

On the afternoon of 17 June this year there was a widespread outage of online services. It impacted large banks in Australia and New Zealand, a national postal service, the Hong Kong Stock Exchange, and airlines around the world. The roll call appeared to reach some 500 impacted services.
Problems were first noticed around 04:20 UTC and were not fully restored until four hours later. The question is, of course, what do these 500 affected enterprises have in common? Why were they fate-sharing in an outage? This was not the result of a deliberate attack, but it was related to the measures that many of the Internet’s enterprises, both large and small, use to deflect the impact of such attacks. The answer is that they were all customers of Akamai and, in particular, Akamai’s Prolexic DDOS protection system. Akamai’s post-event response was:
“A routing table value used by this particular service was inadvertently exceeded. The effect was an unanticipated disruption of service.”

Yes, the Internet is still growing. In the IPv4 network we are closing in on a million routing entries and in IPv6 the comparable number is now approaching 150,000 entries. Switching elements implement packet decision structures in various ways. Some use Ternary Content-Addressable Memory (TCAM), others use customized Application-Specific Integrated Circuits (ASICs). The common objective is to make a forwarding decision based on a lookup of the best match of the packet’s destination address to a routing entry drawn from this pool of some 1 million entries. This lookup must be as fast as we can possibly make it.
If I am building a very high-speed switch that can handle the packet load of multiple 100G circuits then I probably would like to have my unit make approximately 100M switching decisions per second, implying that I need to design a decision system that can perform this lookup across a set of 1 million entries, and do so in just 10 nanoseconds. This is a very challenging objective. By comparison, the fastest available memory cycle time is a little under 1 nanosecond.
However, it’s not quite as simple as that. If I am building such a switch element, I will need to design it so it can cope with the peak switching loads expected in one, two, or even five years from now. If I get it wrong and do not design sufficient capacity and speed, then my unit will hit obsolescence earlier and this will impose further costs on the network operator. If I over-design it, then I will have spent too much on state-of-the-art high-speed memory and my product will be far more expensive than my competitors.
Every device is built with such design trade-offs and the useful life of these devices depends on indeterminate factors such as the future growth rate of the Internet. The point is that our networks use such equipment, and the role of the network operator is to constantly upgrade their switching equipment’s capability to keep just ahead of these demands. This situation means it’s inevitable that sometimes they will slip up. As did Akamai, evidently. We cannot just out-design this problem when we are sitting on the very edge of silicon capability.
This issue is not unique to Akamai. All network service providers are chasing a similar objective, and from time to time all these systems may flip over to an overload state and have a service outage.
However, this outage was notable for impacting a large set of online service providers. The business of being the backend service provider to online platforms is not exactly a highly populated or diverse business environment. In fact, there are very few enterprises that offer such services, and if any of them experience operational outages then the impacts are going to be highly visible.
As it turned out, the June 2021 incident was not isolated. Earlier in the month, we saw a set of popular services disappear for an hour or more. The list of impacted services included Twitch, Pinterest, Reddit, Spotify, the New York Times, and the BBC, just to name a few. What did all these services have in common? They use Fastly.

