

This article was originally written as a private resource — it is definitely not one of my comprehensive guides — but I felt that it would benefit the networking community. My co-author has chosen to remain anonymous.
This article intends to share some insight into iptables’ raw vs filter performance and potentially help you make a more efficient decision.
This post is not an assessment of the most efficient packet processing technologies such as XDP or DPDK; it strictly pertains to legacy iptables. However, the concepts here are reasonably applicable to nftables, which supports various priorities within hook.
In a discussion with my friend, a question came up about the best place in Netfilter / legacy iptables to filter out spurious traffic where the destination is any of the local addresses on a router (or host). To be specific, the use case is a Linux device acting as a router, with certain services running locally on it. We want to use iptables to prevent unauthorized external parties from connecting to services such as BGP, SSH, and so on.
The hypothesis
I maintained it was always preferable to have the rules to drop such traffic in the pre-routing chain of the raw table, ensuring it happens before the route lookup. This is especially so in the case of a router with a full routing table of about 1M IPv4 routes, where the route lookup becomes a very expensive operation.
It made perfect sense to my friend that dropping packets before doing the route lookup was more efficient. However, he questioned — in the case where the vast majority of packets coming in get forwarded through the router — does it still make sense to evaluate all of them against the DROP rule in the pre-routing chain, given the vast majority will pass on to the route lookup anyway?
The question ultimately condenses into whether it is more costly to do a route table lookup for the small number of packets we eventually drop or a rule evaluation for the large number of packets we end up forwarding.
Consider these two situations:
- raw / pre-routing rule:
- All packets get evaluated on ingress by the DROP rule
- Dropped packets do not go through route lookup
- filter / input rule:
- All packets go through the route lookup stage
- Only those for the local system get evaluated by the DROP rule
Test environment
We set up three virtual machines (VMs) as shown in Figure 1. The router’s VM had the conn_track module loaded but the NoTrack rule was configured in the raw table. They were running on Linux with QEMU, with the connections between them made with VirtIO devices bound to a separate hypervisor bridge device for each link:

The router VM had over 900,000 routes added to a selection of approximately 50 next-hops, all configured on the receiver node. This was to ensure there was a very large routing table the system needed to look up as packets went through it. We set the next-hops to a bunch of about 50 IP addresses that we configured on the ‘traffic dest’ VM, so there were plenty of next-hops groups too. For example:
root@iptrules:~# ip route show | head -6
default via 192.168.122.1 dev enp1s0
1.0.0.0/24 via 203.0.113.8 dev enp8s0
1.0.4.0/22 via 203.0.113.22 dev enp8s0
1.0.5.0/24 via 203.0.113.5 dev enp8s0
1.0.16.0/24 via 203.0.113.16 dev enp8s0
1.0.32.0/24 via 203.0.113.1 dev enp8s0
root@iptrules:~# ip route show | wc -l
925525
root@iptrules:~# ip neigh show dev enp8s0 | head -4
203.0.113.32 lladdr 52:54:00:5f:02:5f REACHABLE
203.0.113.28 lladdr 52:54:00:5f:02:5f STALE
203.0.113.10 lladdr 52:54:00:5f:02:5f REACHABLE
203.0.113.6 lladdr 52:54:00:5f:02:5f REACHABLETest 1: Raw vs filter table, with packets sent only to the router’s local IP addresses
In this test, we do a one-to-one test using a raw vs filter table where all the packets we send will get dropped. Is it more efficient to drop them in raw, before the route lookup, rather than in filter, which is post route lookup? In theory, it should be more efficient to drop them in raw.
In both situations (raw vs filter), approximately 280k 128-byte UDP packets were sent per second for 10 minutes. iPerf2 was used to generate the UDP streams on the traffic source VM, to the IP configured on enp8s0 of the router VM. The iPerf2 command was as follows:
iperf -l 128 -i 10 -t 600 -c 203.0.113.1 -u -b 300MThe iptables raw table rules were as follows. This shows the state after the test including packet counters:
root@iptrules:~# iptables -L -v --line -n -t raw
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 165M 26G CT all -- * * 0.0.0.0/0 0.0.0.0/0 NOTRACK
2 165M 26G DROP udp -- * * 198.51.100.1 0.0.0.0/0 udp dpt:5001 ADDRTYPE match dst-type LOCAL
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 753 402K CT all -- * * 0.0.0.0/0 0.0.0.0/0 NOTRACKThe iptables filter table test variant was configured as follows. This shows the state after the test including packet counters. The counters look similar in terms of total packets and drops:
root@iptrules:~# iptables -L -v --line -n -t raw
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 165M 26G CT all -- * * 0.0.0.0/0 0.0.0.0/0 NOTRACK
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 446 205K CT all -- * * 0.0.0.0/0 0.0.0.0/0 NOTRACKroot@iptrules:~# iptables -L -v --line -n -t filter
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 165M 26G DROP udp -- * * 198.51.100.1 0.0.0.0/0 udp dpt:5001
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destinationLooking at CPU usage during both tests, we see dropping in raw, as expected. Figure 2 shows the CPU usage for the Test 1 comparison. Figure 3 shows the CPU usage for the Test 2 comparison.
