

At the recent NANOG 86 meeting, I presented on behalf of DigitalOcean, “Being a better Netizen: MANRS @ DigitalOcean” to provide an in-depth explanation of how we interpreted and implemented the Mutually Agreed Norms for Routing Security (MANRS) guidelines. We set out to become compliant with the MANRS Cloud and CDN program, recognizing that as a member of the Internet community, it was necessary to do more to improve our routing security posture.
The MANRS Cloud and CDN program extends upon the network operators program and raises the bar for cloud providers as they contribute the most traffic to the global Internet. Below is a brief overview of how we applied the MANRS guidelines to AS14061 DigitalOcean during 2020.
The MANRS Cloud and CDN program comprises five key, required actions:
- Prevent the propagation of incorrect routing information.
- Prevent traffic with illegitimate source addresses.
- Facilitate global operational communication and coordination.
- Facilitate validation of routing information on a global scale.
- Encourage MANRS adoption.
Prevent propagation of incorrect routing information
DigitalOcean peers on some of the largest peering exchanges in the world, with thousands of bilateral peering sessions. To become compliant with this action, we engineered a solution to scalably ensure that our peers were sending legitimate prefixes on our bilateral peering sessions. In the process, we had to work within the hardware and software scaling bounds of our current network. For this process to be operationally sound, it must be automated with no operator intervention and must use information already published by peers — mostly, Resource Public Key Infrastructure (RPKI) and Internet Routing Registry (IRR) objects.
To understand the scaling concerns of filtering bilateral peers, we built the histogram below (Figure 1) based on the published IRR objects of our peers. Each histogram bucket represents the size of the prefix list we’d need to generate and apply — the y-axis being the number of peers that would require a prefix list of that size. For example, there are roughly 30 peers that would need a prefix list with 200 to 300 entries.
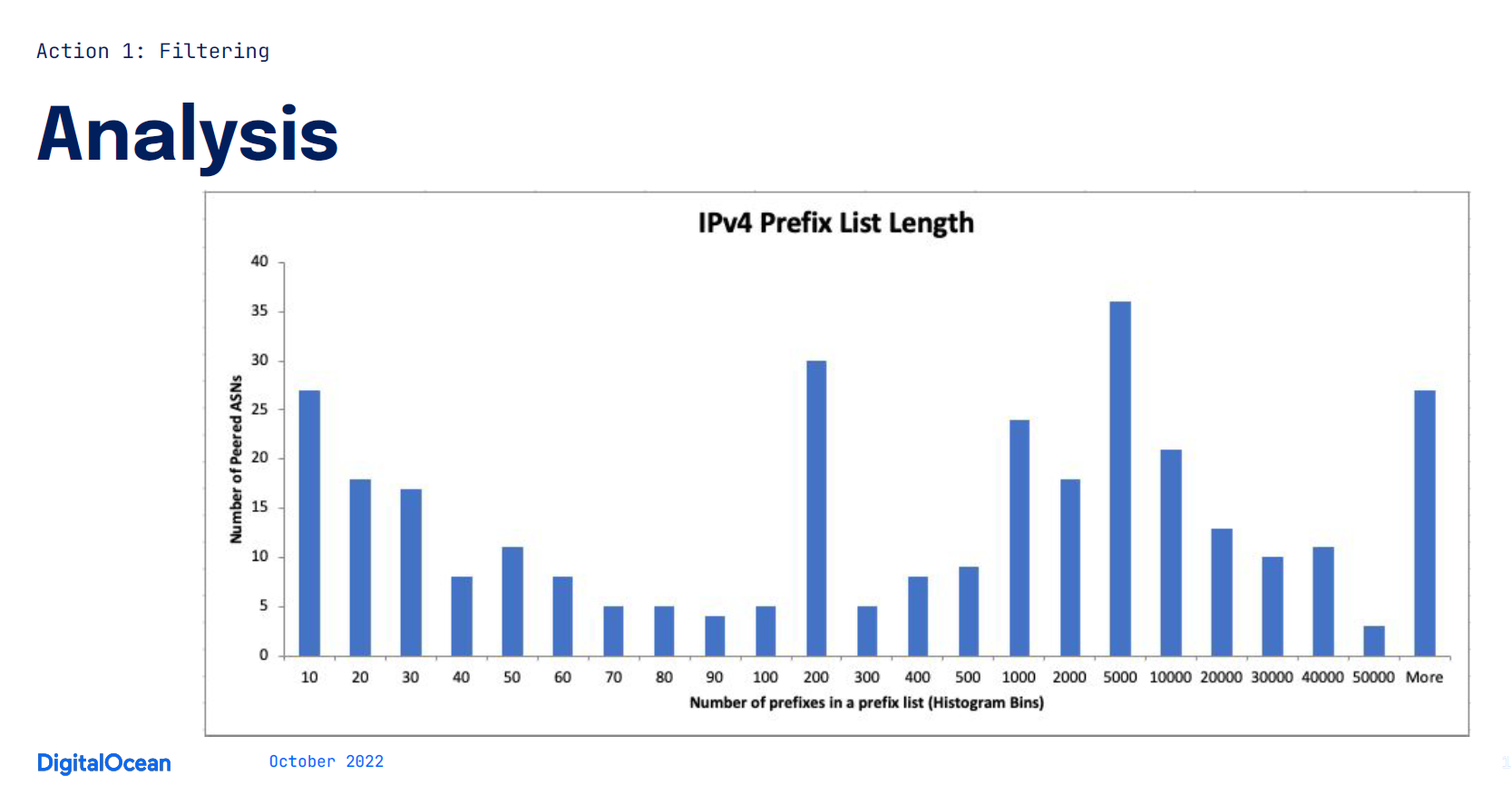
