

Today, the acronyms RPKI and ROA are nothing new to the network engineer. But back when I first learned about them during APNIC 46 in 2018 (where I was a Fellow), those two acronyms were rarely mentioned in Malaysia.
As time passed, I became more aware of news and APNIC Blog posts about route hijacks, even from the top-tier providers.
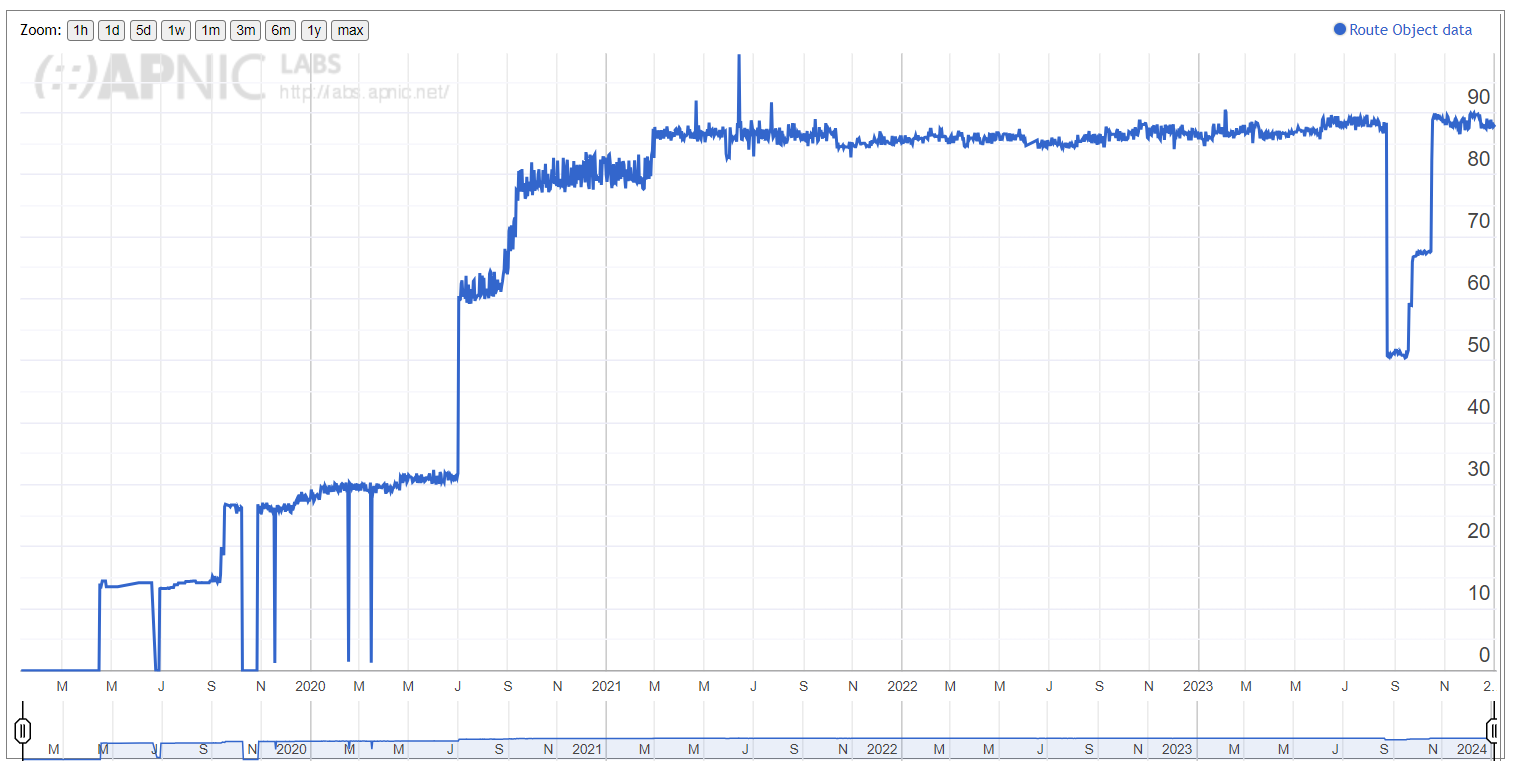
This rang alarm bells for me. Malaysia needed it. As doctors always say ‘prevention is better than cure’.
