

The Forum of Incident Response and Security Teams (FIRST) holds an annual conference to promote coordination and cooperation among global Computer Security Incident Response Teams (CSIRTs). This year’s conference ran from 26 June to 1 July 2022, in Dublin, Ireland. These are Andrew Cormack’s notes on his own presentation and discussions on automated network/security management at the Academic SIG, #FIRSTCON22.
To help me think about automated systems in network and security management, I’ve put what seem to be the key points into a picture (below). In the middle is my automated network management or security robot. On the left are the systems the robot can observe and control and on the right are its human partner and the things they need.

Taking those in turn, to the left:
- The robot has certain levers it can pull. In network management, those might block traffic flows, throttle, or redirect them; in spam detection they might send a message to the inbox, the spambox, or direct to the bin. The first thing to think about is how those powers could go wrong, now or in the future. In my examples they could delete all mail or block all traffic. If that’s not okay, we need to think about additional measures to prevent it, or at least make it less likely (15).
- Then there’s the question of what data the robot can see, to inform its decisions on how to manipulate the levers. Can it see content, or just traffic data (the former is probably needed for spam; the latter is probably sufficient for at least some network management)? Does it need more or less information, for example, historic data or information from other components of the digital system? If it needs training, where can we obtain that data, and how often does it need updating? (10).
- Finally, we can’t assume that the world the robot is operating in is friendly, or even neutral. Could a malicious actor compromise the robot, or just create real or fake data to make it operate its levers in destructive ways? Why generate a huge DDoS flow if I can persuade an automated network defender to disconnect the organization for me? Can the actor test how the robot responds to changes, and thereby discover non-public information about our operations? Ultimately, an attacker could use their own automation to probe ours (15).
And, having identified how things could go wrong, on the right-hand side:
- What controls does the human partner need to be able to act effectively when unexpected things happen? Do they need to approve the robot’s suggestions before they are implemented (known as human-in-the-loop), or have the option to correct them soon afterwards? If the robot is approaching the limits of its capabilities, does the human need to take over, or enable a simpler algorithm or more detailed logging so that the event can be debugged or reviewed later? (14).
- And, what signals does the human need, to know when and how to operate their controls. This could include individual decisions, capacity warnings or metrics, alerts of unusual situations, and so forth. What logs are needed for subsequent review and debugging (12, 13)?
Having applied these questions to the familiar case of email filtering, they seem to be a helpful guide to achieving the most effective machine/human partnership.
Visualizing the draft EU Artificial Intelligence Act
Encouragingly, my operational thinking about automation seems to come up with a very similar list to the drafters of the EU AI Act. Formally, their requirements will only apply to “high-risk” AI, and it’s not yet clear whether network automation will fall into that category. But it’s always good when two very different starting points reach very similar conclusions — perhaps a useful ‘have I considered…?’ checklist, even if it’s not a legal requirement.
The text can be found below, but I’ve been using this visualization to explain to myself what’s going on. Article numbers are at what I think is the relevant point on the diagram (you may recognize them from the post above). Comments and suggestions very welcome!
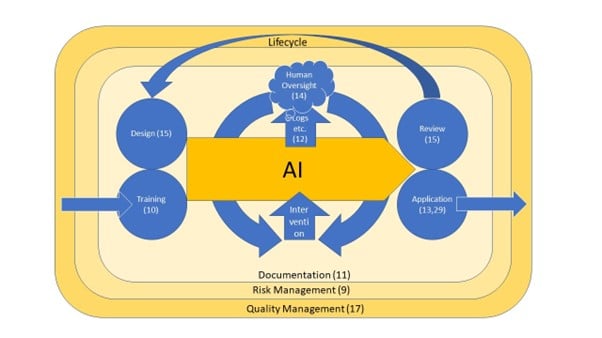
What the draft Act says (first sentence of each of the requirement Articles):
- Article 9: A risk management system shall be established, implemented, documented and maintained in relation to high-risk AI systems.
- Article 10: High-risk AI systems which make use of techniques involving the training of models with data shall be developed on the basis of training, validation and testing data sets that meet the quality criteria.
- Article 11: The technical documentation of a high-risk AI system shall be drawn up before that system is placed on the market or put into service and shall be kept up-to date (further detail in Article 18).
- Article 12: High-risk AI systems shall be designed and developed with capabilities enabling the automatic recording of events (‘logs’) while the high-risk AI systems is operating. Those logging capabilities shall conform to recognized standards or common specifications (obligations on retention in Article 20).
- Article 13: High-risk AI systems shall be designed and developed in such a way to ensure that their operation is sufficiently transparent to enable users to interpret the system’s output and use it appropriately.
- Article 14: High-risk AI systems shall be designed and developed in such a way, including with appropriate human-machine interface tools, that they can be effectively overseen by natural persons during the period in which the AI system is in use.
- Article 15: High-risk AI systems shall be designed and developed in such a way that they achieve, in the light of their intended purpose, an appropriate level of accuracy, robustness and cybersecurity, and perform consistently in those respects throughout their lifecycle.
- Article 17: Providers of high-risk AI systems shall put a quality management system in place that ensures compliance with this Regulation.
- Article 19: Providers of high-risk AI systems shall ensure that their systems undergo the relevant conformity assessment procedure in accordance with Article 43, prior to their placing on the market or putting into service.
- Article 29: Users of high-risk AI systems shall use such systems in accordance with the instructions of use accompanying the systems.
Before FIRSTCON2022, I had a fascinating chat with a long-standing friend/colleague Aaron Kaplan who knows far more about incident response technology than I ever did. The conclusions we reached were that using machine learning (ML) or AI in cyber defence will be a gradual journey that should benefit defenders at least as much as AI does attackers.
On the defender side, we can become more efficient by using ML decision support tools to free up analysts’ and incident responders’ time to do the sort of things that humans will always be best at, while exploring what aspects of active defences can be automated.
Of course, attackers will also get new tools too, but will likely lean toward mass attacks that are noisy. One of the few things I’ve always taken reassurance from is that a mass attack is easily detectable simply because it is mass. It might take us a while to work out what it is, but so long as we share information, that doesn’t seem impossible. That’s how spam detection continues to work, and I’d settle for that level of prevention for other types of attack!
Some organizations will, by their nature, be specific targets of particularly well-funded attackers who may use ML for precision. Those organizations need equivalent skills in their defenders. But for most of us our defences need to be good — say, a bit better than good practice — but probably not elite.
Andrew Cormack is Chief Regulatory Advisor at Jisc, and is responsible for keeping an eye out for places where our ideas, services and products might raise regulatory issues. Andrew ran the JANET-CERT and EuroCERT Incident Response Teams.
This post is adapted from posts at Jisc Blog.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.