Figure 1’s distribution of our bilateral peers’ prefix list length shows a substantial issue — attempting 100% coverage would result in more than 6.5M lines of configuration for the prefix lists being added to some of our denser peering routers. Further lab testing showed that by pushing just 2M lines of additional configuration, we would add 95 seconds to an interactive apply operation, which would be unacceptable from an operator standpoint.
It was safe to say, the existing network hardware wouldn’t have sufficient capacity to filter 100% of sessions so we needed to find a way of filtering some peers to meet the requirements while not compromising the existing network.
We ended up picking a sensible maximum prefix list length that would only filter the peers that hit that threshold or lower. To determine what this threshold should be, we looked at what percentage of peers would be covered by selecting a given threshold (Figure 2).

Figure 2 shows the percentage of peers that would be covered at the prefix list threshold of peers that publish an IRR object. This threshold of 400 prefixes (red line) covering 48% of peers would require minimal operator activity, wouldn’t degrade network performance, and could be raised as the network is equipped with faster hardware and more modern software. A 400-prefix-long prefix list threshold realistically represents coverage of 25% of DigitalOcean’s peers (because many don’t publish an IRR object).
Applying the threshold to the network
We already have an extensive configuration management environment for the network, based around SaltStack, NAPALM, Netbox and Peering Manager. SaltStack is an extensible framework that allows us to programmatically build configuration templates based on our source-of-truth (SoT) data and apply them to the network in a performant and scalable manner. Today, we manage the configuration of thousands of network and network-attached devices using SaltStack.
Netbox was originally built at DigitalOcean and later open-sourced — it solves the problem of tracking devices, racks, cables, IPs, and prefixes within DC facilities and making that information available for automation. The stack is designed such that Netbox is the SoT and the automation applies that truth to the network.
Peering Manager handles our Border Gateway Protocol (BGP) SoT, storing details of IXP sessions to route servers, bilateral peers, Private Network Interconnect (PNI) transit sessions, and policy mappings. Peering Manager also pulls data from PeeringDB such as peer prefix limits, IRR objects, names, and contact information.
