

With so much traffic on the global Internet day after day, it’s not always easy to spot the occasional irregularity. After all, there are numerous layers of complexity that go into the serving of webpages, with multiple companies, agencies, and organizations each playing a role.
That’s why when something does catch our attention, it’s important that various entities work together to explore the cause and, more importantly, try to identify whether it’s a malicious actor at work, a glitch in the process, or maybe even something entirely intentional.
That’s what occurred last year when Internet Corporation for Assigned Names and Numbers (ICANN) staff and contractors were analysing names in Domain Name System (DNS) queries seen at the ICANN Managed Root Server, and the analysis program ran out of memory for one of their data files. After some investigating, they found the cause to be a very large number of mysterious queries for unique names including:
- f863zvv1xy2qf.surgery
- bp639i-3nirf.hiphop
- qo35jjk419gfm.net
- yyif0aijr21gn.com
While these were queries for names in existing Top-Level Domains (TLDs), the first label consisted of 12 or 13 random looking characters. After ICANN shared its discovery with the other root server operators, Verisign took a closer look to help understand the situation.
Exploring the mystery
One of the first things we noticed was that all these mysterious queries were name server (NS) type and came from one Autonomous System (AS) network, AS 15169, assigned to Google LLC. Additionally, we confirmed that it was occurring consistently for numerous TLDs, as per Figure 1.
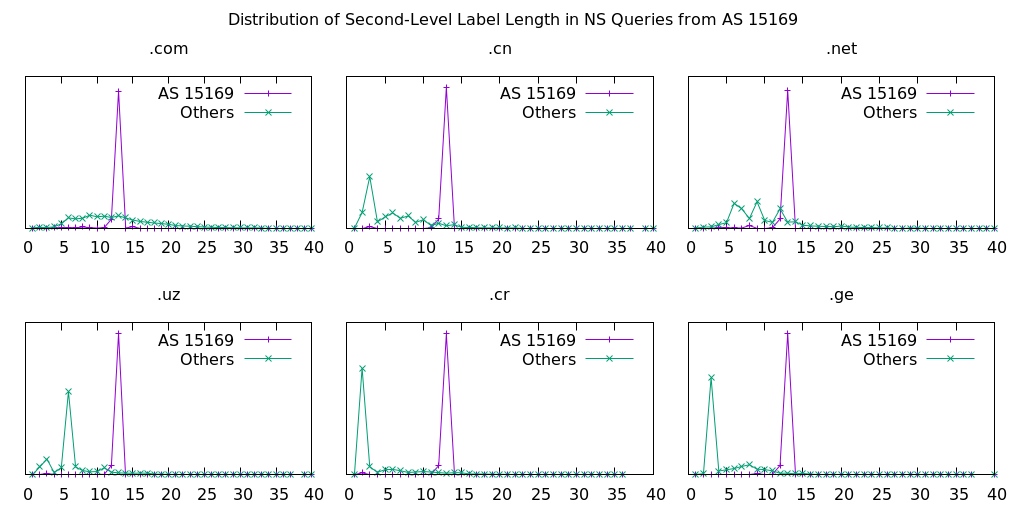
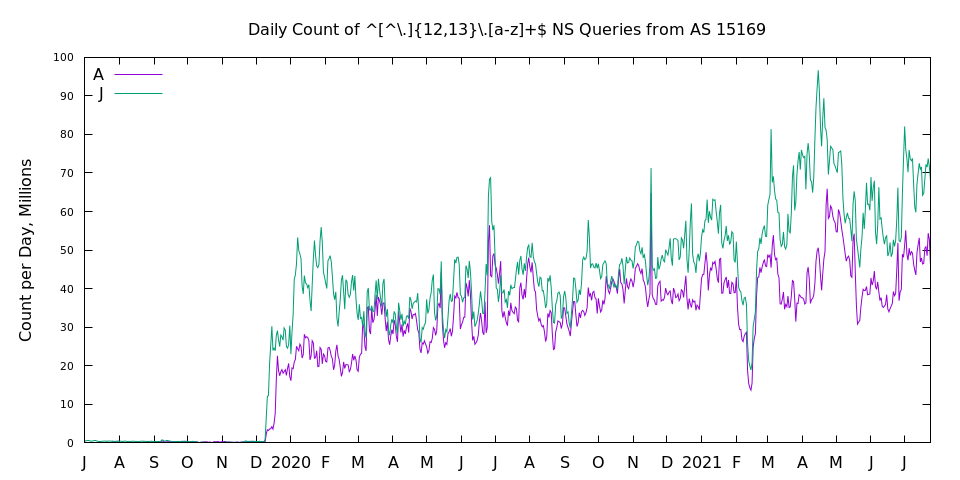
Although this phenomenon was newly uncovered, analysis of historical data (Figure 2) showed these traffic patterns began in late 2019.
