

In our previous post on using eXpress Data Path (XDP) for DNS, we discussed how a new XDP rate-limiting queries feature can augment a DNS service running in user space (with common DNS software) to deal with denial of service (DoS) attacks.
Read: Journeying into XDP: Part 0
Read: Journeying into XDP: Augmenting the DNS
Doing this rate-limiting at the earliest stage (just after the query arrives) makes a lot of sense, even when the DNS service in user space has the feature too because it saves the server from spending a lot of useless cycles on processing packets that will be discarded (or replied to without looking up an answer with the TrunCated (TC) bit set) anyway.
In this post, we will take this ‘augmenting the DNS service’ paradigm one step further and look at adding DNS features that are not limited to dealing with incoming requests only but also impact outgoing packets.
The first feature that we’ll be examining is DNS Cookies, which is an in-DNS-protocol way of allowlisting returning requesters to exclude them from being rate limited. And, although DNS Cookies have an outgoing component, we consider dealing with that in the extended Berkeley Packet Filter (BPF) beyond the point where a full BPF implementation is beneficial and justified. Instead, we showcase the principle of a fully-fledged DNS feature that touches both incoming and outgoing packets with a BPF native implementation for EDNS(0) Padding in response to a user request for that feature.
DNS Cookies 101
Quoting RFC 7873, DNS Cookies are ‘a lightweight DNS transaction security mechanism specified as an OPT option.’ In short, cookies provide protection similar to using TCP as the transport for DNS and mitigate (to a large extent) spoofed queries among other malicious practices.
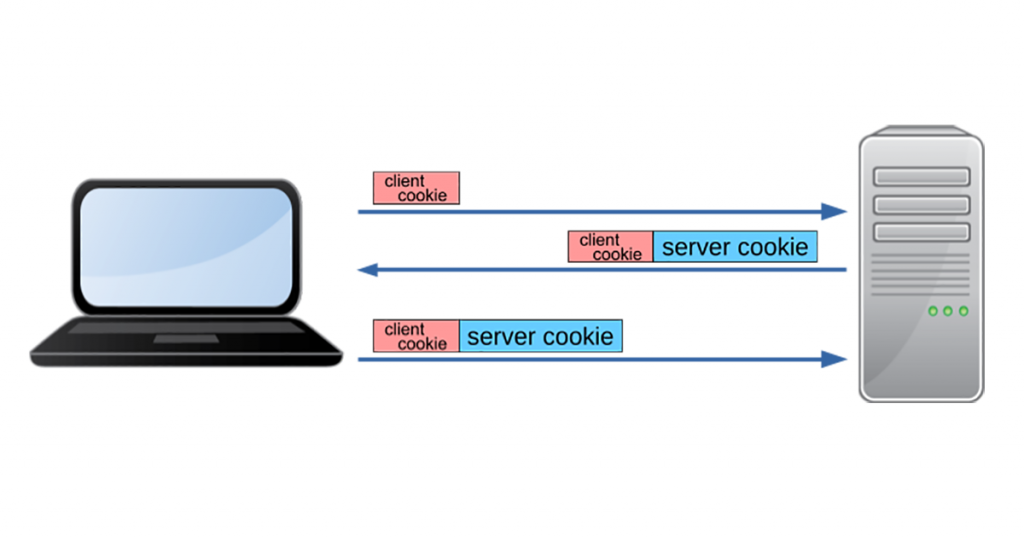
How does this work? DNS servers include a server cookie in responses to clients that had a client cookie included in the request. The client will include the server cookie in all subsequent requests to that same server. If a (benign) requester can indicate there was prior communication by including a valid server cookie, the server can decide (based on local policy) to exclude these queries from rate-limiting and allow queries for large answers. When under heavy load, this provides an easy way to discard the share of traffic that is presumably illegitimate.