By querying Netbox and Peering Manager, Salt is able to determine which peers require a prefix-list and use their IRR object name to build the configuration. To speed up IRR object query performance, we host an internal instance of IRRd that mirrors all of the common IRR sources.
Every six hours, Salt queries our SoTs, to determine which peers have less than 400 prefixes in their IRR object and if so, generates the required configuration and commits it to the network. Further details about the filter configurations are provided in the original presentation (YouTube, slides).
Prevent traffic with illegitimate source IP addresses
As a cloud provider, abusive traffic and bad actors aren’t a new challenge for us — we’re very used to dealing with spoofed traffic. As part of the second required action, the MANRS guidelines ask members to ensure no spoofed traffic can leave their network.
At DigitalOcean, we’ve already built a multi-layered approach to prevent spoofed traffic from leaving the DigitalOcean edge. Given we control the hypervisors that customers run on, we also control the data path between customer workloads and the Internet. We can ensure that traffic leaving a given customer workload only has source addresses belonging to that workload.
Our operational teams also have sophisticated tooling to detect anomalous traffic within the data centre network as well as automated actions for mitigation. Finally, at the edge of the network, uRPF loose-mode is deployed to make sure there’s a valid route for the traffic from each hypervisor and to block spoofed source traffic from bogon prefixes.
While these controls work well, alerting is needed to raise the alarm when they don’t — this is where the CAIDA Spoofer Project comes in. We run an instance of the Spoofer in each customer region, the spoofer daemon attempts to send spoofed source address traffic towards the CAIDA-hosted collectors to determine if spoofed traffic is allowed or not. We query CAIDA’s API to collect test results with a custom Prometheus export and alert if spoofed traffic was received.
Further examples of Prometheus alert manager configuration are shown in the NANOG 86 presentation (YouTube, slides).
Facilitate global operational communication and coordination
The third required action for the MANRS Cloud and CDN program is to ensure accurate contact information is maintained in PeeringDB and Regional Internet Registry (RIR) whois databases. This ensures other network operators can reach you to troubleshoot routing issues.
As we are already a good ‘Netizen’, we update our whois data automatically as we consume new prefixes. As we use Netbox to track prefix usage, we can use that data, plus periodic scripted checks, to make sure our information is always accurate. We also rely on the information in our peer’s PeeringDB record to stand up peering relationships, so we ensure ours is also accurate.
Facilitate validation of routing information on a global scale
The fourth requirement asks MANRS members to publish and maintain information in IRRs and RPKI — to allow other networks to validate advertisements globally — is about ensuring routing information is accurate as seen in BGP, compared to the pre-declaration of intent.
To ensure our routing information is correct we, once again, rely on automated processes based on our SoT data to ensure everything is correct. As part of our allocation process, we use an aggregate IRR object to facilitate fast propagation from upstreams and then create a smaller prefix object after the fact. We manage this entire process with a custom, prefix-sync app that keeps RPKI Resource Origin Authorizations (ROAs), and IRR objects up to date and ensures that prefix geocoding is correct.
We use the tagging ability in NetBox to signal which prefixes should be announced from the edge — this is picked up by various automation to ensure that a prefix is configured correctly and has all the records created to be successfully announced to the wider Internet. This is why having a good SoT as mentioned earlier is necessary for facilitating this sort of automation.
RPKI
We currently sign aggregate prefixes with ‘covering-ROAs’ using the max length field to give flexibility of allocation to ensure advertisements are accepted upstream as soon as possible. This allows us to sign a larger prefix and a subnet of smaller prefixes to a given mask to ensure we have valid advertisements as soon as we start announcing a new prefix.
