

Chromium is an open-source software project that forms the foundation for Google’s Chrome web browser, as well as several other browser products, including Microsoft Edge, Opera, Amazon Silk, and Brave. Since its introduction in 2008, Chromium-based browsers have risen steadily in popularity and today comprise approximately 70% of the market share.
Chromium has, since its early days, included a feature known as the omnibox, which allows users to enter either a website name, URL, or search terms. But the omnibox has an interface challenge. The user might enter a word like “marketing” that could refer to both an (intranet) website and a search term. Which should the browser choose to display? Chromium treats it as a search term but also displays an infobar that says something like “did you mean http://marketing/?” if a background DNS lookup for the name results in an IP address.
At this point, a new issue arises. Some networks (for example, ISPs) use products or services designed to intercept and capture traffic from mistyped domain names. This is sometimes known as “NXDomain hijacking.” Users on such networks might be shown the “did you mean” infobar on every single-term search. To work around this, Chromium needs to know if it can trust the network to provide non-intercepted DNS responses.
Chromium probe design
Inside the Chromium source code, there is a file named intranet_redirect_detector.c. The functions in this file attempt to load three URLs, the hostnames of which consist of a randomly generated single-label domain name, as shown in Figure 1 below.

This code results in three URL fetches — such as http://rociwefoie/, http://uawfkfrefre/ and http://awoimveroi/ — and these, in turn, result in three DNS lookups for the random hostnames. As can be deduced from the source code, these random names are 7-15 characters in length (line 151) and consist of only the letters a-z (line 153). In versions of the code before February 2014, the random names were always 10 characters in length.
The intranet redirect detector functions are executed each time the browser starts up, each time the system/device’s IP address changes, and each time the system/device’s DNS configuration changes. If any two of these fetches resolve to the same address, that address is stored as the browser’s redirect origin.
Identifying Chromium queries
Nearly any cursory glance at root name server traffic will exhibit queries for names that look like those used in Chromium’s probe queries. For example, here are 20 sequential queries received at an a.root-servers.net instance:
$ /usr/sbin/tcpdump -n -c 20 ... 20:01:34.063474 IP x.x.x.x.7288 > 198.41.0.4.domain: 34260% [1au] A? ip-10-218-80-155. (45) 20:01:34.063474 IP x.x.x.x.31500 > 198.41.0.4.domain: 64756 [1au] AAAA? fwhjxbnoicuu. (41) 20:01:34.063474 IP x.x.x.x.46073 > 198.41.0.4.domain: 13606 A? cluster1-1.cluster1.etcd. (42) 20:01:34.064413 IP6 x:x:x::x.9905 > 2001:503:ba3e::2:30.domain: 52824 [1au] A? xxnwikspwxdw. (53) 20:01:34.064413 IP x.x.x.x.30251 > 198.41.0.4.domain: 9286% [1au] AAAA? cxhplqrpuuck.home. (46) 