DNS Cookies were first specified in RFC 7873, which has been updated by RFC 9018 with a fixed recipe for creating server cookies. BIND from version 9.16, Knot DNS from version 2.9.0 and NSD as of version 4.3.7 all follow the new recipe for baking server cookies, which is as follows:
A client cookie is just 64 bits of entropy, drawn uniquely for each server the client is contacting. Upon receiving a query with a client cookie, the server constructs the server cookie as follows:
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Version | Reserved | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Timestamp | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Hash | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Hash is calculated as follows:
Hash = SipHash-2-4(
Client Cookie | Version | Reserved | Timestamp | Client-IP,
Server Secret )
The server cookie is then included in the first response for the client, to be cached and used in future queries. In case the source IP address of the query was spoofed, that server cookie never ends up at the actual (malicious) originator of the query, and thus that requester cannot signal the server of the prior communication.
Why and how we must do cookies in XDP
If we rate-limit queries in XDP (as described in the previous blog post), we have to check DNS Cookies on incoming queries in XDP as well. After all, if we leave the cookie functionality to the user space software, we’ve already passed the XDP layer performing the rate-limiting for us and it cannot be bypassed for queries with a valid server cookie.
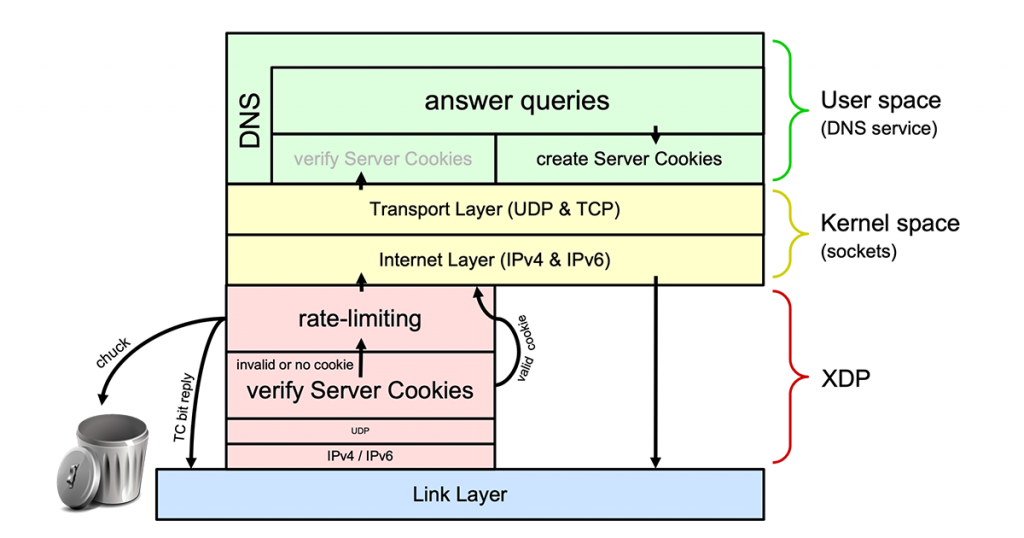
Our XDP implementation of DNS Cookie verification can be found at the GitHub repo in the Cookies subdirectory. This implementation builds forth on a fully-fledged, rate-limiting implementation with all the features found in DNS software rate-limiting implementations (such as the length of prefixes to be rate-limited and slip rate). A user space program (called xdp_rrl_vipctl) is included to manage the ‘Very Important Prefixes’ list that should not be rate-limited. The code snippets below are all from this XDP DNS Cookies implementation.
SipHash
The verification process of cookies should be functioning as expected. Introducing a significant delay just for cookies is not something many operators would appreciate. SipHash fits the bill when it comes to fast, deterministic pseudorandom functions, but how can we use that in XDP?
The Linux kernel does include an implementation, but we can’t use any libraries from BPF. So as long as there is no BPF-helper available, we have to implement SipHash ourselves in BPF. It turned out the Bernstein/Aumason implementation was perfect for this with a few small alterations restricting the input sizes to the sizes being used in DNS Cookies.
Pleasing the verifier
A DNS server cookie is among one of the Option Resource Records (OPT RRs) in the additional section of a DNS message. The OPT RR is the last RR of the DNS message, except for the transaction signature (TSIG), which, if present, comes after the OPT RR. Though, for queries, it is also the very first RR right after the query.
