

Modern switches come with the ability to collect telemetry — information about the internal network status, including queue occupancy and latency measurements.
This post presents a probabilistic approach to in-band network telemetry: a way to collect the data you care about while minimizing the number of overhead bits added to packets. It’s based on a collaborative paper presented at ACM SIGCOMM 2020.
INT and its packet overhead
Network telemetry is a fundamental building block for various network functionalities such as congestion control, load balancing, and path tracing.
The In-band Network Telemetry (INT) framework provides a simple, yet powerful, approach for telemetry. The main idea behind INT is to add the desired information onto data packets. With it, for example, you can switch IDs a packet is routed through or the per-switch latency.
INT is widely supported by switches such as Barefoot Tofino and Broadcom BCM56870 Series and is used in state-of-the-art congestion control algorithms such as HPCC.
INT collects the status of the network data plane at switches, without requiring control plane intervention.
Designated INT sources (for example, ingress switches) add an INT header to packets, telling the other hops along the path what information to collect. Each hop reads the header, determines what you are collecting (for example, switch IDs, if you want to discover the path), and adds its own information to the packet.
Since INT encodes per-hop information, the overall overhead grows linearly in the path length and the number of data values collected.
This high overhead has several implications:
- Reducing network goodput — Because INT aims to be transparent to the user, the packets that each flow may send must be smaller than the network MTU to allow adding the INT information without fragmenting the packets. In our experiments, this translated to up to a 25% increase in flow complication time and up to 20% lower latency.
- Increasing switch processing time — Switches have a fixed rate for processing each bit of traffic. The INT information increases the processing time and end-to-end latency. By our calculations, this can translate to a 1-2% latency increase per metadata value on a 10G link.
PINT to the rescue
Given the costs described above, you are probably asking, how can you collect the desired information while reducing the overhead from INT? Well, you can’t — unless you change what you mean by the desired information.
Results from our experiments suggest that for most applications you do not actually need to collect all per-packet per-hop values, but only aggregates of this data. For example, if you wish to verify that a flow’s path conforms with the operator policy (for example, follows an NFV chain, passes through a firewall), it is enough to infer the path from a collection of the packets. Therefore, PINT uses a variety of probabilistic methods such as sampling, hashing, and randomized coding, to reduce the amount of data added to each packet.
In fact, the PINT per-packet overhead can be set by the user and can be as low as a single bit. However, the lower the overhead is, the more packets needed to collect the information and/or the less accurate the collected information is.
PINT’s techniques
PINT minimizes the overhead added to packets via approximation and probabilistic techniques. These include global hash functions and coding.
Global hash functions
Say you want to allow PINT to run multiple queries concurrently. Unlike in INT, you want the overhead to be bounded by the user-defined threshold and not compounded when queries are added.
PINT can select a query subset to run on each packet, and the switches, without communication, achieve implicit coordination by picking the subset and applying the same hash function on the packet ID.
Coding
Now, suppose you want to infer the path taken by a flow. INT supports such functionality by writing all switch IDs along the path onto packets. But what if you want to limit the overhead, say, to one identifier?
An intuitive idea is to use sampling. By writing a sampled identifier from the path, you can collect the entire path after getting enough samples. However, the number of packets needed by such an approach may be quite large.
PINT uses coding to reduce this number. As an example, consider trying to get a path of two hops, with IDs A and B:
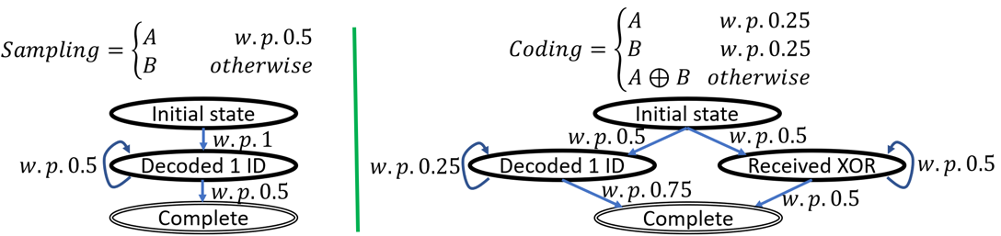
If each packet samples an ID from the path, you would expect to need three packets to get both identifiers. This is because the first packet would carry some ID (for example, A), and this ID is equally likely to appear again in each consecutive packet. Therefore, you would need two packets on average until you get the second ID.
In contrast, consider an algorithm that uses this sampling with a probability of 50%, and otherwise writes the bit-wise x for both IDs. That is, each packet has a probability of 25% to carry the ID A, 25% to carry B, and 50% to carry A⊕B. This modification reduces the expected number of packets you require to 8/3.
For example, if the first packet carried A, you have a probability of 75% of inferring B in each consecutive packet. This is because you get B itself w.p. 25%, and A⊕B with 50%. When getting A⊕B, you can get B from A⊕(A⊕B) since you already know A.
What can PINT do?
PINT reduces the overheads of collecting telemetry information. As part of our study into PINT’s capabilities, we replaced INT by PINT in the state of the art congestion control algorithm, HPCC.
HPCC uses INT to collect per-packet use and queue occupancy statistics. When a packet makes it to the end host, it uses the statistics to fine-tune the sending rate to prevent congestion and improve network metrics such as goodput and flow completion time.
Our observation was that HPCC relies on the bottleneck of the packet’s path to determine the sending rate. Therefore, if the switches compute its congestion signal, it is enough for HPCC to get information about the maximal congestion the packet observed. Specifically, PINT tracks the maximum congestion signal while compressing the value to the user-defined overhead. Here, the congestion signal is an approximated form of the HPCC rate formula that allows us to compress the value into fewer bits.
Moreover, we used randomized rounding so that in expectation, we would convey the exact congestion signal to the end host. This way, the error is averaged over multiple packets, allowing the sender to reach the correct transmission rate.
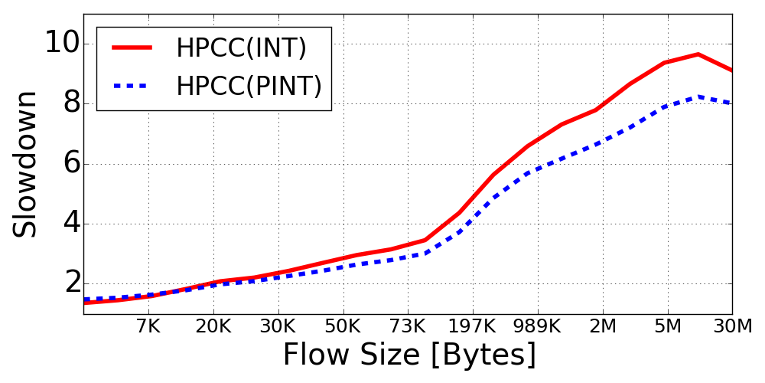
Finally, we showed that HPCC does not need every packet to convey the congestion feedback, thus PINT can only probabilistically (for example, once in every 16 packets) add the congestion information, which frees the other packets for additional queries. As a result, we got comparable or better congestion control, using a tiny fraction of the overhead used in HPCC.
The reduced overhead resulted in improved performance, especially on long flows that sent their data using fewer packets.
This study was the collaborative effort of myself and colleagues at Harvard University, the University of Southern California and Queen Mary University of London. For more information, please refer to our paper or watch our presentation at ACM SIGCOMM 2020 below.
Ran Ben Basat is a postdoctoral fellow at Harvard University.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.