

This article is a continuation of a series that presents the Overlay Multilink Network Interface (OMNI) and Automatic Extended Route Optimization (AERO) services. Earlier articles in the series introduced the OMNI interface fragmentation and reassembly service as part of an assured Maximum Transmission Unit (MTU) facility.
In this article, we go deeper into what this means for upper layer protocol performance as well as the introduction of large packets in the Internet as a whole. We discuss the OMNI interface MTU, which is set to a minimum of 65,535 (the largest packet that can be reassembled). We further discuss path MTU ‘soft errors’ returned by the network layer that guide hosts to dynamically discover the optimum packet size to use, even if the size significantly exceeds the actual path MTU. We conclude by discussing a new form of packets known as ‘IP Parcels’ and their implications for performance in the future Internet.
It has long been considered that sending larger packets can improve performance due to many factors including reduced system call overhead, reduced network interrupts, reduced header overhead, and more efficient use of underlying data links. But the vast majority of modern data links still support MTUs of only 1,500 octets with some links supporting larger sizes up to approximately 9,000 octets. The 1,500-octet precedent was established in the earliest days of the Internet in the 1970s and 1980s, but the size remains to this day as a de facto Internet ‘cell size’. The 9,000-octet upper bound corresponds to the limitations of lower layer protocol integrity checks, which may fail to detect bit errors for larger packets.
Several initiatives over the decades that followed explored larger packet sizes. In the late 1980s, Fiber Distributed Data Interface (FDDI) set an MTU of slightly larger than 4,500 octets as part of its approach to supporting higher data rates. Then, in the 1990s and early 2000s, ATM networking established an MTU of 9,120 octets and HiPPI employed a 65,535-octet MTU in both production and experimental testbeds. During that same time period, however, Ethernet data rates were boosted to 1Gbps using the Internet de facto standard 1,500-octet MTU and these earlier large packet initiatives fell by the wayside. Indeed, in the modern era, even higher Ethernet data rates are now common.
Accommodating larger packets in the Internet
With the emergence of the OMNI interface and its OMNI Adaptation Layer (OAL), we now have the opportunity to again pursue larger packet sizes while still using ordinary data links that configure smaller MTUs. The OMNI interface uses the OAL to encapsulate original IP packets, then subjects them to IPv6 fragmentation to break them into a size that will be certain to traverse the forward path to the destination without loss due to a size restriction. The destination OAL then reassembles and decapsulates to obtain the intact original IP packet. Since IPv6 fragmentation can accommodate data units up to 64KB-1 (65,535 octets), this value, therefore, becomes the minimum OMNI interface MTU.
The OMNI interface also introduces a new form of signalling messages known as Packet Too Big (PTB) ‘soft errors’. Unlike ordinary PTB messages that always indicate loss, PTB soft errors provide the OAL destination with a means to inform the OAL source that it should begin sending smaller packets to reduce reassembly buffer congestion but without loss of any original IP packets. This allows the source to ‘tune’ the size of the packets it sends and to dynamically adjust to any size reductions or increases without loss of important data. Large packets that include a single segment of upper layer protocol data can therefore be tuned dynamically, but these studies inspired a new form of packet that includes multiple upper layer protocol segments. We call these packets ‘IP Parcels’.
The IP Parcel — a new ‘jumbo’ packet type
IP Parcels are constructed in a special packet format known as a ‘jumbogram’, but with multiple upper layer protocol segments instead of a single large segment. The construction of an IP Parcel is initiated by upper layer protocol entities including the Transmission Control Protocol (TCP) and User Datagram Protocol (UDP) users such as the Licklider Transmission Protocol (LTP). These entities produce a protocol unit data buffer containing up to 64 concatenated segments to form a TCP or UDP Parcel, as depicted in Figure 1. {TCP, UDP}/IP Parcels hold the same efficiency advantages as the postal system practice of wrapping multiple smaller items into one larger package known as a ‘parcel’ that travels together as a single unit. Indeed, parcels are commonly used by major online retailers to improve their shipping and handling efficiency.
