-flags:added,contributing,active,
path-list:[40] locks:2 flags:shared, uPRF-list:22 len:1 itfs:[1, ]
path:[53] pl-index:40 ip4 weight=1 pref=32 attached-nexthop: oper-flags:resolved,
192.168.10.2 GigabitEthernet10/0/0
[@0]: ipv4 via 192.168.10.2 GigabitEthernet10/0/0: mtu:9000 next:6 flags:[] 525400f01121525400f011300800
adjacency refs:1 entry-flags:attached, src-flags:added, cover:-1
path-list:[43] locks:1 uPRF-list:24 len:1 itfs:[1, ]
path:[56] pl-index:43 ip4 weight=1 pref=0 attached-nexthop: oper-flags:resolved,
192.168.10.2 GigabitEthernet10/0/0
[@0]: ipv4 via 192.168.10.2 GigabitEthernet10/0/0: mtu:9000 next:6 flags:[] 525400f01121525400f011300800
Extensions:
path:56
forwarding: unicast-ip4-chain
[@0]: dpo-load-balance: [proto:ip4 index:28 buckets:1 uRPF:22 to:[0:0]]
[0] [@5]: ipv4 via 192.168.10.2 GigabitEthernet10/0/0: mtu:9000 next:6 flags:[] 525400f01121525400f011300800The neighbor is reachable, over IPv6 (which is nothing special), but also over IPv4:
pim@vpp0-3:~$ ping -c5 2001:678:d78:200::2
PING 2001:678:d78:200::2(2001:678:d78:200::2) 56 data bytes
64 bytes from 2001:678:d78:200::2: icmp_seq=1 ttl=64 time=2.16 ms
64 bytes from 2001:678:d78:200::2: icmp_seq=2 ttl=64 time=3.69 ms
64 bytes from 2001:678:d78:200::2: icmp_seq=3 ttl=64 time=2.66 ms
64 bytes from 2001:678:d78:200::2: icmp_seq=4 ttl=64 time=2.30 ms
64 bytes from 2001:678:d78:200::2: icmp_seq=5 ttl=64 time=2.92 ms
--- 2001:678:d78:200::2 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4006ms
rtt min/avg/max/mdev = 2.164/2.747/3.687/0.540 ms
pim@vpp0-3:~$ ping -c5 192.168.10.2
PING 192.168.10.2 (192.168.10.2) 56(84) bytes of data.
64 bytes from 192.168.10.2: icmp_seq=1 ttl=64 time=3.58 ms
64 bytes from 192.168.10.2: icmp_seq=2 ttl=64 time=3.40 ms
64 bytes from 192.168.10.2: icmp_seq=3 ttl=64 time=3.28 ms
64 bytes from 192.168.10.2: icmp_seq=4 ttl=64 time=3.32 ms
64 bytes from 192.168.10.2: icmp_seq=5 ttl=64 time=3.29 ms
--- 192.168.10.2 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4007ms
rtt min/avg/max/mdev = 3.283/3.374/3.577/0.109 ms☑ OSPFv3 with IPv4/IPv6 on-link next hops works!
Solution 2: Truly unnumbered
However, Ondrej’s patch does something in addition to this. I repeat the same setup, except now I set one additional feature when starting up VPP: lcp lcp-sync-unnumbered off
What happens next is that VPP’s data plane looks subtly different. It has created an unnumbered interface keyed from loop0, but it doesn’t propagate the addresses to Linux.
pim@vpp0-3:~$ ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
loop0 UNKNOWN 192.168.10.3/32 2001:678:d78:200::3/128 fe80::dcad:ff:fe00:0/64
e0 UP fe80::5054:ff:fef0:1130/64
With e0 only having a linklocal address, Bird2 can still form an adjacency with its neighbor vpp0-2, because adjacencies in OSPFv3 are formed using IPv6 only. However, the clever trick to walk the list of interfaces update_loopback_addr() will be able to find a usable IPv4 address and use that to put in the Link LSA using RFC 5838. In this case, it finds 192.168.10.3 from interface loop0 so it’ll use that to signal the next hop for LSAs that it sends.
Now I start the same VPP and Bird2 configuration on all four VPP routers, but on vpp0-0 I’ll add a static route out of the LAB to the Internet:
protocol static static4 {
ipv4 { export all; };
route 0.0.0.0/0 via 192.168.10.4;
}
protocol static static6 {
ipv6 { export all; };
route ::/0 via 2001:678:d78:201::ffff;
}These two default routes from vpp0-0 quickly propagate through the network, where vpp0-3 ultimately sees this:
pim@vpp0-3:~$ ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
loop0 UNKNOWN 192.168.10.3/32 2001:678:d78:200::3/128 fe80::dcad:ff:fe00:0/64
e0 UP fe80::5054:ff:fef0:1130/64
pim@vpp0-3:~$ ip ro
default via 192.168.10.2 dev e0 proto bird metric 32 onlink
192.168.10.0 via 192.168.10.2 dev e0 proto bird metric 32 onlink
192.168.10.1 via 192.168.10.2 dev e0 proto bird metric 32 onlink
192.168.10.2 via 192.168.10.2 dev e0 proto bird metric 32 onlink
192.168.10.4/31 via 192.168.10.2 dev e0 proto bird metric 32 onlink
pim@vpp0-3:~$ ip -6 ro
2001:678:d78:200:: via fe80::5054:ff:fef0:1121 dev e0 proto bird metric 32 pref medium
2001:678:d78:200::1 via fe80::5054:ff:fef0:1121 dev e0 proto bird metric 32 pref medium
2001:678:d78:200::2 via fe80::5054:ff:fef0:1121 dev e0 proto bird metric 32 pref medium
2001:678:d78:200::3 dev loop0 proto kernel metric 256 pref medium
2001:678:d78:201::/112 via fe80::5054:ff:fef0:1121 dev e0 proto bird metric 32 pref medium
fe80::/64 dev loop0 proto kernel metric 256 pref medium
fe80::/64 dev e0 proto kernel metric 256 pref medium
default via fe80::5054:ff:fef0:1121 dev e0 proto bird metric 32 pref medium☑ OSPFv3 with loopback-only, unnumbered IPv4/IPv6 interfaces works!
Results
I thought I’d record a little asciinema gif that shows the end-to-end configuration, starting from an empty data plane and Bird2 configuration. I’ll show Solution 2, that is, the solution that doesn’t copy the unnumbered interfaces in VPP to Linux.
Ready? Here I go!
To unnumbered or not to unnumbered?
I’m torn between Solution 1 and Solution 2. While on the one hand, setting the unnumbered interface would be best reflected in Linux, it is not without problems. If the operator subsequently tries to remove one of the addresses on e0 or e1, which will yield a desync between Linux and VPP (Linux will have removed the address, but VPP will still be unnumbered). On the other hand, tricking Linux (and the operator) to believe there isn’t an IPv4 (and IPv6) address configured on the interface, is also not great.
Of the two approaches, I think I prefer Solution 2 (configuring the Linux CP plugin to not sync unnumbered addresses) because it minimizes the chance of operator error. If you’re reading this and have an Opinion™, would you please let me know?
Pim van Pelt (PBVP1-RIPE) began his career as a network engineer in the Netherlands, where he worked for Intouch, Freeler, and BIT. He helped raise awareness for IPv6, for example by launching it at AMS-IX back in 2001. He also operated SixXS, a global IPv6 tunnel broker, from 2001 through to its sunset in 2017. Since 2006, Pim has worked as a Distinguished SRE at Google in Zurich, Switzerland.
Originally posted on IPng Networks blog.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.