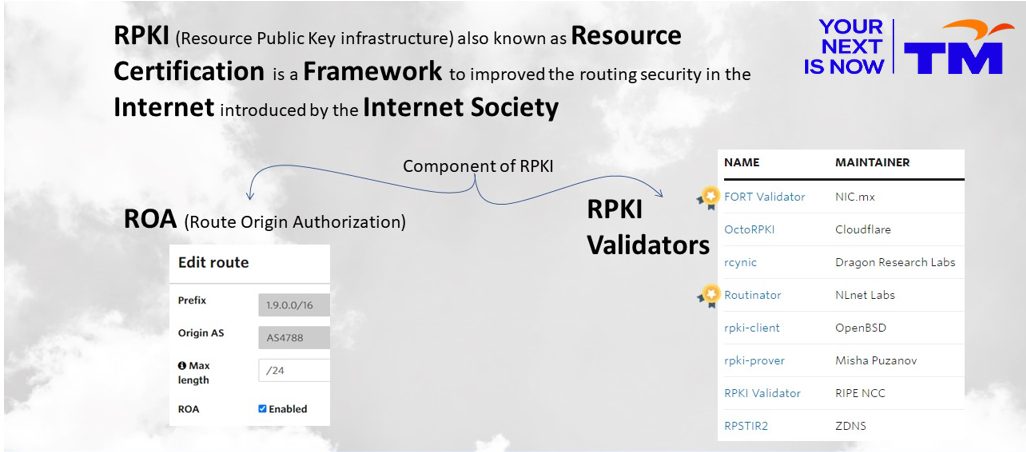
A little bit about Telekom Malaysia
Founded in 1984, Telekom Malaysia (TM) started as the national telecommunications company for fixed line, radio, and television broadcasting services. It is now the economy’s largest provider of broadband services, data, fixed line, pay television, and network services. TM ventured into the LTE space with the launch of TMgo, its 4G offering. TM’s 850 MHz service was rebranded as ‘Unifi Mobile’ in January 2018.
TM now has more than 28,000 employees and a market capitalization of more than RM 25B.
How we began our journey
The objective was clear. We needed to install RPKI validators into our BGP systems and ensure our ROAs were updated. Knowing what to configure and how to do it wasn’t enough to modify the router configuration. We didn’t want to be in deep water without a lifebelt.
Engagement with the higher-up levels in the organization had been planned and organized. Decision makers aren’t necessarily network engineers; some are mid-tier managers. Thus, the approach was to show them a proper flow in a comprehensible network diagram. There is a reason why the idiom ‘a picture paints a thousand words‘ exists. Though I am no Picasso, I did my best to depict what I wanted to deliver. This received the attention and consideration it needed to proceed.
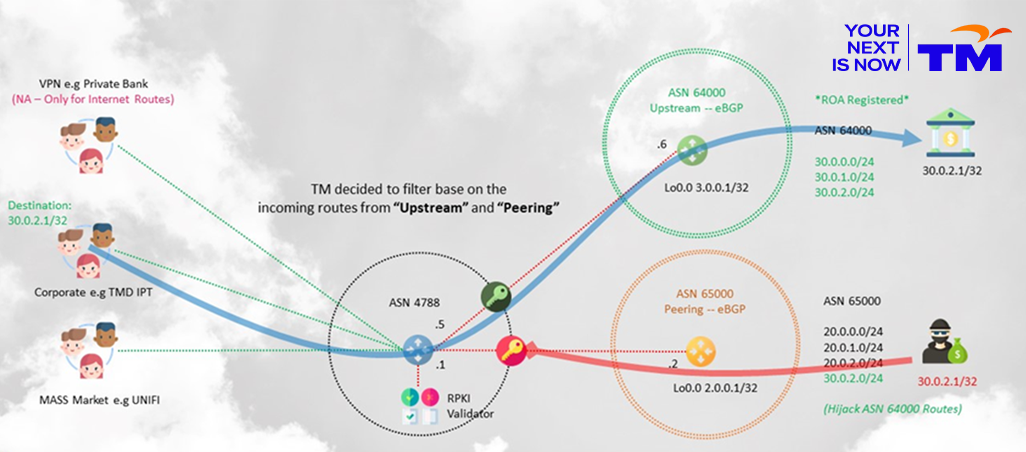
Calling the shots
That was the easy part — this is where the heavy lifting begins. First, I identified team members from the development team, network operation team, and some representatives from the lab team. All team members would need the same view from the beginning. It’s important not to forget all the vendors targeted to enable the RPKI validation later. We have multiple vendors running the provider edge router (PE) nodes and with those we needed to know what challenges we might face.