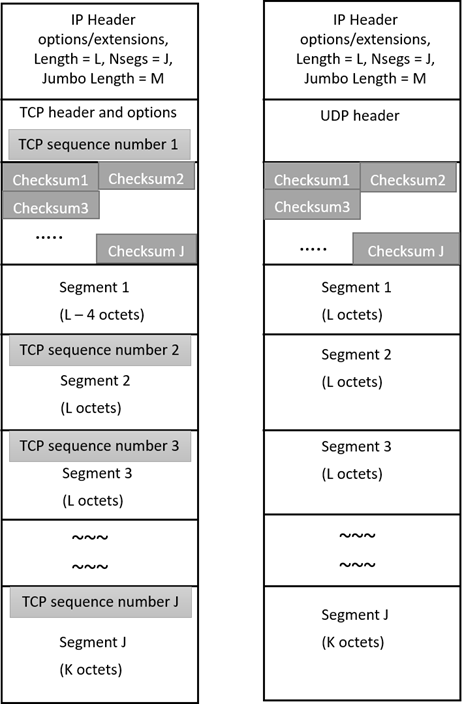
The TCP Parcel structure includes a block of up to 64 16-bit checksum fields following the TCP header. The checksum block is then followed by a corresponding number of upper layer protocol segments, with each checksum field including a checksum of its corresponding segment. The first segment is paired with the Sequence Number field in the TCP header, while each non-first segment includes its own 32-bit sequence number field as a ‘shim’ header to complete the TCP Parcel Structure. Similarly in the UDP Parcel structure, a full UDP header is prefixed by the checksum block which is then followed by the corresponding upper layer protocol segments. The {TCP, UDP} parcel buffer is then appended with an IP (IPv4 or IPv6) header along with a Jumbo payload option, and other necessary extension headers to form a TCP/IP or UDP/IP Parcel. The length of each segment is considered not to exceed the value of 65,535 minus the length of IP and TCP or UDP header encapsulations. The total length of TCP/IP or UDP/IP Parcel may therefore be as large as (64 * ~65535) = ~4MB.
IP Parcel forwarding and path probing
The IP layer presents each parcel to the network interface which may be an OMNI interface or any parcel-capable ordinary network interface with sufficient MTU. The parcel is then forwarded by routers as a conventional IP packet over parcel-capable IP links that support a sufficiently large MTU. If the parcel encounters a link in the path with a lower MTU link, the router instead opens the parcel and forwards each encapsulated segment separately as a singleton IP packet or in a set of smaller sub-parcels. The number of sub-parcel segments depends upon the MTU of each successive parcel-capable link. In another case, if any intermediate router fails to recognize the parcel at all, it then drops the parcel and sends an ICMP ‘Parameter Problem’ message. This condition should, therefore, be detected in advance through the use of parcel probes (see below).
If an OMNI interface receives a parcel that is too large to traverse the path in one piece, the OAL source assigns a ‘Parcel ID’ to each IP Parcel and subdivides them into multiple sub-parcels no larger than the next hop MTU if necessary. Within these length constraints, the OAL source determines the sequence of segments that can be included in each sub-parcel. Next, the OAL source performs TCP or UDP encapsulation of each sub-parcel, resets the header checksum and sets the TCP header sequence number field as the value for the first segment. Thereafter, the OAL source assigns a monotonically-incremented 32-bit identification number to each sub-parcel, performs IPv6 encapsulation and fragmentation, and then prepares to forward each sub-parcel fragment to the OAL destination. Each IP encapsulated sub-parcel fragment is then appended with an IP fragment header containing the Parcel ID, identification and flags for identifying between non-final and final sub-parcels. The IP Parcel is finally forwarded to the OAL destination through the next OAL hop.
Following reassembly at the OAL destination, the received sub-parcels may be retained for a brief time to support recombining on the basis of source and destination addresses, identification value and Parcel ID. The segments with matching credentials in these sub-parcels are concatenated in an order such that the final segment is included at the last to form a recombined larger sub-parcel. The size of this recombined sub-parcel could be equivalent to that of the original parcel. Again, the TCP or UDP and IP header along with necessary extensions are appended with each recombined sub-parcel before forwarding it to the next OAL node. If the OAL destination is the final destination, then all the recombined sub-parcels are forwarded to the upper layers.
The OAL source sends ‘Parcel Probes’ in parallel with actual IP Parcels to ensure that the leading portion of the path toward the destination traverses parcel-capable links. For this purpose, the probes employ a different Jumbo payload option format with the Jumbo payload length field set to a specific value to differentiate probes from actual parcels. As discussed above, if the router recognizes the parcel it either forwards the parcel in the original form or as an ordinary packet depending upon the MTU of the subsequent link. At this point, the router returns a positive ‘Parcel Reply’ to the original source. On reception of ‘Parcel Reply’, the source marks the path as ‘parcels supported’. The path has now become qualified to transit IP Parcels.
