

I recently spoke at UKNOF 51 about ‘Software Best Practices for Networks’. The talk aimed to provide a list of practical tips and advice to other people who are slowly making the same journey as me from a pure networking role into a mixed or fully software development-based role.
This seems to be a common migration these days due to the pervasiveness of network automation. The talk was based on lessons learned by my colleagues and me, along our way to developing our own network orchestration system. That presentation is missing some key principles though, because as well as tips and tricks that are useful to know, there are some wider topics to discuss, each of which could fill an entire talk on their own. I’m referring to fundamental working paradigm shifts that are required when transitioning from working with traditional networking infrastructure to software development.
I hope to capture one of those paradigm shifts in this post, to inform other networkers like me who are moving into the software side of network operations.
The most obvious difference when one starts working in software development is that one is now working with assets that are mainly virtual instead of physical. Even at the extreme end of the scale, such as networkers who only work with SD-WANs, somewhere there are physical devices running the virtual Customer Premises Equipment (vCPE) application that have to be physically deployed and connected to a last-mile connection.
Software, ultimately, has to run on hardware too, but often it can be anywhere, and often it can be easily moved, sometimes even with no downtime. The difference in working with virtual and physical assets is the core of the paradigm shift I want to discuss today, so let’s unpack it.
The software development world is more closely aligned to the ‘fail fast’ paradigm, meaning additions and changes to a codebase can be designed and implemented relatively quickly, and if there are any problems, they can also be relatively quickly fixed and redeployed.
In classical networking, we are used to the opposite of this. It’s typical for networking teams to discuss almost every aspect of network design, such as a hostname formatting schema or IP address allocation rules and so on, until they can repeat those rules blindfolded. The reason is that with infrastructure design and deployment we implicitly weigh our time and effort differently than with software development.
Typically, when we discuss the design and implementation of a new network feature, that outcome is codified (in a design document, config template, and more), and then it is repeatedly deployed. Every time an interface is configured, for example, the IP allocation schema is enacted. It’s not a one-time implementation step, and the number of implementations can easily be tens of thousands in the case of interfaces, even in a relatively small network.
On the software side of the same coin, we might design a new function to allocate IP addresses, implement the function one time in the codebase, and then reference that same implementation (the function) in all future additions to the codebase. This means that when updates are needed, there is only one place that needs updating, and all references to that original implementation receive the benefits of the update.
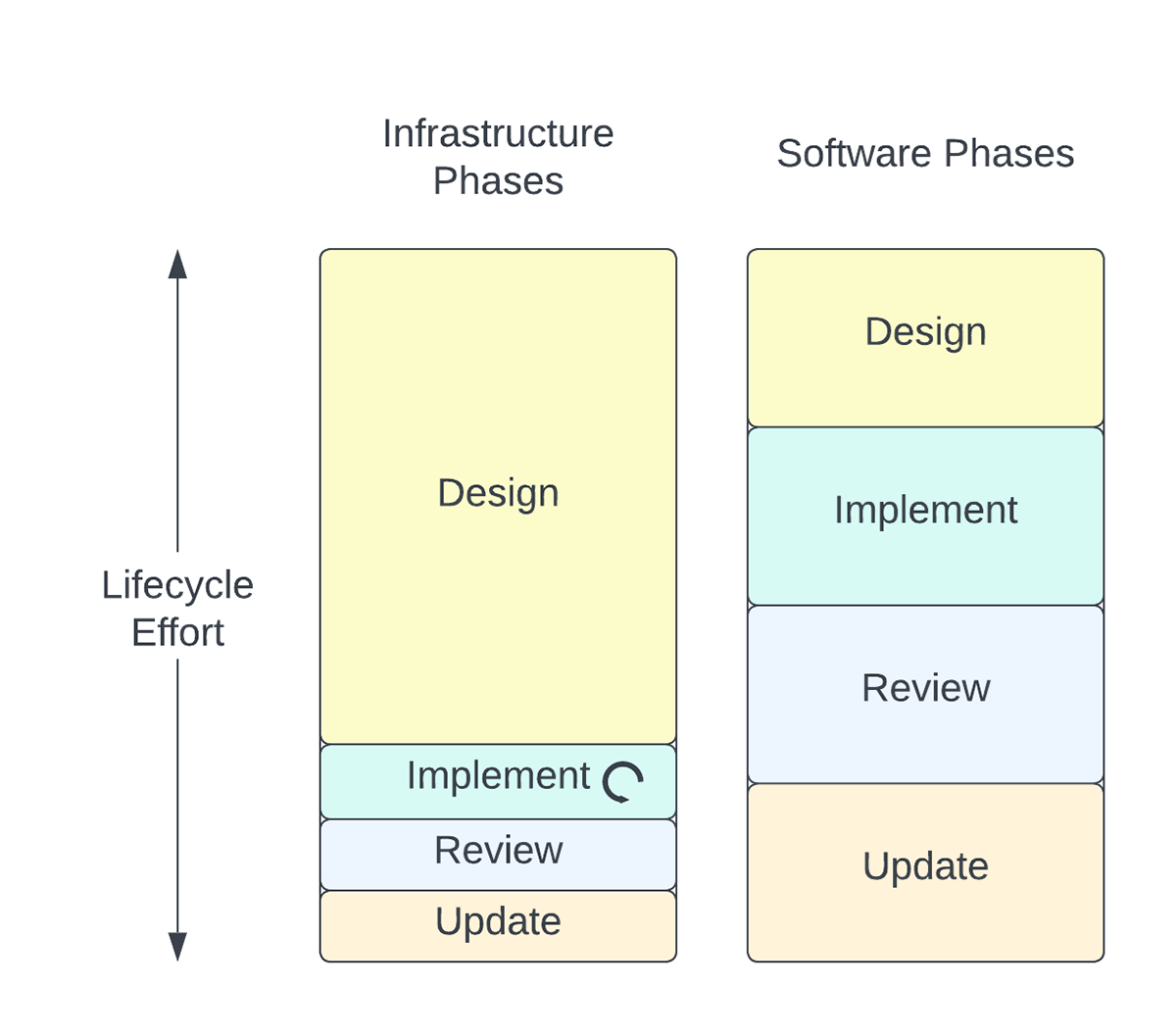
This has led to the commonly-used software paradigm, Don’t Repeat Yourself (DRY). This is simply not possible when one works with network infrastructure. Repeating the same configuration, following the same allocation schema, and consistently implementing the same design again and again, is how infrastructure is deployed. There are exceptions to this general rule on both sides but, in general, the network cycle is ‘discuss once, implement repeatedly’, while the software cycle is ‘discuss once, implement once’.