Now let’s ‘break a leg’! (Why ‘leg’? It’s because we need our hands and fingers to configure things and troubleshoot later!).
In the lab, all node versions were updated since we noticed certain vendors were not able to activate the validation with their older versions. Which validators to use is a bit tricky since there are multiple options with multiple installation methods. I decided it would be wise to learn from the experiences of others.
Our main reference was the APNIC Technical team who were able to advise which validators others are using and how they approached validation. The keyword here is ‘ask’. There are several experienced engineers out there who are open to giving help and advice. Just ask!
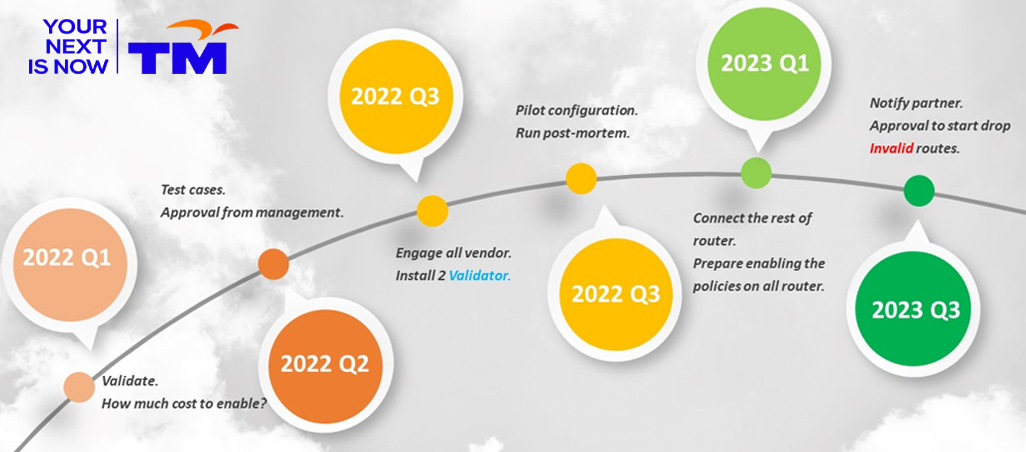
Testing — Lab setup and simulation
So, I have the planned sketch ready up until dropping the invalids. At this stage, I wished I could borrow Thanos’ Infinity Gauntlet, just for a few minutes. But, one can only dream, and luckily, I am surrounded by a team of lifesavers.
I wrote down the Acceptance Test Procedure (ATP) for what needed to be tested and validated. My goal was to gather all information on how the lab model ran and assess the load of the router (CPU and memory utilization) to ensure that the test validation wouldn’t harm the traffic running behind it. Three validators had been set up and there were a few problems, such as:
- Lost connection to the logical switch since we were using Virtual Machines (VMs).
- Somebody mistakenly downgraded the PE OS causing the config to be stale since that version doesn’t support RPKI.
There were also other minor problems. Despite all the challenges, I still sleep soundly at night and have time to watch movies. I’d rather break things in the lab than bump into it later in production.