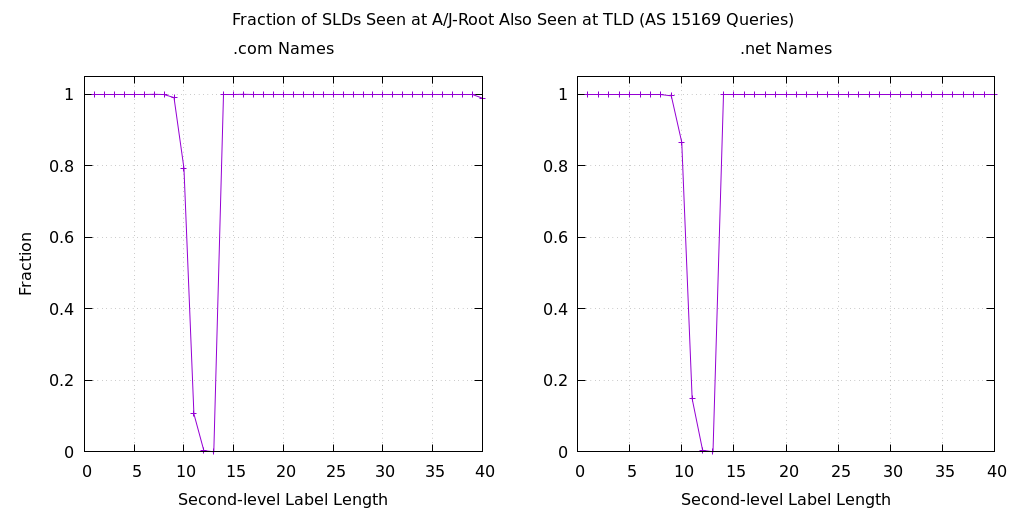
Perhaps the most interesting discovery was that these specific query names were not also seen at the .com and .net name servers operated by Verisign. The data in Figure 3 shows the fraction of queried names that appear at A-root and J-root and also appear on the .com and .net name servers. For second-level labels of 12 and 13 characters, this fraction was essentially zero. The graphs also show that there appear to be queries for names with second-level label lengths of 10 and 11 characters, which are also absent from the TLD data.
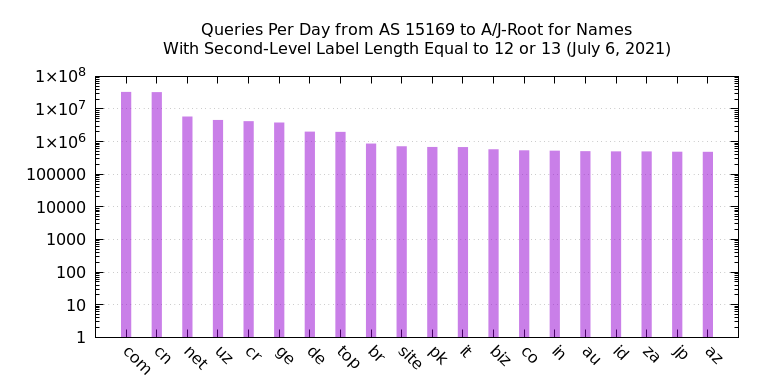
The final mysterious aspect of this traffic is that it deviated from our normal expectation of caching. Remember that these are queries to a root name server, which return a referral to the delegated name servers for a TLD. For example, when a root name server receives a query for yyif0aijr21gn.com, the response is a list of name servers that are authoritative for the .com zone. The records in this response had a Time to Live (TTL) of two days, meaning that the recursive name server can cache and reuse this data for that amount of time.