While changes on both the networking side and the software development side of network operations can be painful, it is incredibly easy on the networking side to create significant technical debt due to the amplification factor introduced by this repeated implementation step, which doesn’t exist on the software side.
As an example, any change to an IP address allocation policy immediately renders all existing allocations as legacy. This means that one of several next steps could be chosen:
- Every single interface in the network needs to be updated to align them to the update. This is not only time-consuming, but it creates service outages.
- It is accepted that new interfaces use the new addressing schema, existing interfaces remain as they are, but they are switched to the new schema whenever they are modified. This immediately creates a large volume of technical and operational debt.
- Existing interfaces that are experiencing the original problem — which led to the change in policy — are updated, the remainder stay as they are.
- The policy change is abandoned due to the significant overhead of updating all existing interfaces.
Option 4, in my experience, is the reason that many network improvements are simply never made; they are perfectly good ideas but the implementation effort outweighs the benefit.
Let’s imagine that we chose one of the other options, which now means that a software change is required. On the software side, we can imagine that there is one or a small number of functions that allocate IP addresses based on context (public or private addressing, point-to-point links, multi-point, and so on). A change could be made to this code to implement the new IP addressing schema. This means that one of several next steps could be chosen with regard to our automation system:
- Update our automation system to use the new IP allocation schema only and redeploy the software stack. The software stack would be fully up to date with our address allocation policy so there is no technical debt there, and this software update should have no impact on live network services. However, our automation platform can no longer interact with interfaces using the legacy IP allocation policy.
- Create additional functions that implement these new changes and accommodate the old and new IP schema side-by-side in the codebase. This increases the overhead of maintaining more code (although the growth in codebase size should be relatively small).
- The software change is abandoned because the benefits outweigh the implementation effort.
At first glance, it seems that this fundamental difference in the number of implementations in software being 1 (or very close to 1), makes the proposed software change a relatively minor and much more manageable change, than compared to the network side. In contrast to networking, the likelihood of the option relating to implementation effort exceeding the benefits being chosen is very low. However, there is now a new problem. Both option 1 and 2 introduce technical debt to the software stack, for a problem that is in the network.
In order to further understand the difference between network design and operation versus software development and operation, it would be helpful to understand the difference between technical debt in network operations and technical debt in software operations. This, however, warrants a discussion of its own and will have to wait for a future blog post.
Until then, we can already see that this paradigm shift in software development to single implementations of features has fundamentally changed the effort-to-benefit ratio for implementing a new feature, deploying the feature, and updating existing features in the software stack when compared to network infrastructure.
James Bensley does network engineering and coding for ISPs with many years of experience in designing, building, and maintaining networks and automating their operations. He is the Programme Committee Chair for UKNOF and a principal network engineer at Inter.link.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.