So, to get to the OPT RR, we only have to skip the query (as we did with ‘DNS-says-no’ in our first blog post).
815: if (md->eth_proto == __bpf_htons(ETH_P_IPV6)) {
816: if (!(ipv6 = parse_ipv6hdr(&c))
817: || !(ipv6->nexthdr == IPPROTO_UDP)
818: || !(udp = parse_udphdr(&c))
819: || !(udp->dest == __bpf_htons(DNS_PORT))
820: || !(dns = parse_dnshdr(&c)))
821: return XDP_PASS; /* Not DNS */
822:
823: // search for the prefix in the LPM trie
824: struct {
825: uint32_t prefixlen;
826: struct in6_addr ipv6_addr;
827: } key6 = {
828: .prefixlen = 64,
829: .ipv6_addr = ipv6->daddr
830: };
831: // if the prefix matches, we exclude it from rate limiting
832: if ((count=bpf_map_lookup_elem(&exclude_v6_prefixes, &key6))) {
833: lock_xadd(count, 1);
834: return XDP_PASS;
835: }
836: if (dns->flags.as_bits_and_pieces.qr
837: || dns->qdcount != __bpf_htons(1)
838: || dns->ancount || dns->nscount
839: || dns->arcount > __bpf_htons(2)
840: || !skip_dname(&c)
841: || !parse_dns_qrr(&c))
842: return XDP_ABORTED; // Return FORMERR?
843:
In the code snippet above (from int xdp_dns_cookies(struct xdp_md *ctx), the main XDP function), we skip over the query dname and the query RR (basically the class and the type) on lines 840 and 841. Note that we abort processing the packet at line 843 if it is not a valid DNS query (that is, it has the QR bit set, contains a single query, has no answers or RRs in the authority section, has no more than two RRs in the additional section (one OPT and/or one TSIG) and contains a valid query). Checking if the source address is on the Very Important Prefixes list happened right before that (from lines 823 to 835).
The following code snippet shows how to implement skipping the query dname:
442: static inline
443: uint8_t *skip_dname(struct cursor *c)
444: {
445: uint8_t *dname = c->pos;
446: uint8_t i;
447:
448: for (i = 0; i < 128; i++) { /* Maximum 128 labels */
449: uint8_t o;
450:
451: if (c->pos + 1 > c->end)
452: return 0;
453:
454: o = *(uint8_t *)c->pos;
455: if ((o & 0xC0) == 0xC0) {
456: /* Compression label is last label of dname. */
457: c->pos += 2;
458: return dname;
459:
460: } else if (o > 63 || c->pos + o + 1 > c->end)
461: /* Unknown label type */
462: return 0;
463:
464: c->pos += o + 1;
465: if (!o)
466: return dname;
467: }
468: return 0;
469: }
This function permits query names of 128 labels, where each label has the maximum size of 63 bytes, totalling an 8,192-byte dname (where the DNS spec allows dnames to be 255 bytes max!). And, because the code allows it, the verifier assumes those dnames are always 8,192 bytes long. And, even though we ensure that we will not read beyond the packet — by making sure c->pos remains below c->end — the accumulated (size-wise) worst cases scenarios can quickly lead to a situation where the verifier conceives the program to cross the maximum allowed packet size of 64k and will, therefore, refuse to load the XDP program!
In short, the amount of variable length fields in packets that the XDP verifier allows is restricted by the potential maximum length of those fields. The verifier assumes all those fields have the maximum length! The verifier assumes our DNS packet is already more than 8k by just skipping a single dname! While realistically we only need to deal with DNS messages that will have 1,472 bytes max (an MTU of 1,500 minus a 20-byte IPv4 header and a 8-byte UDP header)!
Luckily we found a way around this. We can save the current position in the packet as an offset from the start of the packet in the packet’s ‘metadata’, and jump to another separately verified XDP program with a bpf_tail_call(). This other program can then take the offset, but only advance the cursor with it if the offset means that the query name is not larger than 255 bytes.