20:01:34.064413 IP x.x.x.x.56760 > 198.41.0.4.domain: 60980% [1au] A? ofydbfct.home. (42) 20:01:34.065295 IP x.x.x.x.15410 > 198.41.0.4.domain: 21829% [1au] A? wwtsjikkls. (39) 20:01:34.065295 IP6 x:x:x::x.58815 > 2001:503:ba3e::2:30.domain: Flags [.], ack 3919467200, win 30118, length 0 20:01:34.065295 IP6 x:x:x::x.58815 > 2001:503:ba3e::2:30.domain: Flags [F.], seq 0, ack 1, win 30118, length 0 20:01:34.065295 IP x.x.x.x.17442 > 198.41.0.4.domain: 32435% [1au] A? agawwhcwueppouu. (44) 20:01:34.065295 IP x.x.x.x.35247 > 198.41.0.4.domain: 1328% [1au] A? dev-app.stormwind.local. (52) 20:01:34.065295 IP x.x.x.x.18462 > 198.41.0.4.domain: 23433% [1au] AAAA? liffezmsdw.home. (44) 20:01:34.065295 IP x.x.x.x.40905 > 198.41.0.4.domain: 40371% [1au] A? sqtpvvmi.home. (42) 20:01:34.066283 IP x.x.x.x.18125 > 198.41.0.4.domain: 45688% [1au] A? kktaruyy. (37) 20:01:34.066283 IP x.x.x.x.7986 > 198.41.0.4.domain: 60608 [1au] A? bpbutdlihan. (40) 20:01:34.066283 IP x.x.x.x.53489 > 198.41.0.4.domain: 27734% [1au] A? ip-100-65-32-140. (45) 20:01:34.066283 IP x.x.x.x.54028 > 198.41.0.4.domain: 41670 A? qvo7-itirqg3g.www.rabbitair.co.uk.notary-production. (69) 20:01:34.066283 IP x.x.x.x.43866 > 198.41.0.4.domain: 21093% [1au] A? ip-10-0-71-17. (42) 20:01:34.066283 IP x.x.x.x.41141 > 198.41.0.4.domain: 49747% [1au] A? edu. (32) 20:01:34.066283 IP x.x.x.x.36283 > 198.41.0.4.domain: 65449% [1au] SRV? _ldap._tcp.dc._msdcs.mwaa.local. (60)
(Hover over data to scroll)
In this brief snippet of data, we can see six queries (yellow highlight) for random, single-label names, and another four (green highlight) with random first labels followed by an apparent domain search suffix. These match the pattern from the Chromium source code, being 7-15 characters in length and consisting of only the letters a-z.
To characterize the amount of Chromium probe traffic in larger amounts of data (that is, covering a 24-hour period), we tabulated queries based on the following attributes:
- Response code (NXDomain or NoError)
- Popularity of the leftmost label
- Length of the leftmost label
- Characters used in the leftmost label
- Number of labels in the full query name
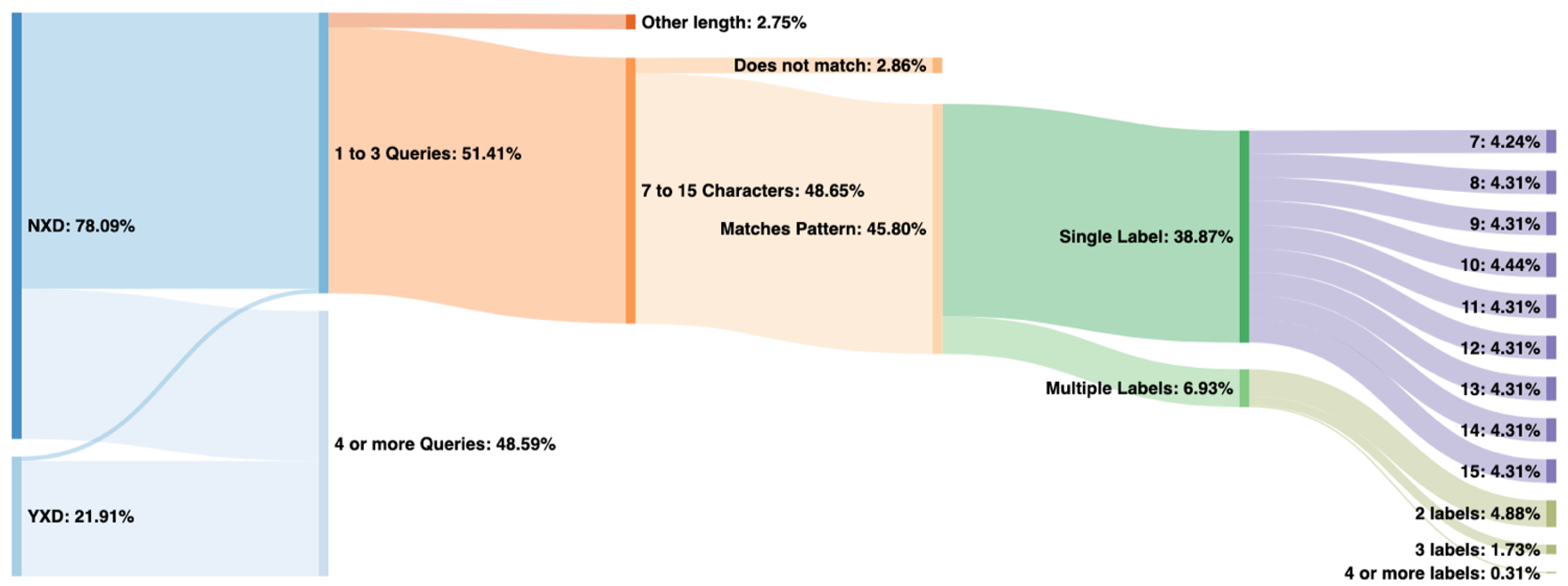
Figure 2 shows a classification of data from a.root-servers.net on 13 May 2020. Here we can see that 51% of all queried names were observed fewer than four times in the 24-hour period. Of those, nearly all were for non-existent TLDs, although a very small amount comes from the existing TLDs (labelled “YXD” on the left). This small sliver represents either false positives or Chromium probe queries that have been subject to domain suffix search appending by stub resolvers or end-user applications.
Of the 51% observed fewer than four times, all but 2.86% of these have a first label between 7 and 15 characters in length (inclusive). Furthermore, most of these match the pattern consisting of only a-z characters (case insensitive), leaving us with 45.80% of total traffic on this day that appear to be from Chromium probes.