IP Parcel performance implications
The concept of IP Parcels is validated through our testbed implementation and performance testing. According to the empirical results, with the increment number of segments in the parcel and transmitting it with a fixed segment size, the throughput increases significantly. The same is also valid with the increase in segment size while keeping the number of segments fixed. During our performance analysis, data links supported the segment size of up to 64KB. These results indicate that the incorporation of IP Parcels in next-generation Internetworks with higher MTUs can provide truly revolutionary benefits. One of the first important use cases for IP Parcels is Delay Tolerant Networking (DTN) where high data rate bulk transfers over long delays (as opposed to short-message interactive exchanges) are the dominating performance requirement.
DTN has its origins in work started by NASA in 1998 for interplanetary use, where the delay to traverse space domain links involves one-way light times of many seconds, minutes, or even longer. Since DTN is therefore highly sensitive to high-performance bulk transmissions, it is the first upper layer protocol expected to take advantage of the parcel service. Studies with TCP and QUIC have shown that upper layers can realize greater performance when they allow lower layers to perform ‘segment offload’ functions. The upper layers can then admit multiple upper layer segments into the lower layer as a single large unit instead of forwarding them as multiple small units, saving on operating system calls while realizing greater efficiency in transferring larger blocks of data in a single data copy operation. These studies have pointed the way toward similar performance gains for DTN with the use of IP Parcels.
DTN employs the LTP as a ‘convergence layer’ to transfer large blocks of data known as ‘bundles’. The performance findings show that larger bundles result in significantly greater performance. With IP Parcels, the LTP can present bundles to the UDP/IP layers in larger blocks, which include multiple DTN/LTP segments instead of just a single segment. This produces a performance gain that parallels the gains shown for TCP and QUIC in other studies. The gains were also increased when the upper layer protocol segment size was made as large as possible (that is, up to 64KB) and with IPv6 fragmentation used to transfer the parcels over links with MTUs as small as 1,500 octets.
The performance of an LTP-based DTN implementation largely depends on the segment size. Experimental and operational evidence has shown that on robust networks increasing the LTP segment size (up to the maximum UDP/IP datagram size of slightly less than 64KB) can result in substantial performance increases over smaller segment sizes. LTP is configured over UDP and uses large UDP/IP message transmission and IP fragmentation bursting for increased network utilization. Our performance studies have also shown that sending multiple large LTP segments in a single IP Parcel provides measurable performance increases instead of sending multiple singleton IP packets with like-sized segments. This follows intuitively from the fact that each parcel requires only a single copy of the {TCP, UDP}/IP header and link layer headers where these headers must appear in their entirety in each singleton IP packet.
IP Parcels also provide an advantage in parallelism for DTN and LTP in that large portions of a DTN bundle (possibly even as large as the entire bundle) can be shipped as a single transmission unit, with the multiple IP Parcel segments processed in parallel at the receiver. This parallel processing is expected to provide a performance multiplier that can support sustained DTN data rates well in excess of 10Gbps. This is very important for DTN space domain applications where high data rate bulk transfers over long-delay links are required, and will be subject to further study as we enter the next phase in our investigations.
Contributors: Akash Agarwal, Madhuri Madhava Badgandi and Bhargava Raman Sai Prakash
Fred Templin, Akash Agarwal, Madhuri Madhava Badgandi and Bhargava Raman Sai Prakash are members of the Boeing Research & Technology (BR&T) technical staff within The Boeing Company. Their collaboration on the AERO/OMNI/DTN program since the mid-2010s has resulted in significant advancements in the technologies. They are currently engaged in producing a reference implementation for future publication.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
The OAL behavior as described has a considerable computational cost. Is that cost appropriate for terrestrial routing and switching? Today, IPv4 fragmentation & reassembly brings even the most powerful routers to their knees, and OAL would place an even higher burden on them.
Thank you for this question. With the OAL, only the original source (or a node very close to the original source) performs fragmentation and only the final destination (or a node very close to the final destination) performs reassembly. The vast majority of core routers in between the source and destination forward only the resulting carrier packets as whole packets which can be done at line rate. With the OAL, only a very few end systems or near-end systems are instrumented while the vast majority nodes in the infrastructure are not affected in any way. A small number of supporting Proxy/Servers and Gateways may also be necessary according to the deployment scenario, but these can often be instrumented as virtual machines in the cloud and again do not typically get involved with fragmentation and reassembly.