This is exactly what is happening on lines 852 and 853 of the code snippet below, which is the continuation of the first code snippet. Note that we also jump directly to the XDP program, which does the rate-limiting if there is no OPT RR in the additional section on lines 844 to 847.
844: if (dns->arcount == 0) {
845: bpf_tail_call(ctx, &jmp_table, DO_RATE_LIMIT_IPV6);
846: return XDP_PASS;
847: }
848: if (c.pos + 1 > c.end
849: || *(uint8_t *)c.pos != 0)
850: return XDP_ABORTED; // Return FORMERR?
851:
852: md->opt_pos = c.pos + 1 - (void *)(ipv6 + 1);
853: bpf_tail_call(ctx, &jmp_table, COOKIE_VERIFY_IPv6);
The COOKIE_VERIFY_IPv6 program in the code snippet below is the BPF program that is called by the bpf_tail_call, and is conveniently verified separately. The position of the cursor below is increased (at line 676) with md->opt_pos, but md->opt_pos is not allowed to be larger than 320 (IPv6 header(40) + UDP header(8) + DNS header (12) + max qname (255) + class(2) + type(2)). After the tail call, the verifier considers the OPT RR to be at position 344 in the packet instead of at a position of more than 8,000 (in the caller program). We have much more room now to search for the cookie in the variable-length options.
659: SEC("xdp-cookie-verify-ipv6")
660: int xdp_cookie_verify_ipv6(struct xdp_md *ctx)
661: {
662: struct cursor c;
663: struct meta_data *md = (void *)(long)ctx->data_meta;
664: struct ipv6hdr *ipv6;
665: struct dns_rr *opt_rr;
666: uint16_t rdata_len;
667: uint8_t i;
668:
669: cursor_init(&c, ctx);
670: if ((void *)(md + 1) > c.pos || md->ip_pos > 24)
671: return XDP_ABORTED;
672: c.pos += md->ip_pos;
673:
674: if (!(ipv6 = parse_ipv6hdr(&c)) || md->opt_pos > 4096)
675: return XDP_ABORTED;
676: c.pos += md->opt_pos;
Similarly, the maximum number of options in an OPT RR is restricted to 10 (at line 683) and the maximum length of each option is restricted to 1,500 (at line 707) in the second half of the function below. This way the maximum amount of space an OPT RR can take in our program, and which the verifier will assume the OPT RR will take, is 15,000 (10 * 1,500), which is well within the limits of the 64k maximum packet size.
678: if (!(opt_rr = parse_dns_rr(&c))
679: || opt_rr->type != __bpf_htons(RR_TYPE_OPT))
680: return XDP_ABORTED;
681:
682: rdata_len = __bpf_ntohs(opt_rr->rdata_len);
683: for (i = 0; i < 10 && rdata_len >= 28; i++) {
684: struct option *opt;
685: uint16_t opt_len;
686:
687: if (!(opt = parse_option(&c)))
688: return XDP_ABORTED;
689:
690: rdata_len -= 4;
691: opt_len = __bpf_ntohs(opt->len);
692: if (opt->code == __bpf_htons(OPT_CODE_COOKIE)) {
693: if (opt_len == 24 && c.pos + 24 <= c.end
694: && cookie_verify_ipv6(&c, ipv6)) {
695: /* Cookie match!
696: * Packet may go staight up to the DNS service
697: */
698: DEBUG_PRINTK("IPv6 valid cookie\n");
699: return XDP_PASS;
700: }
701: /* Just a client cookie or a bad cookie
702: * break to go to rate limiting
703: */
704: DEBUG_PRINTK("IPv6 bad cookie\n");
705: break;
706: }
707: if (opt_len > 1500 || opt_len > rdata_len
708: || c.pos + opt_len > c.end)
709: return XDP_ABORTED;
710:
711: rdata_len -= opt_len;
712: c.pos += opt_len;
713: }
714: bpf_tail_call(ctx, &jmp_table, DO_RATE_LIMIT_IPV6);
715: return XDP_PASS;
716: }
Lessons learned:
- Hard size limits on variable-length fields are necessary to keep the potential packet size below 64k. The verifier will reject loading an XDP/BPF program that can potentially exceed this limit.
