

The Internet Routing Registry (IRR) and, more recently, Resource Public Key Infrastructure (RPKI) offer different solutions to improve routing security and operation in the Border Gateway Protocol (BGP).
IRR was first introduced in 1995 and remains a popular tool for BGP route filtering. However, route origin information in the IRR suffers from inaccuracies due to the lack of incentives for registrants to keep their information up to date and the lack of strict record verification processes by some IRR database providers.
RPKI, a system providing cryptographically attested route origin information, has become widely used for Route Origin Validation (ROV) among large networks. However, some networks are unwilling or unable to adopt RPKI filtering due to technical or administrative reasons. Such networks may not be able to construct correct routing filters due to IRR inaccuracies and thus compromise routing security.
In our paper, IRR Hygiene in the RPKI Era, we at CAIDA (UC San Diego), in collaboration with MIT, studied the scale of inaccurate IRR information by quantifying the inconsistencies between IRR and RPKI. In this post, we will succinctly explain how we compared records and then focus on the causes of such inconsistencies and provide recommendations on what operators could do to keep their IRR records accurate.
IRR and RPKI trends
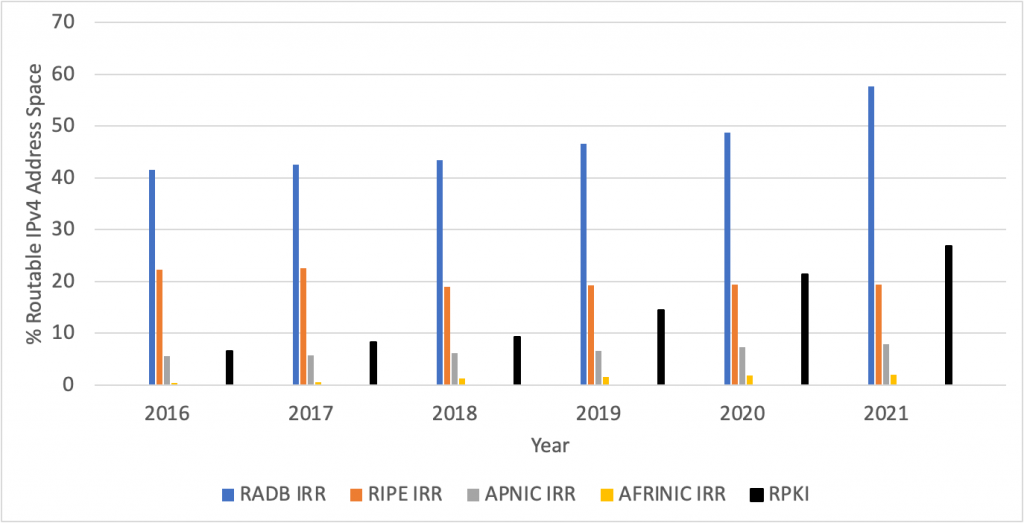
For our study, we downloaded IRR data from four IRR database providers — RADB, RIPE NCC, APNIC, and AFRINIC — and RPKI data from all Trust Anchors published by the RIPE NCC. Figure 1 shows IRR covers more IPv4 address space than RPKI, but RPKI has grown faster than IRR, having doubled its coverage over the past six years.
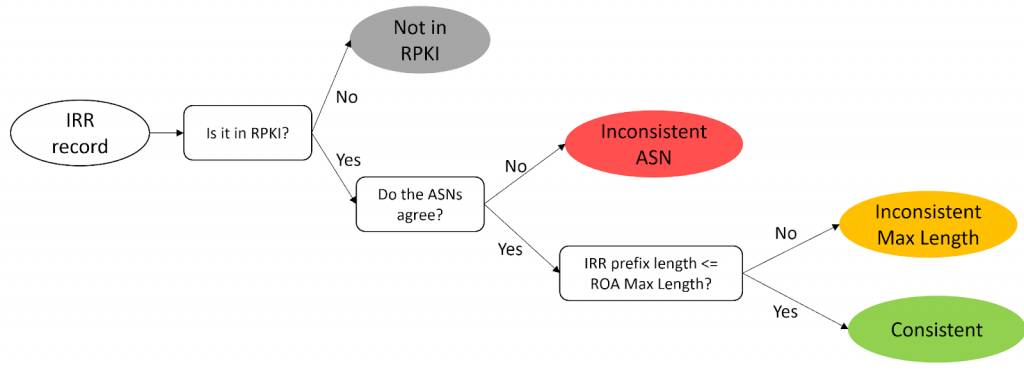
Checking the consistency of IRR records
Following the procedure in Figure 2, we classified IRR records into four categories:
- Not in RPKI: If the prefix in an IRR record has no matching or covering prefix in RPKI.
