

At the most basic level, there are only three Border Gateway Protocol (BGP) policies:
- Pushing traffic through a specific exit point.
- Pulling traffic through a specific entry point.
- Preventing a remote (more than one hop away) Autonomous System (AS) from transiting your AS to reach a specific destination.
In this series, I’m going to discuss different reasons for these kinds of policies, and different ways to implement them in interdomain BGP. I’ll refer to Figure 1’s reference network throughout this post.
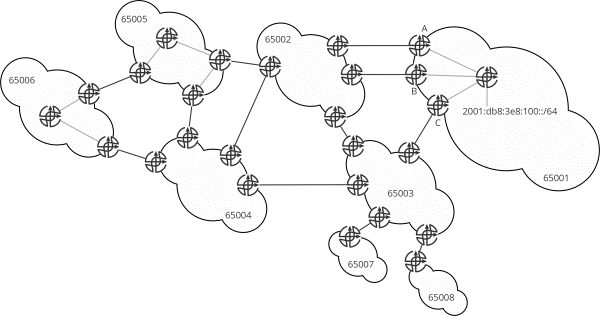
There are many reasons an operator might want to select which neighboring AS to send traffic through, towards a given reachable destination (for instance, 100::/64). Each of these examples assumes the AS in question has learned multiple paths towards 100::/64, one from each peer, and must choose one of the two available paths to forward along.
Examining this from AS65006’s perspective
Assuming AS65006 is an edge operator (commonly called enterprise, but generally just originating and terminating traffic, and never transiting traffic), there are several reasons the operator may prefer one exit point (through an upstream provider), including:
- An automated system may determine AS65004 has some sort of brownout; in this case, the operator at 65006 has configured the system to prefer the exit through AS65005.
- The traffic destined to 100::/64 may require a class of service (such as video transport) AS65004 cannot support (for instance, because the link between AS65006 and 65005 has low bandwidth, high delay, or high jitter).
The most common way this kind of policy would be implemented is by setting the BGP LOCAL_PREFERENCE (called preference throughout the rest of this post) on routes learned from AS65005 higher than the preference on routes learned from AS65004.
Another common case is, for example, AS65006 would prefer to send traffic to AS65005 only when the destination is in an AS directly connected to AS65005 itself while sending all other traffic through AS65004. This is common when one provider has good local and poor global coverage, while the other provider has good global but poor local coverage.
For instance, if AS65006 is in a somewhat isolated part of the world, such as some parts of the South Pacific or Central America, there may be a local provider, such as AS65004, that has solid connectivity to most of the other edge operators in the local geographic region but charges a high cost for transiting to the rest of the global Internet. A second provider, such as AS65005, charges less to reach destinations beyond the local geographic region but is relatively expensive to use when sending traffic to other edge operators within the local region.
Preference, by itself, would be difficult to use in this case, because the operator would need to distinguish between geographically local and geographically distant routes. To implement this kind of policy, the operator would accept partial routes from the geographically local provider (AS65004 in this case) and set a high preference for these routes. Partial routes are typically those the local provider learns only from other directly connected ASes, and hence would only include operators in the local geographic region. The operator would then accept full routes, or the entire Internet global routing table, from the second provider (AS65005 in this case) and set a lower preference.
An alternative way to implement geographic preference is using communities. Many transit providers mark individual reachable destinations with information about where the route originated. NTT, for instance, describes its geographic marking here. An operator can create filters using regular expressions to change the preference of a route based on its geographic origin.
This is not a common way to solve the problem because the filtering rules involved can become complex — but it might be deployed if local providers do not offer partial routes for some reason.
Another alternative to implementing geographic preference is to use a regular expression filter to set the preference for each reachable destination based on the length of the AS-PATH. Theoretically, routes originating within the local region should have an AS-PATH of one or two hops, while those originating outside a region should have a longer AS-PATH.
This generally does not work for two reasons. First, the average length of an AS-PATH (after prepending is factored out) is about four hops in the entire global Internet, and it’s easy to reach four hops even within a local region, in some situations. Second, many operators prepend the AS-PATH to manage inbound entry point preference; these prepended hops must be factored out to use this method.
From AS65004’s perspective
Transit providers primarily choose the most optimal exit from their AS to reduce the amount of peering settlement they are paying. They do this by using and maintaining settlement-free peering where possible and reducing the amount of time and distance traffic is carried through their network (through ‘hot potato’ routing, discussed in more detail below).
If, for instance, AS65004 has a paid peering relationship with AS65002 and a contract with AS65003 which is settlement-free, so long as the traffic between AS65004 and AS65003 is roughly symmetric, AS65004 has two roughly equal-cost paths (both have the same AS-PATH length) towards 100::/64. In this situation, AS65004 is going to direct traffic towards AS65003 to maintain symmetrical traffic flows and direct any remaining traffic towards AS65002.
This kind of balancing is normally done through a controller or network management system that monitors the balance of traffic with AS65003 and adjusts the sets of routes preference to attain the correct balance with AS65003 while reducing the costs of using the link to AS65002 to the minimum possible.