Table 2 shows some of the test cases validated covering multiple vendors and the results of the testing.
| Vendor A | Vendor B | Vendor C | Vendor D | |
| 1. Dual peer validator | OK | OK | OK | OK |
| 2. BGP route status | OK | OK | OK | OK |
| 3. Drop Invalid | OK | OK | OK | OK |
| 4. Add comm for Unknown route | OK | OK | OK | OK |
| 5. Modify local pref for Unknown route | OK | OK | OK | OK |
| 6. Whitelist | OK | NA | NA | OK |
| 7. Validator 1 down | OK | OK | OK | OK |
| 8. Validator 2 down while 1 still down | OK | OK | OK | OK |
| 9. Validator up at the same time | OK | OK | OK | OK |
| 10. Route status when both validators fail | OK | OK | OK | OK |
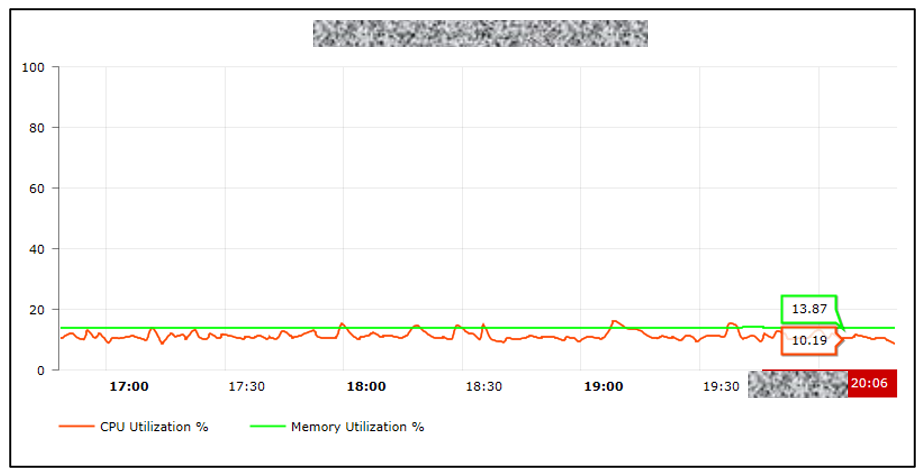
As Optimus Prime once said, ‘roll out!’
With all the lab results looking good, it was time to bring it into production but rushing to install everything is never a good option. I wanted to first deploy the pilot, which is five nodes for each of the vendors and monitor their performance. A proper Method of Procedure (MoP) document was written to ensure the team stayed on track with which node to install first and how many nodes per night.
Controlling the number of nodes in deployment did come at a cost. During validation, we bumped into two issues. First, when we saw a new configuration introduced, it triggered the other running routes in the router to refresh. Internet traffic was okay but for tunnelled traffic running over Generic Routing Encapsulation (GRE) or IPsec tunnels, it had the potential to cause the tunnel to flap and trigger unnecessary alarms. For this situation, we could skip the command line options in question and still meet the objective, thus minimizing the required configuration change.
Secondly, we found that from one vendor, their PE would trigger a route refresh message to the route reflector each time it received a new state and updated the ROA database from the validators. Those route refresh messages cause the route reflector to resend the full Internet prefix set to the node and cause unnecessary CPU consumption at the route reflector. Upon confirmation of the incident, I decided to remove the validation config from those PEs and ask the vendor for a fix. We got those patches later to solve the issue.
| Validation-state | RFC 8097 |
| origin-validation-state-invalid | 0x4300:0.0.0.0:2 |
| origin-validation-state-unknown | 0x4300:0.0.0.0:1 |
| origin-validation-state-valid | 0x4300:0.0.0.0:0 |
Working with multiple vendors’ equipment means you will have multiple ways of executing and configuring the syntax, not to mention the verification command. We stuck to the goal of determining whether the router drops the ‘Invalid’ when necessary. Where we found a lack of support for some functions, as long as it wasn’t a major issue or a blocker, we let it be. Table 4 shows the different default values that we saw, which we standardized wherever possible. We recorded the numbers in the MoP document for reference.