- We can restrict the accumulated potential packet size by reverifying a position after a bpf_tail_call. We were able to restrict the qname from 128 labels of max 64 bytes (8k in total) to the maximum allowed 255 bytes.
One last remark: bpf_tail_call use a special BPF MAP type, BPF_MAP_TYPE_PROG_ARRAY, that needs to be filled with indexes to the different BPF programs. For XDP this needs to be done by a separate user space loader program:
Fully-fledged DNS augmentation
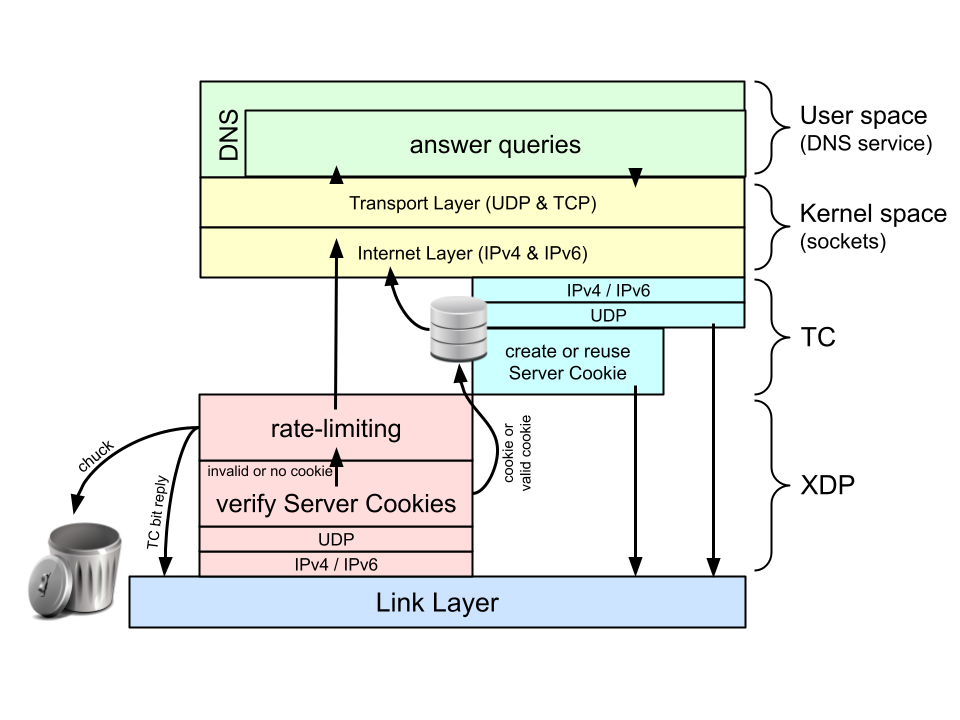
Stating that ‘XDP only works for ingress packets’ might be confusing, as we did send out packets from the XDP layer in our first two blog posts. However, those outgoing packets were always adaptations of a packet that just came in. For example, in our very first DNS-says-no program, we swapped addresses, flipped some bits and took some bytes away. But the response was entirely based on the request itself.
At the time of writing, ‘XDP on egress’ is not possible with the Linux kernel. For properly answered queries, we rely on the user space software, so the response that needs to go out of the network interface eventually will come from above. Luckily, we can execute BPF code at the Traffic Control (TC) layer, just one layer up from the XDP layer.
So we have access to both incoming and outgoing traffic from BPF! Excellent! 🎉 Nothing can stop us from writing a BPF DNS proxy to do the following, right?
- Take a DNS request.
- Verify the DNS cookie.
- Send the request up to the user space DNS service for it to be answered.
- Take the response from the user space service and modify it (adding or reusing a verified cookie) before sending it back out on the network.
We have the power of DNSdist, but then in kernel space, right?