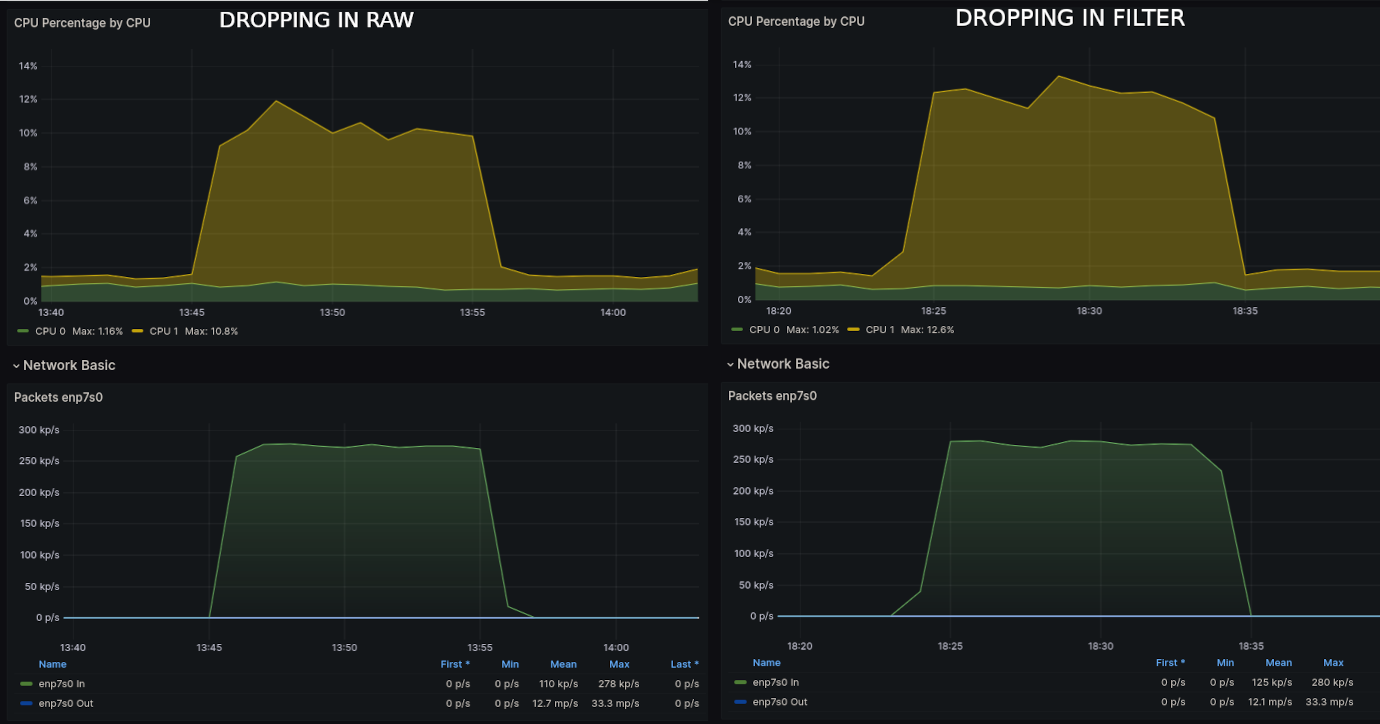
Figure 2 illustrates that CPU usage was lower, averaging around 10%, before the route lookup (raw). When packet dropping post-route lookup (filter), the average CPU usage was 12%. Accounting for the removal of 1.5% background CPU, the usage when using the filter table is approximately 15% higher.
Test 2: Raw vs filter table, with most packets forwarded to the destination
In this test, we do a one-to-one test on using the raw vs filter table on the original hypothesis. In this case, we generated four iPerf2 streams of traffic towards some IP addresses on the destination VM. These streams will be forwarded through the router, in parallel with the forwarded traffic. We also sent a lower number of packets to the router’s local IP addresses (similar to Test 1 but at a lower rate). The objective was to assess the relative impact of evaluating rules for all packets (when the rule is in the raw table) compared to bypassing that step and performing a routing lookup on every packet, even those marked for dropping.
The iptables raw table rules were as follows, this shows the state after the test including packet counters:
root@iptrules:~# iptables -L -v --line -n -t raw
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 155M 84G CT all -- * * 0.0.0.0/0 0.0.0.0/0 NOTRACK
2 58604 9142K DROP udp -- * * 198.51.100.1 0.0.0.0/0 udp dpt:5001 ADDRTYPE match dst-type LOCAL
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 386 185K CT all -- * * 0.0.0.0/0 0.0.0.0/0 NOTRACKThe iptables filter table test variant was configured as follows. This shows the state after the test including packet counters:
root@iptrules:~# iptables -L -v --line -n -t raw
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 155M 83G CT all -- * * 0.0.0.0/0 0.0.0.0/0 NOTRACK
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 412 187K CT all -- * * 0.0.0.0/0 0.0.0.0/0 NOTRACKroot@iptrules:~# iptables -L -v --line -n -t filter
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 58603 9142K DROP udp -- * * 198.51.100.1 0.0.0.0/0 udp dpt:5001
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destinationFigure 3 shows the CPU usage during both tests.
