
Phishing websites rely on camouflage. They need to mimic the real websites as closely as possible, so they can trick people into providing their login information. But there are differences between genuine and fake websites, which can be used to detect them.
Australian researchers working on a joint project between the University of New South Wales (UNSW), Data61, which is part of the Commonwealth Scientific and Industrial Research Organisation (CSIRO), and the Cyber Security Cooperative Research Centre (CSCRC), have developed a new method to spot phishing websites based on a compression algorithm: PhishZip.
Why are phishing websites hard to spot?
Data61 Senior Research Scientist Arindam Pal is among the researchers working on the PhishZip project. “Automatically detecting phishing and spam websites and emails is a highly challenging problem,” Arindam says. This is largely because fraudsters have become adept at disguising their sites as the real thing.
Arindam teamed up with UNSW professors Sanjay Jha, Alan Blair and their PhD student Rizka Purwanto to find a way to spot these phishing websites.
“The phishers use many advanced techniques to design phishing websites. They change the design and layout of the phishing websites every few hours. They also change the URL of the websites frequently,” Arindam says. They can do this at high speed thanks to phishing toolkits that can rapidly design websites.
It is quite hard for non-experts, and sometimes even for experts, to discern a phishing website from a legitimate one.
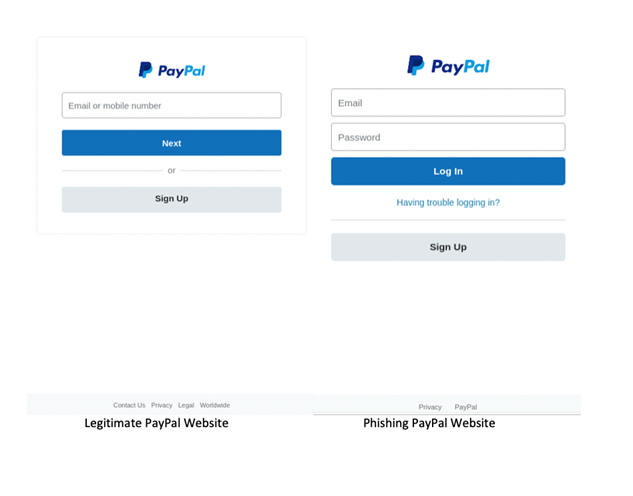
The key is in the keywords
Fortunately, the techniques used by phishers to lure victims do leave them open to some methods of detection.
“The scammers use human behaviour and psychology to their advantage”, Arindam points out. “They try to create a situation of urgency and exploit the greed and desire of people to have free products. That’s why you see messages like ‘Your account will be locked if you don’t act NOW!” or “Get a $50 discount coupon for Apple products’ in phishing emails and websites.”
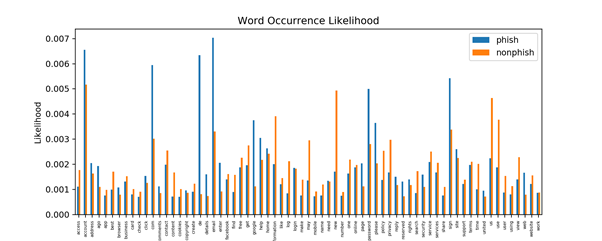
It is these keywords that provide the clues they needed. And it’s not as straightforward as just spotting the use of aggressive marketing techniques — the repetition of these words changes the compression ratio on the site when compared against other sites.
“The primary reason that phishing websites have a different compression ratio compared to the genuine websites is that phishing websites use certain words like ‘password’, ‘offer’, ‘free’, ‘money’, ‘click here’ quite frequently, which are typically not or rarely present in genuine websites,” Arindam says. “If certain words occur many times, the file can be compressed much better than if most of the words are unique or repeated very rarely.”
The team used the DEFLATE file compression algorithm on both legitimate sites and phishing sites, then used the discrepancies in the level of compression to train an algorithm that could spot malicious sites.
DEFLATE is a lossless data compression file format that uses a combination of LZSS/LZ77 and Huffman coding. LZ77 is a dictionary-based Lempel-Ziv compression algorithm, which aims to eliminate duplicate bytes by replacing recurring bytes in the data with a back-reference that points to the first occurrence of the bytes. The next step is using Huffman coding for replacing symbols with new weighted symbols depending on the frequency of occurrence. Thus, symbols which frequently show up are replaced with shorter symbol representations, and vice versa.
The team used the zlib data compression library, which provides an abstraction of the DEFLATE compression algorithm. The zlib module in Python includes functions that implement data compression and decompression using the DEFLATE algorithm and provides the functionality to set a predefined zlib compression dictionary.
This word dictionary can help to improve the compression result and should contain a list of bytes or strings that are expected to occur frequently in the data. The project built two word-dictionaries, which consist of common words in phishing and non-phishing websites, respectively. With these two dictionaries, they performed compression on the same document twice using each dictionary separately.
Ideally, compressing phishing website content using the phishing dictionary should produce a more compressed output than using the non-phishing dictionary and vice versa.
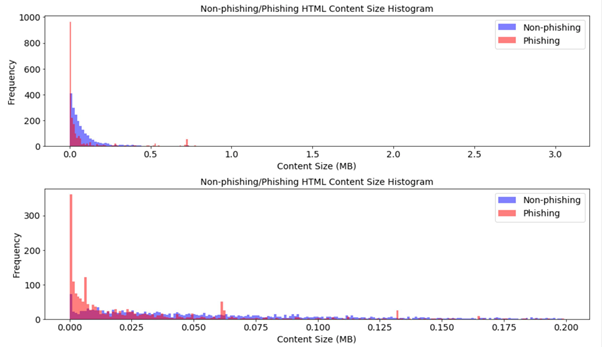
It’s a faster process than many of the existing artificial intelligence-based approaches to detecting phishing websites, as it does not require a large training database or HTML parsing.
This method was used against cloned sites of Facebook, PayPal and Microsoft, among others, and had an accuracy rate of roughly 83%.
This allowed them to build up a database of phishing sites that has been shared to the PhishTank repository for security researchers to analyse.
Never-ending game of cat and mouse
Scammers will no doubt try to adapt to any new method that is used to target their site. So how does the PhishZip approach help when the cloned sites change their format?
“Scammers don’t have knowledge of the inner working details of our algorithm. They don’t have access to our internal dictionary. Still, they can observe that their website is being flagged as phishing. So, they will try to change the URL and modify the look and feel of the webpage to evade detection,” Arindam says. “It’s a never-ending cat and mouse game between the cyber criminals and the cyber security law enforcement agencies.”
Further work in future
Arindam says the team is planning to work further on developing more tools for spotting fraudsters. “We want to build a set of tools, which will offer protection from different kinds of spam and phishing emails and websites,” he said. “They will warn the users even before clicking on a link, by analysing the URL and content of the target website.”
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.