Unfortunately, that’s not possible. The BPF program for incoming packets, and the BPF program for outgoing packets, are two completely separate programs that do not share anything at all, and certainly no stack 😞. The BPF program on the TC layer doesn’t even get just DNS responses! It gets all outgoing traffic and has to parse all the Ethernet, IP, UDP and DNS headers again to identify the DNS responses it needs to act upon 😝.
So, is it at all possible to do a fully-fledged DNS augmentation?
Actually yes! But you are losing a lot of the ‘power’ that comes naturally with BPF. The trick is to save the state that needs to be shared with the BPF program at the TC layer in a BPF map indexed by the things that identify the request (that is, the source UDP port, query ID and query name).
On the TC layer, we can look up this state by destination UDP port, query ID and query name. The BPF_MAP_TYPE_LRU_HASH type fits the bill perfectly. (Note: LRU stands for Least Recently Used). A map of this type has a fixed size and has an excellent short term memory (for the just-arrived requests), but automatically removes old stuff (the already answered responses — or the state for the requests that never resulted in a response).
Fully-fledged — Is it worth it?
One of the big benefits of using BPF at the XDP layer is that everything can be dealt with right on packet reception without prior and/or further interaction with the rest of the computer system. This is no longer the case if we’re going to share state between BPF programs. We cannot use the PER_CPU map types for storing the state, because there is no guarantee that the BPF program on the outgoing TC layer will run on the same CPU as the XDP program receiving the request initially.
Note: User space services do not have this issue! A user space service can verify and store the incoming DNS Cookie, process the request, and create a response with a reused or fresh server DNS Cookie all in the same thread! This is why we refrained from doing a fully-fledged DNS Cookie implementation in XDP and stuck with verification of DNS Cookies only.
So, is it never worth doing a fully-fledged DNS augmentation in BPF? No. There may be cases for which no shared state is needed or the state can be deduced from the response. For example, directing incoming requests to an authoritative or recursive service based on the value of the Recursion Desired (RD) bit.
Also, there may be administrative reasons to want to extend an existing DNS service with a feature. For example, the user space software may not support the feature at all, or you may want to have uniform administration of the feature amongst a pool of DNS services running different user space software.
A proof of concept fully-fledged DNS augmentation with BFP: EDNS0 padding
NLnet Labs’ recursive resolver software, Unbound, has supported DNS over TLS (DoT) for a long time. But even on an encrypted channel, an on-path eavesdropper may be able to deduce what’s going on from the packet sizes. So, for proper DoT, the requests and responses need to be padded to fixed block sizes.
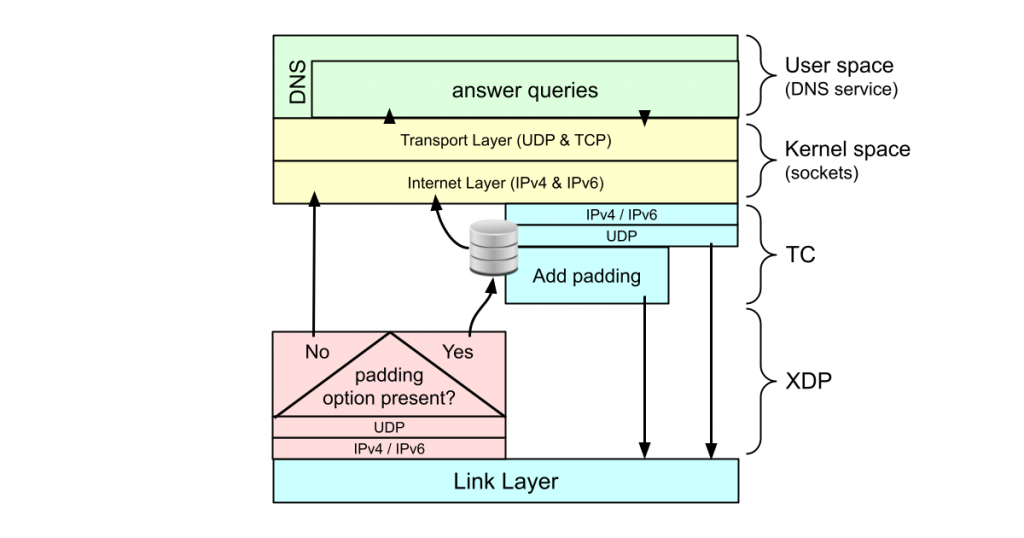
Padding in DoT is done with yet another EDNS0 option described in RFC 7830 (and some recommendations for padding sizes in RFC 8467). Unbound has supported this since version 13.1.