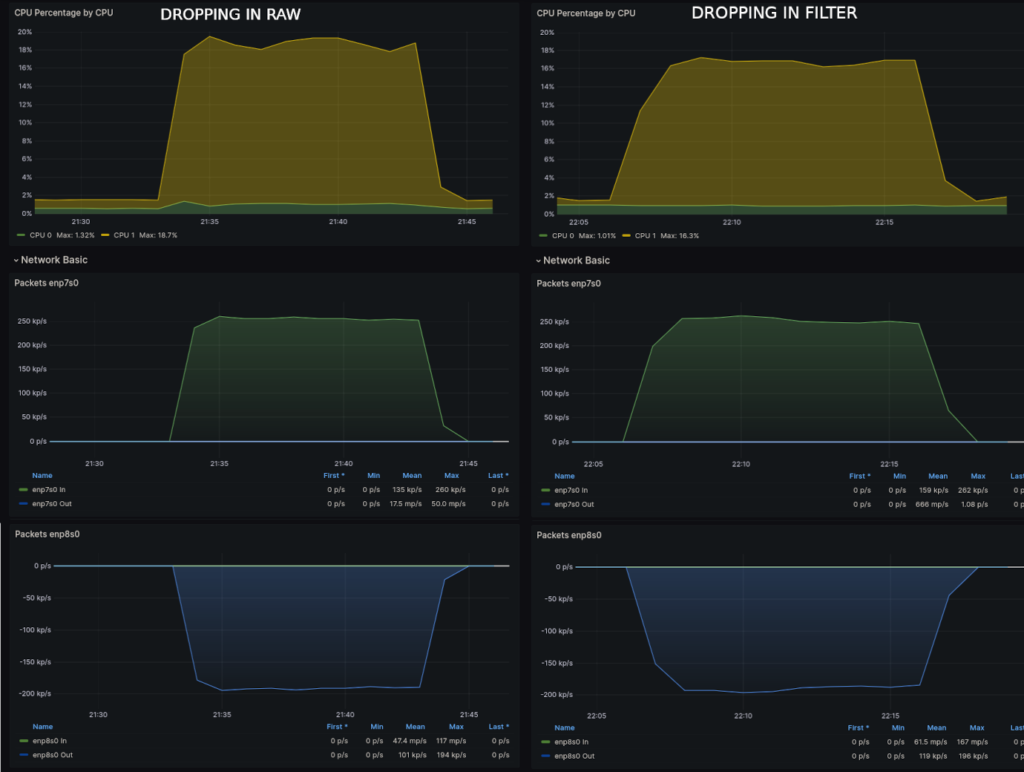
There’s clearly only a marginal difference, but it does appear the CPU usage was slightly lower with the drop rule placed in the filter table’s input chain. Despite the system having to do a routing lookup on the 58,603 packets it dropped, not having to evaluate the DROP rule against the 155 million packets forwarded made the overall CPU usage lower.
Conclusion
It is safe to say that the traffic mixture ratio is a factor in deciding where it is best to deploy filtering rules for a given situation, which was the original contention. This test does not conform to a strictly controlled environment, but it is sufficient to derive an approximated conclusion.
As the proportion of dropped packets increases, particularly in the scenario where all packets are dropped (Test 1), the ability to bypass the route lookup for those packets results in reduced CPU usage.
However, it’s worth noting that even if the majority of the packets are forwarded through the router (Test 2), a Denial-of-Service / Distributed Denial-of-Service (DoS / DDoS) destined towards the router’s local IP addresses may drastically change the ratio of traffic. Then, it would make sense to protect your router by dropping said packets in the raw table, as it would then be critical in such a situation to drop early to have any chance of preserving the system’s CPU.
In essence, there might be a trade-off where you opt for a less efficient approach under typical conditions to gain certain benefits in uncommon scenarios.
It’s worth remembering that connection tracking is expensive and becomes vulnerable to a DDoS attack as the table may flood. I believe that opting for a stateless approach is preferable when the circumstances allow. However, if you are compelled to adopt a stateful approach, it is advisable to establish NoTrack rules for trusted traffic, BUM traffic, as well as trusted BGP/OSPF/LDP neighbours. Additionally, consider dropping certain types of traffic in the raw and filter stages based on your traffic distribution.
This test was not to determine the best thing for every situation but to get some sense of the relative performance of one of these options versus the other.
Daryll Swer is an independent network consultant with a deep passion for computer networking. Specializing in IPv6 deployment, he provides expert guidance to ISPs, data centres, and businesses looking to optimize their networks. With ongoing research (AS149794) and practical insights, he empowers professionals to harness the full potential of IPv6 and improve their network performance and scalability.
This post is adapted from the original at Daryll’s Blog.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.