However, in this traffic (Figure 4), we saw queries for .com domain names from AS 15169 at the rate of about 30 million per day. It is well known that the Google Public DNS has thousands of backend servers and limits TTLs to a maximum of six hours. Assuming 4,000 backend servers each cached a .com referral for six hours, we might expect about 16,000 queries over 24 hours. The observed count is about 2,000 times higher by this back-of-the-envelope calculation.
From our initial analysis, it was unclear if these queries represented legitimate end user activity, though we were confident that source IP address spoofing was not involved. However, since the query names shared some similarities to those used by botnets, we could not rule out malicious activity.
The missing piece
We presented these findings last year at the DNS-OARC 35a virtual meeting. In the meeting chat room after the presentation, a participant proposed the missing piece of this puzzle: There is a Google webpage describing its public DNS service that talks about prepending nonce (meaning random) labels for cache misses increasing entropy. In what came to be known as ‘the Kaminsky Attack’, an attacker can cause a recursive name server to emit queries for names chosen by the attacker. Prepending a nonce label adds unpredictability to the queries, making it very difficult to spoof a response. Note that nonce prepending only works for queries where the reply is a referral.
In addition, Google DNS has implemented a form of query name minimization (see RFC 7816 and RFC 9156). As such, if a user requests the IP address of www.example.com and Google DNS decides this warrants a query to a root name server, it takes the name, strips all labels except for the TLD and then prepends a nonce string, resulting in something like u5vmt7xanb6rf.com. A root server’s response to that query is identical to one using the original query name.
The mystery explained
Now, we could explain nearly all the mysterious aspects of this query traffic from Google. We saw random second-level labels because of the nonce strings that are designed to prevent spoofing. The 12- and 13-character-long labels were most likely the result of converting a 64-bit random value into an unpadded ASCII label with encoding similar to Base32. We didn’t observe the same queries at TLD name servers because of both the nonce prepending and query name minimization. The query type is always NS because of query name minimization.
With that said, there was still one aspect that eludes explanation — the high query rate (2000x for .com) and apparent lack of caching. And so, this aspect of the mystery continues.
Wrapping up
Even though we haven’t fully closed the book on this case, one thing is certain — without the community’s teamwork to put the pieces of the puzzle together, explanations for this strange traffic may have remained unknown today.
The case of the mysterious DNS root query traffic is a perfect example of the collaboration that’s required to navigate today’s ever-changing cyber environment. We’re grateful and humbled to be part of such a dedicated community that is intent on ensuring the security, stability, and resiliency of the Internet, and we look forward to more productive teamwork in the future.
Duane Wessels is a Fellow at Verisign, with a focus on DNSSEC projects and root zone operations.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Could this be a way for a malign actor to move data from behind a firewall/dmz that would be otherwise undetectable unless specifically looking for it?
1) Could someone have set an AI,such as ChatGPT, on a task to find available or unregistered domains that might be sold at a discount in bulk for business purposes 2) Could the various AI and web brwosers be more utilized by the masses after massive security issues, which have settings trying to bypass Google’s Accelerated Mobile Pages to top level domains to ensure authentic content 3) Could someone have a script or an AI in trying to research data and content through Google in such a way that avoids Googles Search Engine Optimization methods, which would explain why bypassing cache were important because ithey/it wanted the information to be weighted equally and not based on traffic