

During the last several years, there have been many advances made to understand privacy issues in the Domain Name System (DNS) and attempts to address them by deploying new protocols and tools.
While the main focus has been mitigating privacy risks in DNS requests performed by end–users, there are other challenges such as information leaking due to the behaviour of an institution’s DNS traffic as a whole.
- Institutional privacy risks are prevalent in the DNS. Mail exchange queries made by mail servers and DNSBL queries made by anti-spam services are two easily accessible sources used to discover email related activity.
- Institutions that run their own recursive resolvers and have an assigned Autonomous System from which their traffic routes are most susceptible to these threats.
- Prefix-preserving IP anonymization methods currently used when sharing DNS data are not sufficient to mitigate the risks.
Recursive servers aggregate DNS traffic but those servers may leak information about the organization, even if queries cannot be traced to specific end-users. It is enough to know from which institution’s recursive resolver a query came from. With this knowledge, an observer can see traffic from the resolver (perhaps by looking at traffic in the WAN, or at an authoritative server), observe the institution’s DNS traffic, and possibly learn confidential or sensitive information about the institution.
Previous research generally assumed there was minimal privacy risk at authoritative servers. We at the University of Southern California recently uncovered such institutional privacy risks in data collected at an authoritative server. We’ve shown that it’s possible to learn whether two companies are talking to each other, or if employees of a company are visiting sites that may be considered sensitive from the company’s perspective.
To determine how serious the risks are, we performed a measurement study using one week of anonymized B-Root data from January 2019. We analyzed queries from 66 large institutions that represent a diverse set of sectors, including universities, government agencies, and airlines. Our results show that institutional privacy risks are prevalent in the DNS and that current prefix-preserving IP anonymization methods used when sharing DNS data are not sufficient to mitigate the risks.
DNS queries may leak institutional information
We focused on two categories of queries that leak information about institutions.