Padding in Unbound is only done on TLS transport because we don’t want this option to increase just any UDP response so it can be misused in Denial of Service Amplification attacks. However, while developing this feature in Unbound, an Unbound user requested to have it available without TLS as well, because, in their setup, DoT is terminated with DNSdist, which in turn, forwards the queries to the resolver pool over UDP. This justified for us a fully-fledged EDNS0 padding implementation in BPF and we have it included in our XDPeriments repo.
021: #define PAD_SIZE 468
022:
023: struct bpf_elf_map jmp_map SEC("maps") = {
024: .type = BPF_MAP_TYPE_PROG_ARRAY,
025: .id = 1,
026: .size_key = sizeof(uint32_t),
027: .size_value = sizeof(uint32_t),
028: .pinning = PIN_GLOBAL_NS,
029: .max_elem = 2,
030: };
031:
032: SEC("1/0")
033: int tc_edns0_padding_egress(struct __sk_buff *skb)
034: {
035: struct cursor c;
036: uint16_t eth_proto;
037: struct ethhdr *eth;
<snip>
145: SEC("1/1")
146: int skip_resource_records(struct __sk_buff *skb)
147: {
148: struct cursor c;
149: uint8_t *dname;
BPF programs on the TC layer are loaded with the tc command from iproute2. Map definitions are slightly different (with a struct bpf_elf_map) from what we’ve seen before (with struct bpf_map_def) and specific for iproute2 based loaders (such as tc). The attribute names for keys and values are slightly different from those map definitions (size_key and size_value instead of key_size and value_size for example). More importantly, they have some additional possible attributes that greatly help out in loading a program and knotting together all the pieces.
The pinning attribute makes sure the BPF_MAP_TYPE_PROG_ARRAY is loaded persistently and has a presence in the /sys/fs/bpf filesystem (that tc will automatically mount if it was not already mounted). Furthermore, because the map has attribute id set to 1, the tc bpf loader will automatically fill the map with programs with specially named sections. In the example above, the tc_edns0_padding_egress() function/program is automatically added to jmp_map at key 0 because it is in a section named 1/0 (that is, <id of the map> / <key in the map> ). Similarly, the skip_resource_records() function/program is automatically loaded in at key 1. This allows us to fill a BPF_MAP_TYPE_PROG_ARRAY without a specially crafted loader program that needs to keep running to keep the BPF_MAP_TYPE_PROG_ARRAY alive.
It is also possible to have multiple BPF programs at the TC layer (instead of a single one at the XDP layer). This added flexibility makes loading a BPF program with tc a bit more involved though — you have to create and associate a so-called ‘qdisc’ with a network device first and then add the program as a so-called ‘filter’ to that qdisc. We have provided a Makefile target ‘load’ to do it for you and get you started:
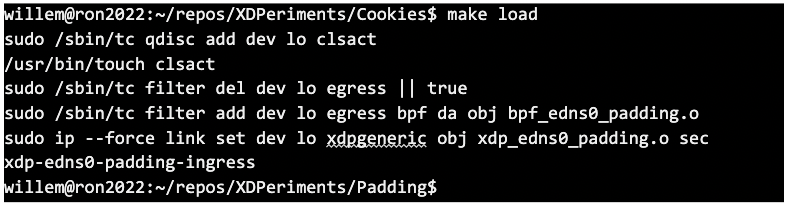
Now, if you have a DNS service listening on localhost, you can see padding with BPF in action:
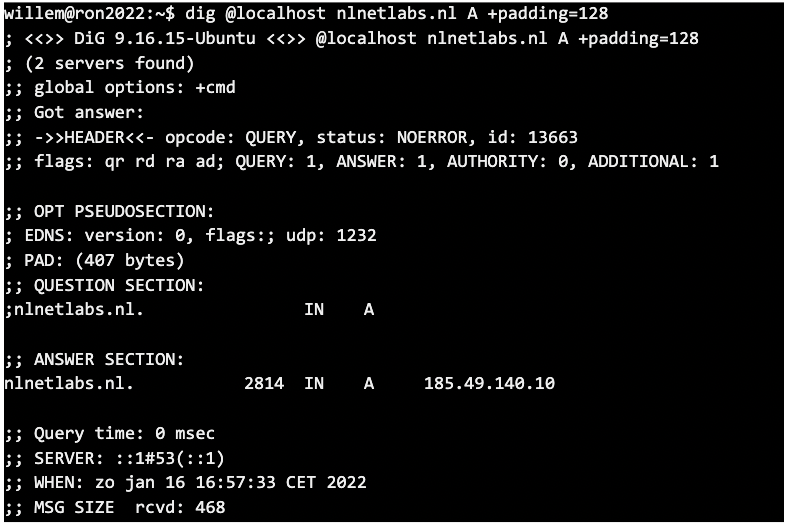
It works! 🎉
Lessons learned