“We experienced a global outage due to an undiscovered software bug that surfaced on June 8 when it was triggered by a valid customer configuration change. We detected the disruption within one minute, then identified and isolated the cause, and disabled the configuration. Within 49 minutes, 95% of our network was operating as normal. This outage was broad and severe, and we’re truly sorry for the impact to our customers and everyone who relies on them.”
Again, this was not an attack. It was more like a ticking time bomb where a particular customer configuration setting could trigger a failure in the shared CDN platform. Fastly is built on a configuration management platform called Varnish. As Fastly reported:
“Fastly is built on Varnish, which allows for high-powered content delivery including the ability to instantly purge content across its global network. Using Varnish Configuration Language (VCL), Catch can customize their Fastly configurations, resulting in more intelligent caching.
“Setting cache rules based on something as specific as the cookies in the request is something we would normally only consider possible running our own Varnish server. Having the ability to do so at the CDN layer makes our setup much more powerful and streamlined. We are also able to ensure certain file formats are always served from Fastly, and in theory never have to hit our origin more than once.
“Varnish is incredibly important to us because we can control the VCL if we want to make changes to the caching layer. With most CDNs, you don’t get that kind of flexibility, but with Fastly you do.”
Varnish? What’s Varnish?
“Varnish was designed specifically to replace Squid, a client-side proxy that can be adapted and used as a web accelerator. Its main design goal was to increase scalability and capacity of content-heavy dynamic websites as well as heavily consumed APIs. Such sites run on web servers, such as Apache or nginx, primarily origin servers, which create the web content that is to be served. Varnish’s job is not to create content, but to make content delivery lightning fast.”
When the Norwegian online newspaper VG Multimedia reached over 45 million page views every week, it took 12 servers to handle the requests. Anders Berg, a system administrator at VG Multimedia, believed there had to be a way to reduce the number of servers while also loading the pages faster. He wrote a spec for an open source project dealing with the issue, to get the ball rolling.
So Fastly’s major asset is not some proprietary software system performing a CDN function that is uniquely efficient. Varnish is an open source software tool, like many others. Perhaps what makes Fastly special is its large customer base, and these customers probably use Fastly for their CDN requirements because others have also made the same decision to use Fastly. In other words, what makes Fastly so special in the CDN world is its size, and this size is perhaps one of the more compelling reasons why others choose to use Fastly and contribute to its further growth. Size breeds more size.
Issues with the CDN market
Firstly, while it’s remarkably easy to select one CDN provider and use it for the entirety of one’s online content and service portfolio, it can be more challenging to select two or more CDN providers and use them together in a self-healing mutual backup setup. For many online service enterprises, it’s a case of picking just one CDN and choosing wisely! From that point on, the enterprise is fate sharing with the CDN provider.
Secondly, there aren’t that many CDNs to pick from. If you want a global footprint with sufficient capability to absorb all but the most extreme DDoS volumetric attacks, or even absorb all of them, and a functional service interface that allows the CDN to optimize service delivery yet leaves the customer in control of critical aspects of the security and integrity of the service (such as private keys), then your comparative provider shopping list is not exactly large.
Fastly and Akamai are on most lists of the most popular CDNs, together with Amazon CloudFront, Google Cloud, Microsoft’s Azure, Cloudflare and Limelight. That is seven. There are more of course, some with more regional focus or a particular technical speciality, but those seven enterprises are the core of today’s CDN provider world.
Perhaps that’s the real problem. In the content world it now seems that everyone uses a CDN in one form or another but there are very few CDNs to pick from. It is a highly centralized space where volume economics dominate. The larger CDN providers can offer a service level and price that is impossible for smaller CDN enterprises to achieve. This increases their market share, which adds to their size, and further increases the scale of difference in volume economics between the providers.
The provider space bifurcates between the small set of ‘core’ CDN giants and a larger ‘halo’ of much smaller CDN providers who offer various customized approaches to fill whatever specialized gaps are left by the service profiles of the larger providers. Large providers effectively control the growth prospects of smaller providers because they control what gaps are left in their service offerings. The natural outcome is that large becomes larger, and small tends to get smaller. The inevitable result is that when one CDN service provider experiences a service interruption — as they have in the past and will again in the future — then the casualty list of interrupted services can be very large.
Normally, such outages would erode confidence in the service offering and lead customers to look at alternatives. The result could well be that the investors in the company would get nervous and the stock price would fall. Normally. But Fastly’s stock price has increased across the month of June and there is no residual effect of the outage in terms of the stock price:
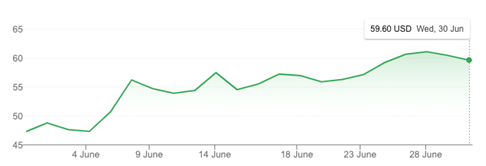
And Akamai’s share price rallied after 18 June:
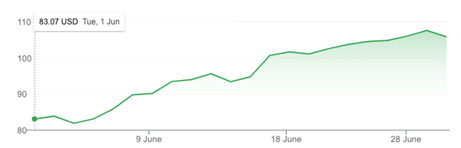
A bubble is generally characterized by irrational exuberance on the part of investors, where the clamour to get a share of the yet-to-be-realized future bounty completely drowns out more sober commentary on the fundamentals of the market, and also ignores the mundane conversation about cost and revenue. That too is one of the issues in a highly centralized market. In a highly centralized market, the rewards on offer for a successful enterprise that completely dominates their market are literally everything in the market, and the prospect of a monopoly premium as a bonus! When such bounties are on offer, the market appears more than willing to ignore a minor inconvenient truth about the less-than-solid foundations of the technology, and incidents that impact operations will continue to happen.
Like many other aspects of the Internet, we are seeing a diverse and robustly competitive environment being transformed into a set of highly centralized environments that can lead to the formation of incumbent cartels and monopolies. Such a centralized environment creates a set of critical dependencies, so that when failures occur — which is inevitable in this space — they are transformed from a minor inconvenience for a few into a major incident that impacts all of us in various ways.
Size and centrality do not necessarily create more robust services. As we’ve seen in these two June outages, and others in the past, size and centrality also pose a greater level of vulnerability for everyone.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.