The first category is email related queries that may reveal communication patterns between institutions. Two types of queries can leak email related activity: Mail exchange (MX) queries made by mail servers, and DNSBL queries made by anti-spam services. Both types of queries have been studied before but our research took a new approach in studying their institutional privacy risks.
After analyzing one week of B-Root data, we found several million MX and DNSBL queries were made each day, as shown in Figure 1. This can be a significant source of email related activity leakage.
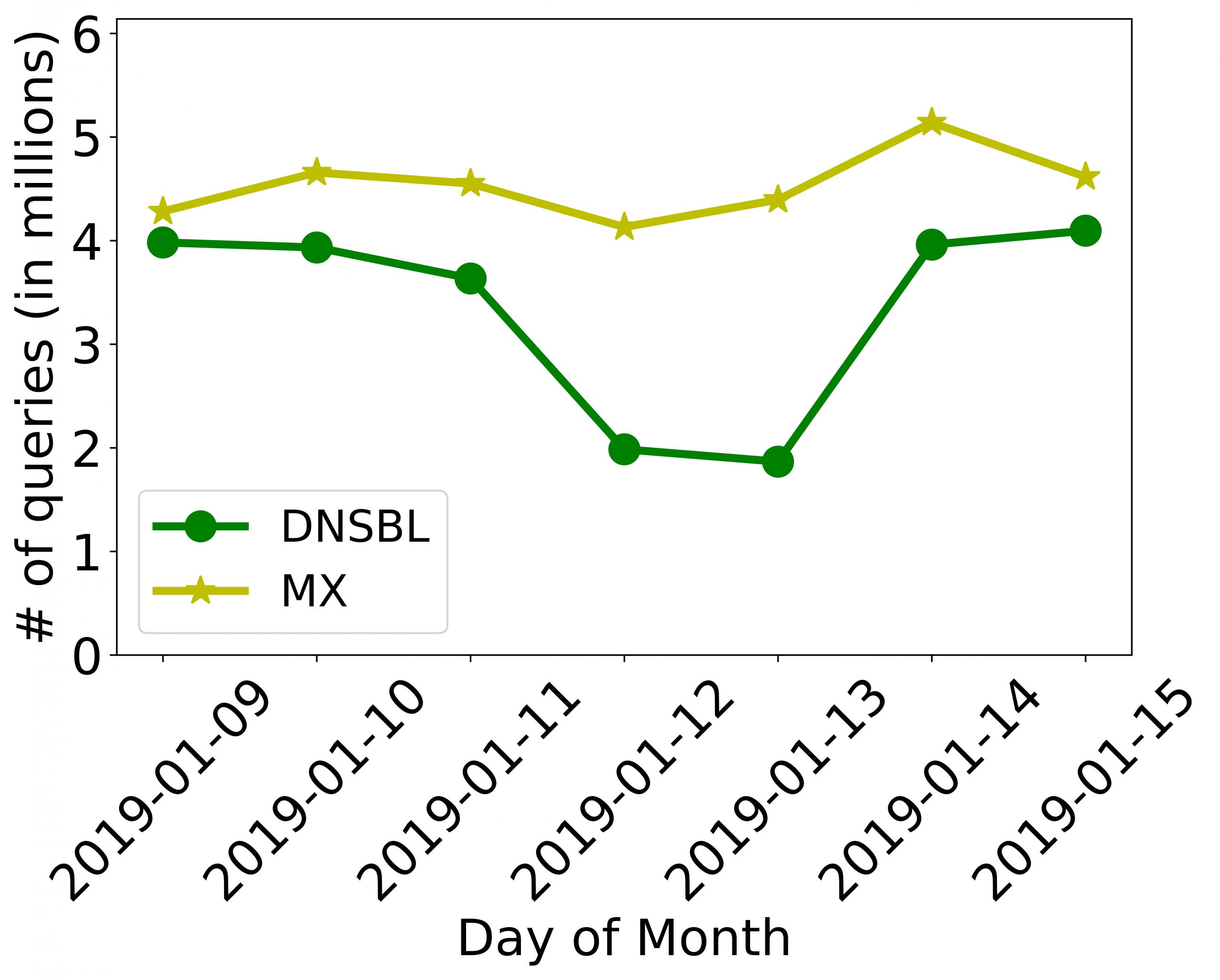
These queries can be grouped by domain names and looked up to find specific relationships in the data. For example, we found an IP address owned by the United States Immigration and Customs Enforcement’s (ICE) Autonomous System (AS) querying the MX record of palantir.com. It is already known that Palantir works with ICE.
The second category of leaks comes from queries to sensitive sites which may damage an institution’s reputation (for example, access to adult or illegal sites) or by revealing employee demographics that otherwise may not be publicly known (for example, access to religious or gender specific sites). We identified access to such sites by collecting all A and AAAA queries from the institutions we studied and fed them into a content categorization API called Webshrinker.
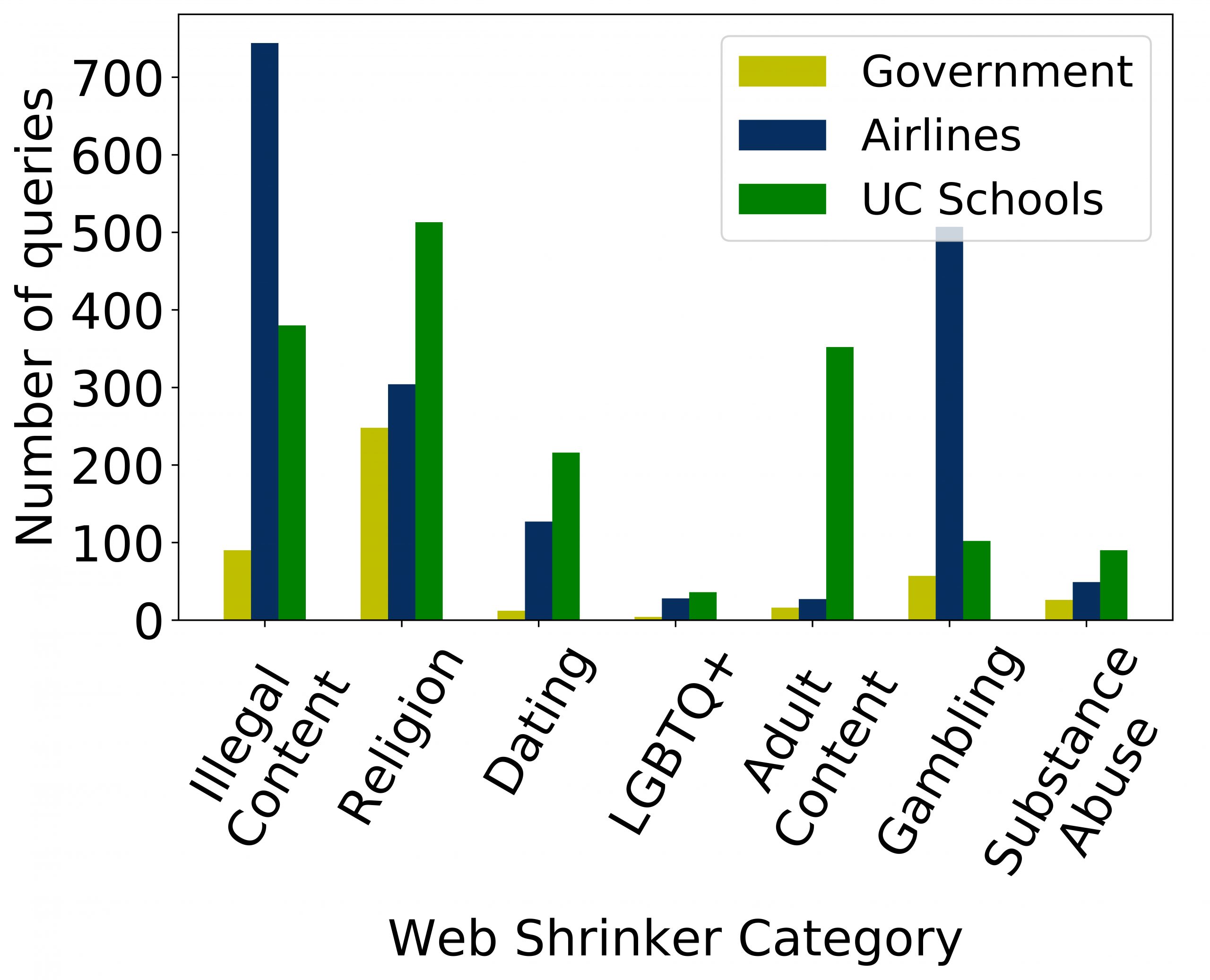
Figure 2 shows that up to several hundred queries were made to sensitive sites from the different categories of institutions. As our results only used a single root server and just one week of data, the numbers provide only a glimpse of the potential privacy risks.
What kind of institutions are at risk?
Institutions that run their own recursive resolvers and have an assigned AS from which their route traffic are susceptible to the threats we identified in our work.
These conditions make it easier for an adversary to identify an institution’s DNS traffic in two ways:
- If an institution runs its own recursive resolver, the adversary can use the resolver’s IP address to uniquely identify the institution’s traffic.
- If an institution routes from its own AS, the adversary can map a resolver’s IP address to the AS the address belongs to and the corresponding institution.
Exceptions to the above are institutions that provide DNS services (for example, public resolvers) or hosting platforms (for example, Google). Queries from such institutions may be from their customers and not their employees, which gives institutions plausible deniability.
Privacy considerations for institutions and operators
Our findings prompt additional privacy considerations for institutions that run their own resolvers and authoritative server operators that log and share DNS data.
