
The RIPE Atlas APIs receive millions of requests each day — which is, in general, good news! However, we also see some strange or sub-optimal client behaviour. Read on for a description of some of these cases and our suggestions on how to improve the use of the APIs.
Asking for probe status information
This is just a tiny sample of a client asking for statuses of specific probes (queries from the same IP):

This client was asking such questions more than a million times a day (in this case, within a small window around midnight). Note, we have around 13,000 active probes, so this is attributed to multiple times per minute, or even worse since the questions were only about a specific set of probes.
Furthermore, the status or metadata of a probe is — for the most part — very stable. Most probes are connected for days or even months with no change, and very few of them ever change other attributes such as their geolocation or source address. Therefore asking the same question again and again only provides new information in very rare cases.
Zooming in to queries about one particular probe:
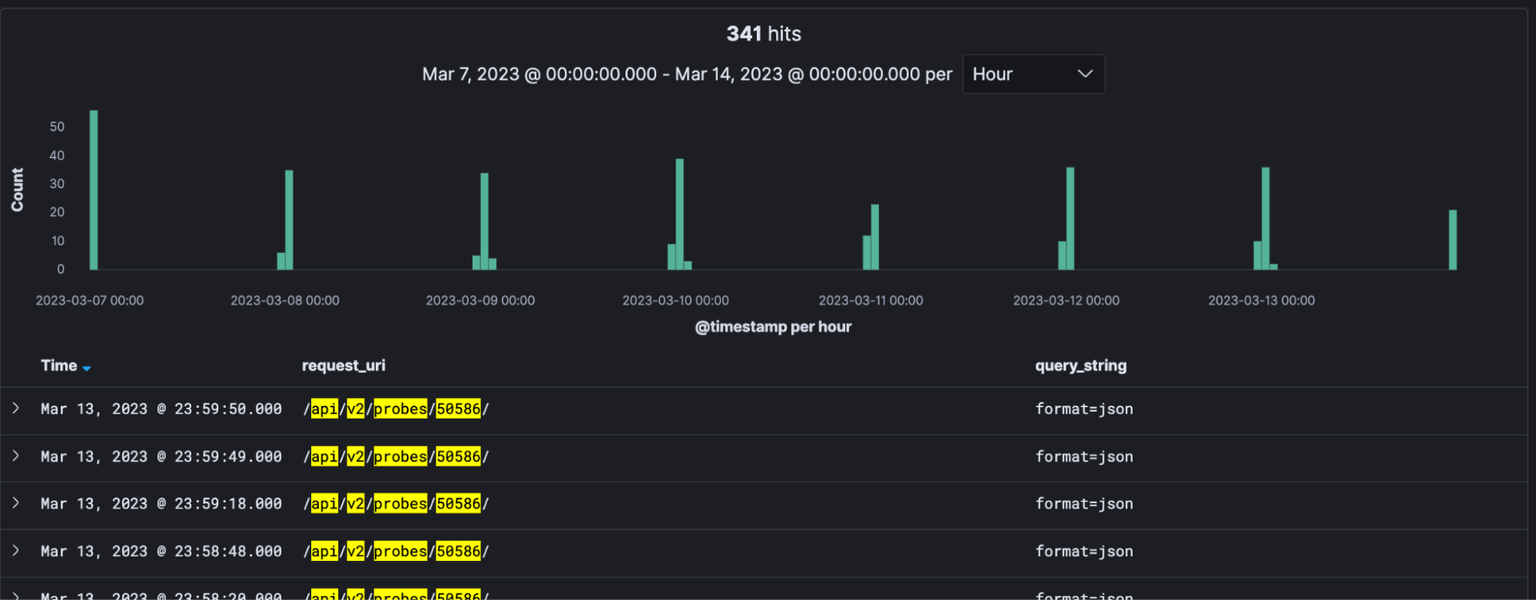
Figure 2 also shows queries for the same information multiple times (around 50 in each batch), which we assume to be the result of independent processes with no knowledge about each other.
Another pattern is when a user is asking for status information for a lot of probes in quick succession. In almost all of these cases, the real-time aspect (whether a probe is connected or not) is not the main reason for asking these questions — therefore retrieving this data in one bulk query makes more sense.
Users are free to ask for the status of any probe at any time. However, given the above example, we’d like to encourage those who ask the API for probe information to:
- Use the probe status archive if they are interested in the information about multiple probes. We publish this daily (therefore fetching it once a day is enough…) and it contains the relevant information about probes for almost all the cases.
- Share the results of such queries between multiple tasks if possible; local caching can go a long way in avoiding hammering the service.