| Validator timer | Vendor A | Vendor B | Vendor C | Vendor D | All nodes |
| refresh-time (s) | 300 (5m) | 300 (5m) | 1,800 (30m) | 300 | 600 (10m) |
| hold-time (s) | 600 (10m) | 600 (10m) | 1,800×3 (90m) Fix | 600 | 1,200 (20m) |
| record-lifetime (s) | 3,600 (60m) | 3,600 (60m) | 3,600 (60m) | = hold-time | 3,600 (60m) |
| preference (s) | 1..200 > best | NA | NA | 1..10 < best | |
| white-list invalid | YES | YES | NA | NA |
Challenges
So, we’d finished preparing our node for validation, all policies were in place, all sessions to our multiple validators were up and running…
Let’s drop the invalids!
Wait, are you sure? What happens if the invalids are unintentionally dropped, and the origin was initially triggered by an honest mistake from the IP holder while updating their ROA?
We needed to look at this from another perspective. We collected all the invalids received from all our upstream and peering relationships. We segregated all those IPs and identified how much traffic was flowing from them. From there, we filtered all the traffic that exceeded 100 Mbps, totalling about 12 IP addresses. From there, we explored why they were being flagged as invalid.
There were eight prefixes where their ROA covers up to a /22 but their advertisement was actually a /24. We contacted them and asked them to fix their ROA before TM dropped the invalids and dropped the route that was obviously invalid since it originated by a different ASN.
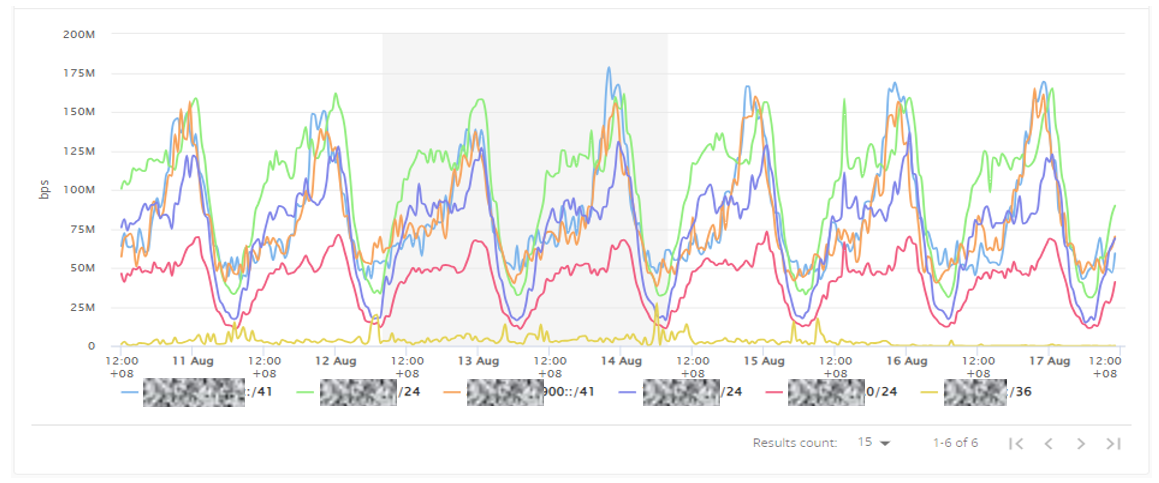
Let’s spread the news
As per the plan, we were then validating the final MoP for dropping invalids and were seeking to share the news. We were meant to have a slot during APNIC 56 in Kyoto, but I was not able to make it (oh gosh, that made me remember Mount Fuji. The last time I saw it was while watching Pacific Rim Uprising. Even the alien wanted to go there! Ok, let’s get back on track).
We began by updating our email signature for the team that communicates with our upstream and peering partners. For example:
“TM AS4788 had recently installed RPKI Validators and will drop “Invalid” routes by November 2023. Please update your ROA accordingly.”