From there we’ve broken down the queries by the number of labels and the length of the first label. Note that label lengths (on the far right of the graph) have a very even distribution, except for 7 and 10 characters. Labels with 10 characters are more popular because older versions of Chromium generated only 10-character names. We believe that 7 is less popular due to the increased probability of collisions in only 7 characters, which can increase the query count to above our threshold of three.
Longitudinal analysis
Next, we turned our attention to the analysis of how the total root traffic percentage of Chromium-like queries has changed over time. We used two data sets in this analysis: data from DNS-OARC’s “Day In The Life” (DITL) collections, and Verisign’s data for a.root-servers.net and j.root-servers.net.

Figure 3 shows the results of the long-term analysis. We were able to analyse the annual DITL data from 2006-2014, and from 2017-2018, labelled “DITL Full” in the figure. The 2015-2016 data was unavailable on the DNS-OARC systems. The 2019 dataset could not be analysed in full due to its size, so we settled for a sampled analysis instead, labelled “DITL Sampled” in Figure 3. The 2020 data was not ready for analysis by the time our research was done.
In every DITL dataset, we analysed each root server identity (“letter”) separately. This produces a range of values for each year. The solid line shows the average of all the identities, while the shaded area shows the range of values.
To fill in some of the DITL gaps, we used Verisign’s data for a.root-servers.net and j.root-servers.net. Here we selected a 24-hour period for each month. Again, the solid line shows the average and the shaded area represents the range.
The figure also includes a line labelled “Chrome market share” (note: Chrome, not Chromium-based browsers) and a marker indicating when the feature was first added to the source code.
There were some false positive Chromium-like queries observed in the DITL data before the introduction of the feature, comprising about 1% of the total traffic, but in the 10+ years since the feature was added, we now find that half of the DNS root server traffic is very likely due to Chromium’s probes. That equates to about 60 billion queries to the root server system on a typical day.
Interception is the exception rather than the norm
The root server system is, out of necessity, designed to handle very large amounts of traffic. As we have shown here, under normal operating conditions, half of the traffic originates with a single library function, on a single browser platform, whose sole purpose is to detect DNS interception. Such interception is certainly the exception rather than the norm. In almost any other scenario, this traffic would be indistinguishable from a distributed denial of service (DDoS) attack.
Could Chromium achieve its goal while only sending one or two queries instead of three? Are other approaches feasible? For example, Firefox’s captive portal test uses delegated namespace probe queries, directing them away from the root servers towards the browser’s infrastructure.