Asking for measurement results
Take a look at this query log (queries from the same IP):
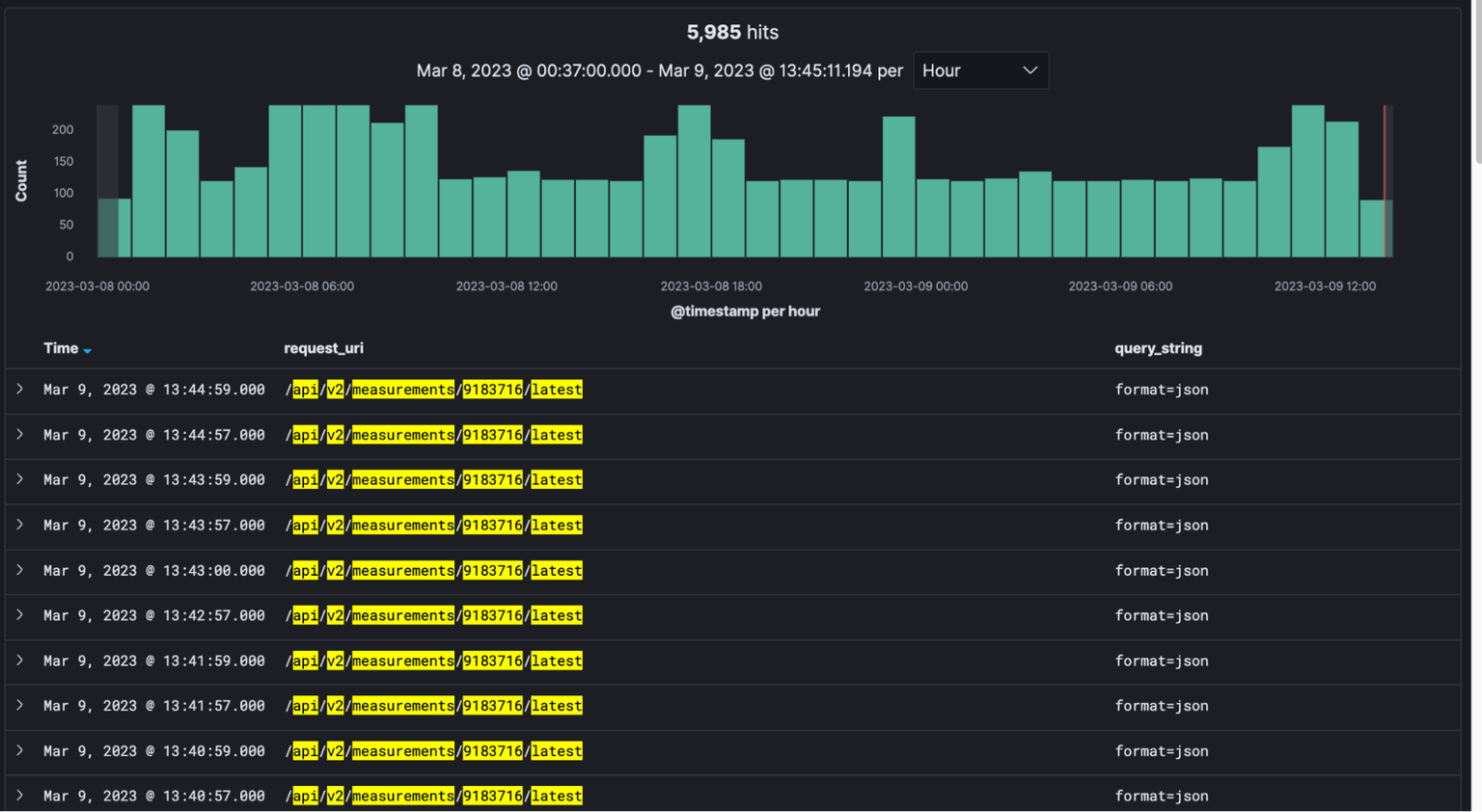
This client is asking for the latest results for a particular measurement every minute, basically polling for results. Also, it is seemingly done in two threads, three seconds apart every time. This particular measurement is run with a frequency of 900 seconds (15 minutes), therefore asking for results every minute is very expensive for both sides.
A much better and more scalable solution is to:
- Either use the result streaming service to get new results delivered to your client in real-time, or
- Poll for the latest results closest to the frequency of the measurement instead.
In either case, do this only once — doing it twice is double the work for the service as well as for the client.
Different measurements have different amounts of results. The size of such a call can vary between a few hundred bytes to multiple megabytes (per query). We had cases where the client was asking for hundreds of results in parallel — a very expensive operation. Therefore, as rate limiting purely based on the number of queries sent is a very coarse approach, we are considering introducing limits based on bandwidth usage per client.
Asking for results from a status-check
Similar to asking for measurement results, we see a pattern where users keep asking for measurement status checks multiple times per minute. Status checks (with all the gory details included, if needed) are relatively expensive to calculate since they involve looking up multiple recent results from each probe and combining and comparing these to come up with an ultimate answer. Therefore, the results of status check queries are cached for five minutes — asking more often should not yield different results.
Using ongoing measurements instead of many one-offs
Sometimes we see users scheduling one-off measurements involving the same probes, towards the same targets. In such cases, it is simpler (and credit-wise cheaper) to set up an ongoing measurement with a particular frequency instead and access the results of this when needed.
Measuring many different targets
Users of RIPE Atlas sometimes want to run measurements on a stable set of probes, but with varying destinations. For example, traceroute to A then B then C from the same vantage points. Since one of the definitions the system has is that each measurement has one specific target, this leads to users scheduling multiple measurements to achieve the desired result. This is fine if the number of targets, and therefore the number of measurements, is relatively low.
It is worth pointing out that measurement targets can be IP addresses or DNS names — in which case you can ask the system to resolve that name each time a probe executes the measurement (‘resolve on probe’). Depending on how that name is actually resolved, this provides a means to resolve to different IPs — therefore measurement targets — on different invocations. It is possible to run a special DNS server for this — one that can provide a different answer from some precompiled list when asked.
This is similar to a built-in measurement that all probes can already do. Measurements 5051, 5151, 6052, and 6152 are traceroute measurements targeting the most currently routed prefixes in BGP. This is done by looking up a DNS name that is mapped to the list of such prefixes. Each probe only gets to a relatively small number of such targets each day, yet the aggregate result is meaningful.
Note that such a DNS solution only gives a certain probability that each probe will measure each target. In many cases that is enough, or perhaps even better than fixed mappings between probes and targets.
Robert Kisteleki leads a dedicated team of thinkers at the Research and Development team of RIPE NCC to support the community by providing network research, data analysis, prototype tool development, and services including RIPE Atlas and RIPEstat.
The original post appeared on RIPE Labs.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.