An email notification template was also prepared and broadcast. We had also prepared the same template and plan for placing those remarks inside RADB, PeeringDB, and our whois contact.
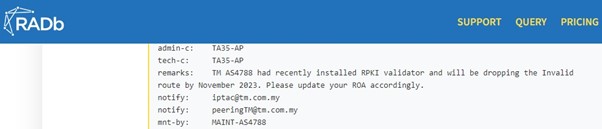

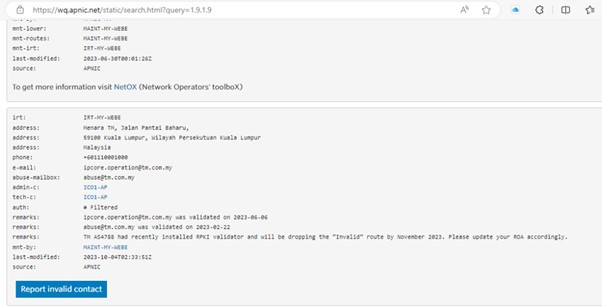
This blog post is another way we are sharing this news.
Good stories finish early
Although we had some delay in deploying RPKI, we got there in the end.
Was it difficult to deploy? No, despite my team and I never having done this before. We did have hiccups, but it didn’t stop us. We worked our way through with the support of others — APNIC, our vendors, and our upstream partner. As already mentioned, If you need help, just ask.
If I could turn back the clock, would I do it differently? No, this was the right path for us. For others planning to deploy, go for it.
To finish, I would like to quote Helen Keller: “Alone we can do so little; together we can do so much”.
Muzamer Mohd Azalan is currently attached to the Core IP Development team in Telekom Malaysia. He has 14 years of working experience in Network Operations and Development teams. His interests are in routing protocols, routing security, and SDN. Muzamer also volunteers as an APNIC Community Trainer.
Check out the RPKI @ APNIC portal for more information on RPKI, useful deployment case studies, how-to posts, and links to hands-on APNIC Academy lessons and labs.

The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Dear Muzamer,
Is IPv6 remote access still going through AF_INET6 ,that is, ISPs still provide a public IPv4
WAN address only to a customer for remote connection to a private network. After connection through
the ISP given public IPv4 address, AF_INET6 will handle the ISP allocated IPv6 delegated prefix
block and the IPv4 dual stack through a translation of IPv4 address to IPv6. That is, a remote Host can
interact with a remote Server (AF_INET6 capable) with both IPv4 and IPv6 protocol. If this is still
the ISPs way, then the public IPv4 addresses for connection is still limited and will be exhausted soon.
Since 2013, I have been trying to do remote connection through native direct IPv6 address and have not
succeed yet. Is there such a thing that an ISP can assigned a public IPv6 address to a customer?
Is is because that ISP still has many security issues to resolve in order to provide a public IPv6 address
to a customer for remote access and that is the main reason why ISPs are sticking on to CGNAT and only
offer a public IPv4 address for remote access to a remote private network Server.
Kind Regards,
SL Chong
Hi SL Chong,
Thank you for the comment.
Answering below base on my personal view. I will have a look later on AF_INET6 but covering on below question:
Question 1: Is there such a thing that an ISP can assigned a public IPv6 address to a customer?
My comment: Allocation to customer for the IPv6 address should be a public IPv6 address since its more than enough compared to IPv4, but it depend also on each ISP policies or offering.
Question 2: Is is because that ISP still has many security issues to resolve in order to provide a public IPv6 address to a customer for remote access and that is the main reason why ISPs are sticking on to CGNAT and only offer a public IPv4 address for remote access to a remote private network Server.
My comments: In regards to the security issue, in any design I believed all the architect and engineer shall cover any security flaw or risk to ensure the sustainability of the network as well as their customers.
My thoughts on ISP sticking to CGNAT is not mainly related to security issue with IPV6 etc. Among the reason why CGNAT is an option, merely as an intermediate solution prior to full IPv6 readiness while still be able to cater customer growth and providing services to their customer.
Hope that clarify, have a good day ahead SL Chong.