For institutions:
Currently, the best way for institutions to reduce information leakage to authoritative servers is to deploy query name minimization (QNAME) wherever possible. We hope our results will encourage its wider adoption.
Read: DNS Query Privacy revisited
LocalRoot is another way to minimize leakage. This approach eliminates information that leaks to root DNS servers but not to lower level authoritative servers.
Another potential solution is for institutions to forward their queries to an external resolver. However, this approach may only shift the privacy threat because all institutional queries are visible to the provider. Institutions that follow this approach should first ensure the resolvers’ privacy policies and data logging practices align with their own privacy goals.
Finally, the IETF’s DPRIVE working group is currently evaluating standards for recursive-to-authoritative encryption. Such standards will protect eavesdropping on institutions from the WAN, but not from operators of authoritative servers. Even with the privacy of the contents on ‘the wire’, QNAME minimization remains important to counter this threat at authoritative servers.
For operators:
There are also actions DNS operators can take to minimize privacy risks when logging and sharing DNS data for different purposes. Our findings have shown that prefix-preserving anonymization, which is commonly used as a privacy measure, may reduce the risks to individuals but not to institutions.
Given existing methods are insufficient, we recommend operators put legal constraints when sharing data. In the case of wider sharing where such constraints may be unenforceable, additional research is needed to develop more rigorous privacy-preserving techniques for sharing networking data.
Overall, our findings raise additional privacy considerations that operators of authoritative servers need to consider. Currently, a guidance document exists for how best to handle DNS data in recursive resolvers. We hope our findings will prompt the formulation of similar guidance documents for handling data in authoritative servers.
This work was funded in part by NSF grants CNS-1755992, CNS-1916153, CNS-1943584, CNS-1956435, and CNS-1925737. To learn more about our study, read our paper Institutional Privacy Risks in Sharing DNS Data, view our data set or watch our presentation at the Applied Networking Research Workshop 2021.
Contributors: Aleksandra Korolova and John Heidemann.
Basileal Imana is a 5th year Computer Science PhD candidate at the University of Southern California.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.