- Inconsistent ASN: If the IRR record has a matching RPKI record but none have the same Autonomous System Number (ASN).
- Inconsistent Max Length: If the IRR record has the same ASN as its matching RPKI record but the prefix length in the IRR record is larger than the maximum length (Max Length) field in the RPKI record.
- Consistent: If the IRR record has a matching RPKI record with the same ASN and Max Length attribute.
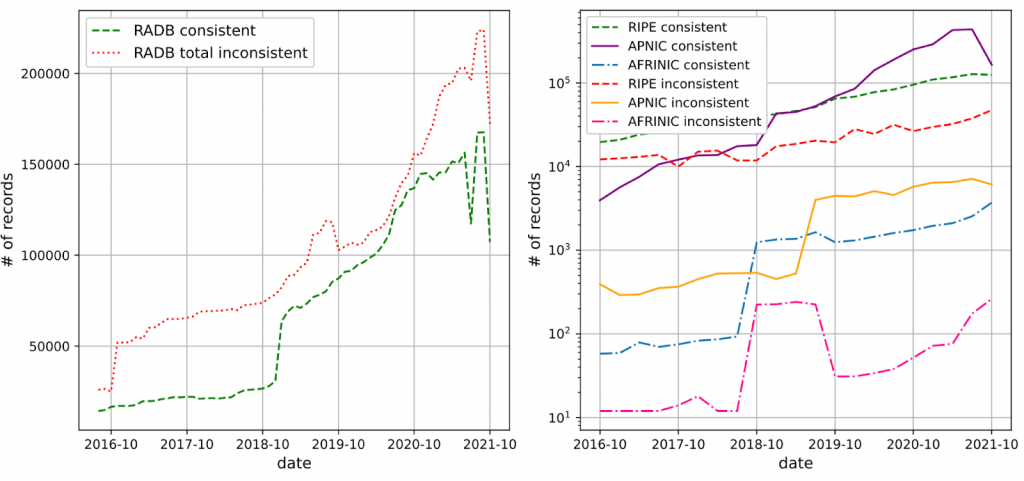
Which is more consistent? RADB vs RIPE, APNIC, AFRINIC
As of October 2021, we found only 38% of RADB records with matching RPKI records were consistent with RPKI, meaning that there were more inconsistent records than consistent records in RADB, see Figure 3 (left). In contrast, 73%, 98%, and 93% of RIPE, APNIC, and AFRINIC IRR records were consistent with RPKI, showing a much higher consistency than RADB, see Figure 3 (right).
We attribute the big difference in consistency to a few reasons:
- The IRR databases we collected from the Regional Internet Registries (RIRs) are their respective authoritative databases; the RIRs manage all the prefixes and verify the registration of IRR objects with address ownership information. This verification process is stricter than RADB and leads to a higher quality of IRR records.
- APNIC provides its registrants with a management platform that automatically creates IRR records for a network when it registers its prefixes in RPKI. This platform contributes to a larger number of consistent records compared to other RIRs.
What caused the inconsistency?
In our analysis, we found different causes for the different types of inconsistency, including:
- Inconsistent Max Length records, which were mostly caused by IRR records that are too specific (see the example in Figure 4), and to a lesser extent by misconfigured Max Length attributes in RPKI.
- Inconsistent ASN records, which were largely caused by customer networks failing to remove records after returning address space to their provider network (see the example in Figure 5).


How should we improve IRR accuracy?
Although RPKI is becoming more widely deployed, we do not see a decrease in IRR usage, and therefore we should work towards improving its accuracy. To do so, we suggest that networks keep their IRR information up to date and IRR database providers implement policies that promote good IRR hygiene, such as removing RPKI inconsistent records regularly.
Further, networks currently using IRR for route filtering can avoid the negative impact of inaccurate IRR information by using IRRd version 4, which validates IRR information against RPKI, to ignore incorrect IRR records.
Contributors: Cecilia Testart
Ben Du is a PhD student in the Center for Applied Internet Data Analysis (CAIDA) group at UC San Diego.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
very good explanation! let me make clear the difference between RADB with RPKI.
Thank you very much!