Fully-fledged DNS service augmentation is possible by using two cooperating BPF programs: One at the XDP layer for incoming requests, and one at the TC layer for outgoing responses.
If performance gain is the prime motivation to handle a (fully-fledged) DNS feature in BFP, then an implementation may not be worth it. This is because it needs an additional mutex lock for sharing the state between the BPF program for incoming requests, and the one for outgoing responses — a lock that you would not need in a user space implementation.
The traffic control tools allow you to conveniently autoload and pin a BPF_MAP_TYPE_PROG_ARRAY, so you do not need a running program to keep that map persistent.
Next up: DNS telemetry
In our next post, we will look into a passive program that does not alter any packets but merely reports on them — BPF-based DNS telemetry — and how it enables us to plot graphs of DNS metrics without touching the DNS software itself.
Contributors: Tom Carpay, Luuk Hendriks
Willem Toorop is a researcher and developer at NLnet Labs.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Nice article William.
One question. RFC7873 section 5.4 allows for a query with qdcount == 0. I confess I have never seen such a query in the wild, but it is allowed.
Does this mean that line 837 of your BPF program needs to be a bit more flexible? Perhaps <= 1?
Hey Mark! Good catch! I forgot all about the use-case of just learning the Server Cookie!
We need a bit more than just changing the qdcount comparison, we also must make sure to not skip the query dname and the query rr when qdcount == 1, so something like this perhaps:
836: if (dns->flags.as_bits_and_pieces.qr
837: || dns->qdcount > __bpf_htons(1)
838: || dns->ancount || dns->nscount
839: || dns->arcount > __bpf_htons(2)
840: || (dns->qdcount && ( !skip_dname(&c)
841: || !parse_dns_qrr(&c))))
842: return XDP_ABORTED; // Return FORMERR?
But ideally we have to make sure that in such case a Client Cookie is present as well, as otherwise such queries would still be illegal according to https://www.rfc-editor.org/rfc/rfc1035#section-4.1.2 ). I’ll have a look if I can fix that in the repo.
Thanks for pointing this out! Much appreciated!
Hi Willem,
About the following content,
”
If performance gain is the prime motivation to handle a (fully-fledged) DNS feature in BFP, then an implementation may not be worth it. This is because it needs an additional mutex lock for sharing the state between the BPF program for incoming requests, and the one for outgoing responses — a lock that you would not need in a user space implementation.
”
Why not use TC layer for both ingress and egress, to avoid shared lock? Would the performance be better in this way?
Thanks!
Thanks Marcus, that may well be!
I haven’t looked at it (yet). You would still need two programs (one for incoming queries and one for the outgoing responses), but it may well be that state linking those incoming queries to the outgoing responses would be more easily shared in the socket buffer then yes. I’ll make a note and let you know as soon as I’ve tried.
That’s great! Thanks.