While technical solutions such as Aggressive NSEC Caching (RFC 8198), Qname Minimization (RFC 7816), and NXDomain Cut (RFC 8020) could also significantly reduce probe queries to the root server system, these solutions require action by recursive resolver operators, who have limited incentive to deploy and support these technologies.
Contributors: Duane Wessels
Matt Thomas is a Principal Engineer in Verisign’s CSO Applied Research division.
Discuss on Hacker NewsThe views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
You are, unfortunately, straight up wrong about DNS hijacking being the exception. Every home ISP I’ve used since the early ’00s has done it. Usually sufficiently ineptly that I even get results for domains the spec “guarantees” will never be valid.
“The intranet redirect detector functions are executed each time the browser starts up, each time the system/device’s IP address changes, and each time the system/device’s DNS configuration changes.”
I wonder if it wouldn’t be fully sufficient to just test when the IP address or DNS changes and not at startup. That would significantly mitigate the problem.
Keiya, your personal experience with some ISPs you happened to use represents all ISPs all across the globe? How many countries have you lived in? I’ve never encountered any DNS hijacking with any ISP so far.
Hello, thanks for the report. I’m interesting in analysing spikes. I try to identify the datasets you used, but I could not find the data with the same granularity.
Could you point out the datasets you used ?
DNS highjacking was the norm a few years back here in Germany. It’s not allowed anymore and so the practice has stopped.
Sometimes laws are a good thing.
This ugly workaround by Chrome highlights why Omnibox is just bad design and having address bar and search bar as separate windows is better: the user always knows if he enters a search term or an address and enters it in the appropriate box. Not workaround needed.
Fig1_Chromium_source-code-example.png sould be a html5 figure with text. Accessibility is very Important.
I once had an isp with dns hijacking. Annoying, but when asked nicely on customer hotline they deactivated it for me. No need to increase traffic on a central infrastructure by 100% just for the test of a browser. And yes, the browser could cache the result based on the ip of the current dns, and only check once per month or something, instead of every single time the browser is started. That is just bad design. Most people probably only ever use 2 or 3 isp’s with any given computer within a timeframe of a month. (like home/work/mobile plus maybe some hotspots. No need to query 20 times a day)
Have you reached out to Chromium folks via their bug tracker or other means? I would imagine they’d be open to a discussion of alternative approaches.
I’m the original author of this code, though I no longer maintain it.
Just want to give folks a heads-up that we’ve been in discussion with various parties about this for some time now, as we agree the negative effects on the root servers are undesirable. So in terms of “do the Chromium folks know/care”; yes, and yes.
This is a challenging problem to solve, as we’ve repeatedly seen in the past that NXDOMAIN hijacking is pervasive (I can’t speak quantitatively or claim that “exception rather than the norm” is false, but it’s certainly at least very common), and network operators often actively worked around previous attempts to detect it in order to ensure they could hijack without Chromium detecting it.
We do have some proposed designs to fix; at this point much of the issue is engineering bandwidth. Though I’m sure that if ISPs wanted to cooperate with us on a reliable way to detect NXDOMAIN hijacking, we wouldn’t object. Ideally, we wouldn’t have to frustrate them, nor they us.
Does this mean that 50% of the power, servers, support of the root dns servers is being used to service a chrome feature? Easy efficiency gain if it is turned off then.
Looks like Chromium project has opened and is tracking it as bug: https://bugs.chromium.org/p/chromium/issues/detail?id=1090985
They’ve even noticed the negative publicity on it (e.g.: https://bugs.chromium.org/p/chromium/issues/detail?id=1090985#c4 – from right here!)- so hopefully it gains traction and gets fixed.
“needs to know” is an interesting choice of words. technically this is a value-add feature, why not disable the ‘search’ feature if hijacking is detected? you know, Play Nice(tm) instead of forcing a thing? a big problem seems to be the assumption that there is “need” at all. nice write-up btw.