From AS65005’s perspective
AS65005 can either send traffic originating in AS65001, received from AS65002 and destined to AS65006, to either AS65004 (a peer) or AS65006 (a customer). The internal path between the entry point for this traffic is longer if the traffic is carried to AS65006, and shorter if the traffic is carried to AS65004. These longer and shorter paths give rise to the concepts of hot and cold potato routing.
If AS65006 is paying AS65005 for transit, AS65005 would normally carry traffic across the longer path to its border with AS65006. This is ‘cold potato’ routing. AS65005’s reason for choosing this option is to maximize revenue from the customer. First, as the link between AS65005 and AS65006 becomes busier, AS65006 is likely to upgrade the link, generating additional revenue for AS65005. Even if the traffic level is not increasing, steady traffic flow encourages the customer to maintain the link, which protects revenue. Second, AS65005 can control the quality-of-service AS65006 receives by keeping the traffic within its network for as long as possible, improving the customer’s perception of the service they are receiving.
Cold potato routing is normally implemented by setting the preference on routes learned from customers, so these routes are preferred over all routes learned from peers.
If AS6006 is not paying AS65005 for transit, it is to AS65005’s advantage to carry the traffic as short a distance as possible. In this case, although AS65005 is directly connected to AS65006, and the destination is in AS65006, AS65005 will choose to direct the traffic towards its border with AS65004 (because there is a valid route learned for this reachable destination from AS65004).
This is hot potato routing — like the kids’ game, you want to hold on to the traffic for as short an amount of time as possible. Hot potato routing is normally implemented by setting the preference on routes to the same and relying on the IGP metric component of the BGP bestpath decision process to find the closest exit point.
From AS65001’s perspective
Let’s assume AS65001 is some form of content provider, which means it offers a service such as bare metal compute, cloud services, search engines, social media, and so on. Customers from AS65006 are connecting to its servers, located on the 100::/64 network, which generates a large amount of traffic returning to the customers.
From the perspective of AS hops, it appears the path from AS65001 to AS65006 is the same length. If this is true, AS65001 does not have any reason to choose one path or another (given there is no measurable performance difference, as in the cases described above from AS65006’s perspective). However, the AS hop count does not accurately describe the geographic distances involved:
- The geographic distance between 100::/64 and the exit towards AS65003 is very short.
- The geographic distance between AS100::/64 and the exits towards AS65002 is very long.
- The total geographic distance packets travel when following either path is about the same.
In this case, AS65001 can either choose to hold on to packets destined for customers in AS65006 for a longer or shorter geographic distance.
While carrying the traffic over a longer geographic distance is more expensive, AS65001 would also like to optimize for the customer’s quality of experience (QoE), which means AS65001 should hold on to the traffic for as long as possible.
Because customers will use AS65001’s services in direct relation to their QoE (the relationship between service usage and QoE is measurable in the real world), AS65001 will opt to carry traffic destined to customers as long as possible — another instance of cold potato routing.
This is normally implemented by setting the preference for all routes equal and relying on the IGP metric part of the BGP bestpath decision process to control the exit point. Interior Gateway Protocol (IGP) metrics can then be tuned based on the geographic distance from the origin of the traffic within the network and the exit point closest to the customer.
An alternative, more active solution would be to have a local controller monitor the performance of individual paths to a given reachable destination, setting the preferences on individual reachable destinations and tuning IGP metrics in near-real-time to adjust for optimal customer experience.
Another alternative is to have a local controller monitor the performance of individual paths and use Multiprotocol Label Switching (MPLS), segment routing, or some other mechanism to actively engineer or steer the path of traffic through the network.
Some content providers may directly peer with transit and edge providers to reach customers more quickly, reduce costs, and increase their control over customer-facing traffic. For instance, if AS65001 is a content provider that transits traffic through 65002/65005 to reach customers in AS65006, to avoid transiting multiple ASes, AS65001 can run a link directly to AS65005.
In some cases, content providers will build long-haul fibre optics (including undersea cable operations, see this site for examples) to avoid transiting multiple ASes.
While the operator can end up paying a lot to build and operate long-haul optical links, this cost is offset by decreasing paying transit providers for high levels of asymmetric traffic flows. Beyond this, content providers can control user experience more effectively the longer they control the user’s traffic. Finally, content providers can gain more information by connecting closer to users, feeding into Kai-Fu Lee’s virtuous cycle.
Note: Content providers peering directly with edge providers and through IXPs is one component of the centralization of the Internet.
A failed alternative to the techniques described here was the use of automatic disaggregation at the content provider’s AS borders. For instance, if a customer is connected to a server in 100::/64 by sending traffic via the 65003/65001 link, an automated system will examine the routing table to see which route is currently being used to reach the customer’s reachable destination. If traffic forwarded to this customer’s address would normally pass through one of the 65001/65002 links, a local host route is created and distributed into AS65001 to draw this traffic to the exit connected to AS65003.
The theory behind this automatic disaggregation was that the customer will always take the shortest path from their perspective to reach the service. However, this assumption fails in practice so the scheme was ultimately abandoned.
In the next post in this series, I’ll look at where traffic should enter a network. Feel free to leave a comment if you have any questions.
Russ White is a Network Architect at LinkedIn.
This post is adapted from a series at Rule 11.
Discuss on Hacker NewsThe views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.