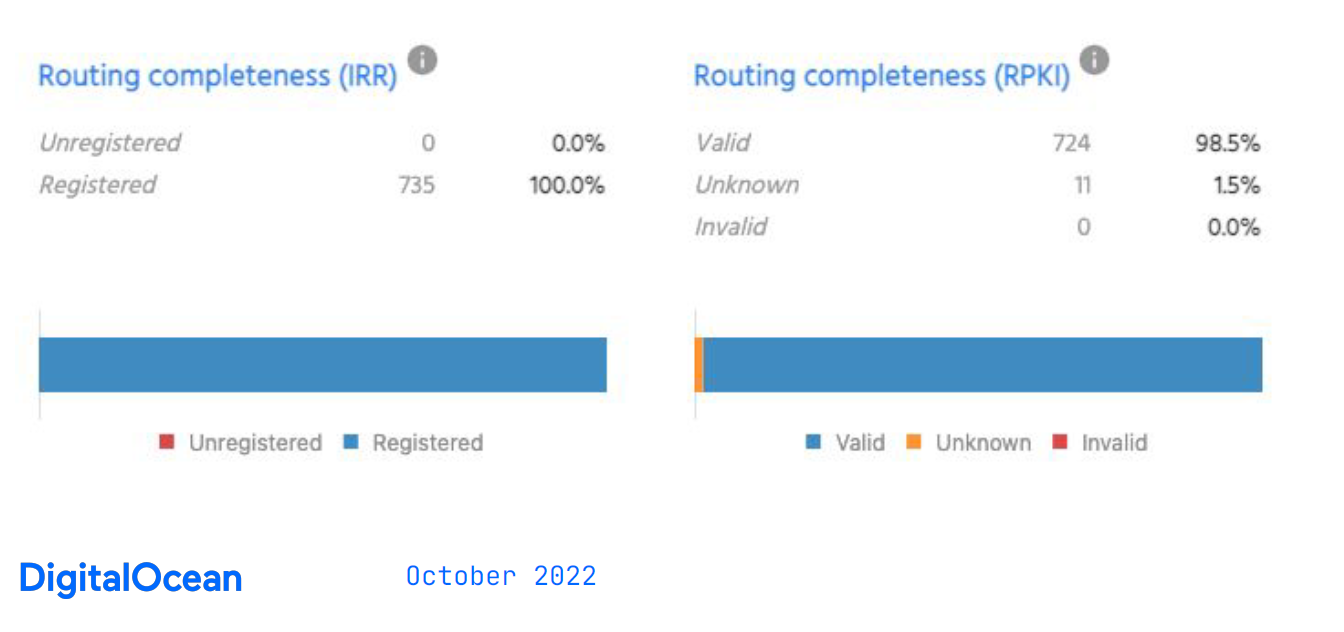
Once again, NetBox is used to crosscheck the automated processes, and as a reporting mechanism, linked to our alerting platform to tell us when configurations are incorrect. The reports (Figure 4) are run daily and compare NetBox data to the real world. With this report, we can examine all of our announced prefixes and check that they have a valid RPKI ROA, Validated ROA Payload (VRP), or an IRR object.
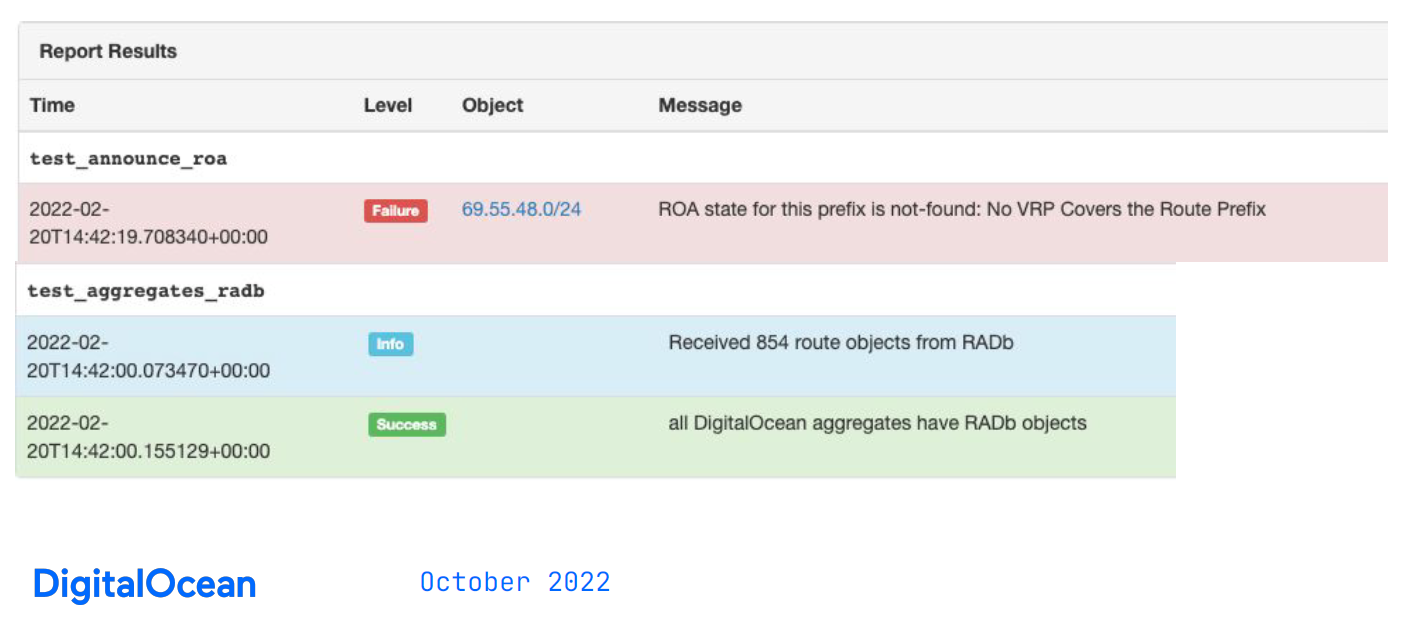
In Figure 4, the failed report alerts engineers and can be actioned as required.
Encourage MANRS adoption
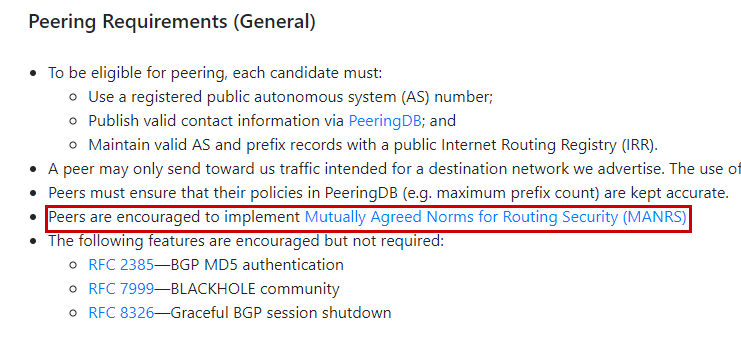
Action five asks members to actively encourage other networks to adopt these basic requirements. It can be as simple as updating your public peering policy or your PeeringDB comments (Figure 5) to indicate that your network follows MANRS.
What’s next?
At the end of a 12-month process of consideration, planning, and implementation, we were granted membership in the Cloud and CDN program! As a member, you’re listed among other networks that have obtained the same status on the MANRS website. You also gain access to the MANRS Observatory — this is a useful tool that aggregates several data sources to show how your network complies with MANRS policies.
But compliance isn’t the end; there is a sixth and optional action that asks MANRS members to provide a mechanism that helps peers identify routing issues and routing security issues. We have plans to provide additional tooling to members in the near future to fulfil this requirement too.
Improvement of your routing security posture should never end — we have multiple opportunities to improve our filtering coverage and to automate some of the manual processes as we evolve the network. As we experience new failures, we can improve our monitoring coverage and build new automated remediations to continually positively improve our routing security posture.
Tim Raphael is a senior network engineer on the Internet Edge and Backbone team at DigitalOcean (AS14061).
Check out the RPKI @ APNIC portal for more information on RPKI as well as useful deployment case studies, how-to posts, and links to hands-on APNIC Academy lessons and labs.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.