I’m speaking out of my area of expertise here, but could some of this DNS traffic be caused by malware doing random DNS queries to see if it’s being sandboxed, or looking for random C&C servers? This article kind of touches on it, https://searchsecurity.techtarget.com/answer/Sandbox-evasion-How-to-detect-cloaked-malware
> I wonder if it wouldn’t be fully sufficient to just test when the IP address or DNS changes and not at startup.
Winfried, as far as I can see this approach would not work for machines running in a NATed network since the external IP is not visible to the machine running the browser. I grant you that in this case the likelihood of domain hijacking is greatly reduced since the ISP would typically stick to the same behaviour. Maybe a time-based approach would work, e.g. do the check once per day?
Hmm, well that’s funny. I always thought there was more method behind these chromium random generated names. I personally thought they came from someone trying to guess the next nearer NSEC3 domain name or do metrics to get close to that. I guess I was wrong, I did notice these in my DNS query logs but didn’t know chromium was generating them. I guess I never put 2+2 together in my logs which makes me either careless or allows for privacy.
NXDomain hijacking has been active on FiOS (under Verizon and now Frontier) for many years.
@Keiya: The plural of “anecdote” is not “evidence”. This study is based on large-scale evidence, not one person’s anecdote.
The author presents compelling evidence that Chromium’s redirect detector is overloading root servers, but also claims NXDOMAIN hijacking is “certainly the exception rather than the norm” while offering no evidence.
Hence the anecdotes – from multiple people – countering that claim.
(I’ve personally had experience with NXDOMAIN hijacking with an ISP, but that was many years ago.)
Of note is the data log, where the author seems to be using .home on an internal network.
cxhplqrpuuck.home. is a query to the root that counts in the “Name Collision” studies, and this effectively blocked three strings, CORP MAIL and HOME from being delegated in the 2012 round.
The rationale, which seemed extreme hyperbole, was concerns about the introduction of TLDs that might leak sensitive data or create threats to human life (that last one is fairly sensational).
Randomly generated strings of 7-15 characters within a certain TLD should be scrubbed from that process in order to trust the integrity of that data in the future. Clearly this report is substantial evidence that there is traffic with no ability to harm human life.
The irony of the folks who came up with the sitefinder wildcard .com and .net DNS entries writing this pretty funny.
Seriously – you had the bandwidth to shove full pages of partner offers down our throats, but can’t get 3 dns packets back?
Maybe, treat it as a domain instead of a search item only if it ends with a “/”.
OR avoid any pre-intelligent discovery to check whether the potential domain is valid or not – let the user visit it.
Intercept is SOP on RoadRunner/Time Warner, and I have seen it on Comcast. It would be unusual in work environments except as an implementation of corporate policy, in which case you shouldn’t do it.
Should’t circumvent it, that is.
Sort of agree with you, I used to work at a captive-portal maker, You chrome guys can make all the promises to your end-users, they are still using my network and ToS to access services. So it would be nice if you simply complied.
the ips of these wildcard redirections of what should be nxdomains do not change often. maybe detect them like 1/1000 or less, publish the results publicly, and let each browser dl the list occasionally.
I personally care more about my privacy but not the huge traffic on root DNSs. When setting “use a prediction service to help complete searches and URLs typed in the address bar” is enabled in Chrome (default behavior), the content users search is wrapped in a DNS A/AAAA query. And it could be leaked to upstream DNS, mainly ISP and public DNSs of the content being searched.
`domain-needed` setting in `dnsmasq` seems solve the problem. I’m looking for some solution in unbound.
https://github.com/NLnetLabs/unbound/issues/349
Who in their right mind thinks users want DNS interception!?! No one cares if it’s “your network” – especially if I’m the one paying for it. I want either the actual domain I typed or, if it doesn’t exist, the results from my selected search provider.
I’m afraid I don’t understand figure 2. It looks as though the slice of existent domains (YXD) does not match the probe query criteria, so doesn’t that mean it’s not a false positive? YXD would instead be made up probe queries that were appended to by the stub resolver (false negative) and all other queries for existent TLDs (true negative).