

.jpg){kind=link}
Many people believe that the only names sent to DNS servers are the names seen in web browser URLs. However, names that are actually sent through to the DNS contain a wide variety of names from many applications, typos, machine-encoded strings, strings generated by broken code and strings of seemingly random letters.
Let’s dive into one of the primary reasons behind that last item: random strings.
Chromium-based web browsers
If you read the chromium source code, you’ll find evidence that upon a network connection or change, it generates random strings to send to the Internet to determine if the web browser is sitting behind a captive portal (also known as a ‘paywall’). From the source code’s description field:
"This component sends requests to three randomly generated, and " "thus likely nonexistent, hostnames. If at least two redirect to " "the same hostname, this suggests the ISP is hijacking NXDOMAIN, " "and the omnibox should treat similar redirected navigations as " "'failed' when deciding whether to prompt the user with a 'did you " "mean to navigate' infobar for certain search inputs."
And in the C++ code, we find that it generates random names consisting of the letters a-z, from 7-15 characters in length.
// Start three fetchers on random hostnames.
for (size_t i = 0; i < 3; ++i) {
std::string url_string("http://");
// We generate a random hostname with between 7 and 15 characters.
const int num_chars = base::RandInt(7, 15);
for (int j = 0; j < num_chars; ++j)
url_string += ('a' + base::RandInt(0, 'z' - 'a'));
GURL random_url(url_string + '/');
In the summer of 2018, I had Haoyu Jiang join me as an intern at USC/ISI to examine how much traffic to the root zone consisted of Chrome-specific randomly generated traffic. To study this, she separated all of the ‘single-label’ names sent to B-Root and captured in the 2018 DNS-OARC DITL dataset, where a single-label domain is defined as a simple DNS string with a single label (that is to say, no periods) such as ‘com’ or ‘org’ but not ‘example.com’.
The graph below shows five lines, from top to bottom:
- All of the single-label domains received in the 2018 dataset (dark blue).
- The quantity of traffic sent that matched the random strings of length 7-15 believed to be chromium-generated strings (light blue).
- ‘Undefined’ labels (orange). These consisted of any strings that were not believed to be chromium-generated, in the root zone or the dictionary.
- Labels that were specific root-name TLD strings (red).
- Labels that were part of the English language (green).
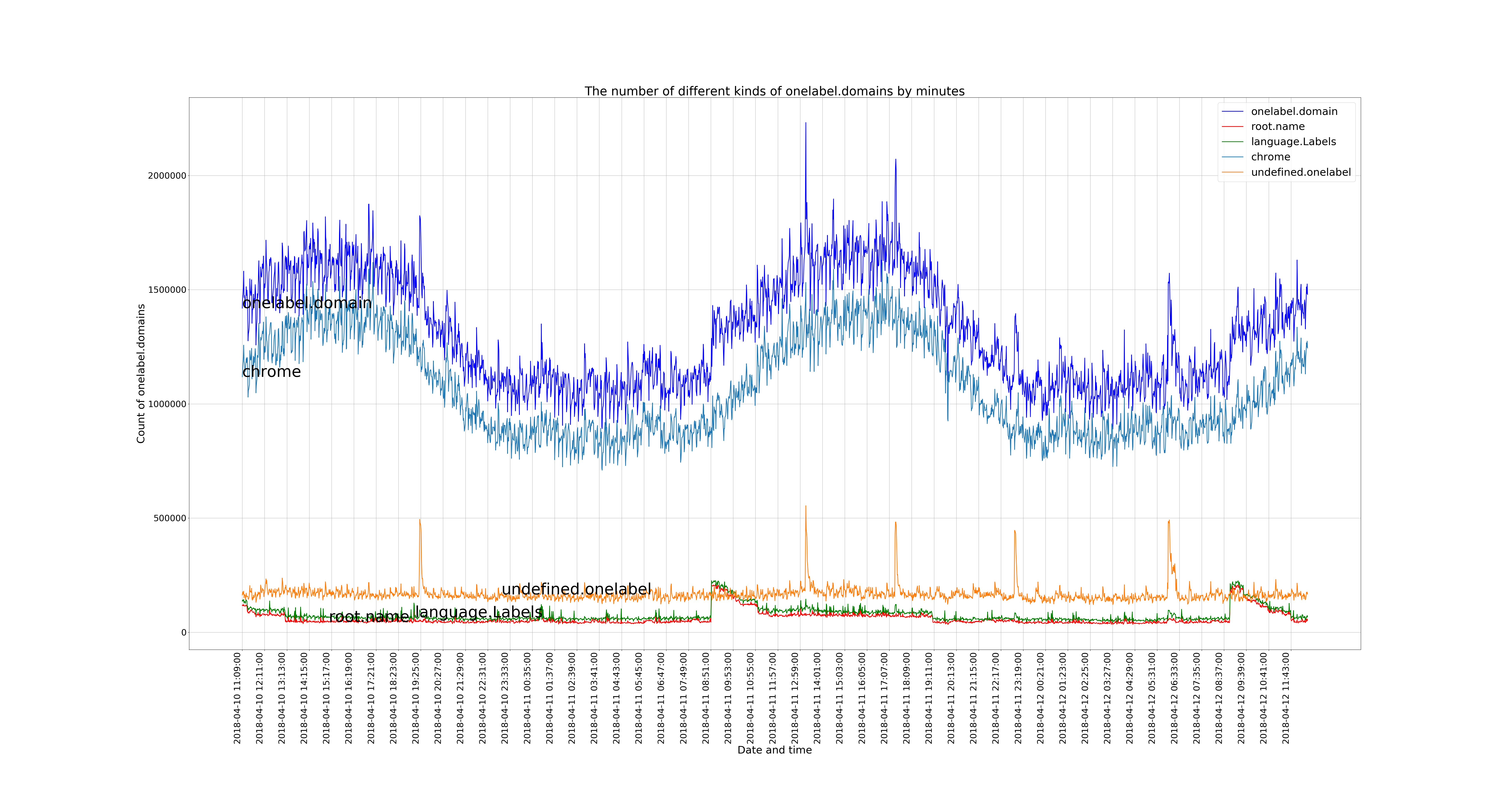
The immediate takeaway from this graph is that the quantity of chromium-generated strings far outweighs all other single label traffic sent to the root zone.
The other important takeaway is how diurnal the pattern is, clearly aligning with a 24-hour clock cycle, showing the variation of web-browser usage over time.
Examining the lengths of single-label names
If we look at the histogram for the length of the single-label queries sent during the 2018 dataset, we discover a pattern that further solidifies that most of the data is generated by Chrome. The graph below shows that the name lengths most likely generated by Chrome are also the most common lengths received in the dataset, indicated by the large quantity between 7 and 15 in length. Also of note is the quantity of length 2 and 3, which is likely from queries for ccTLDs and the popular 3-letter TLDs (com, net, org).
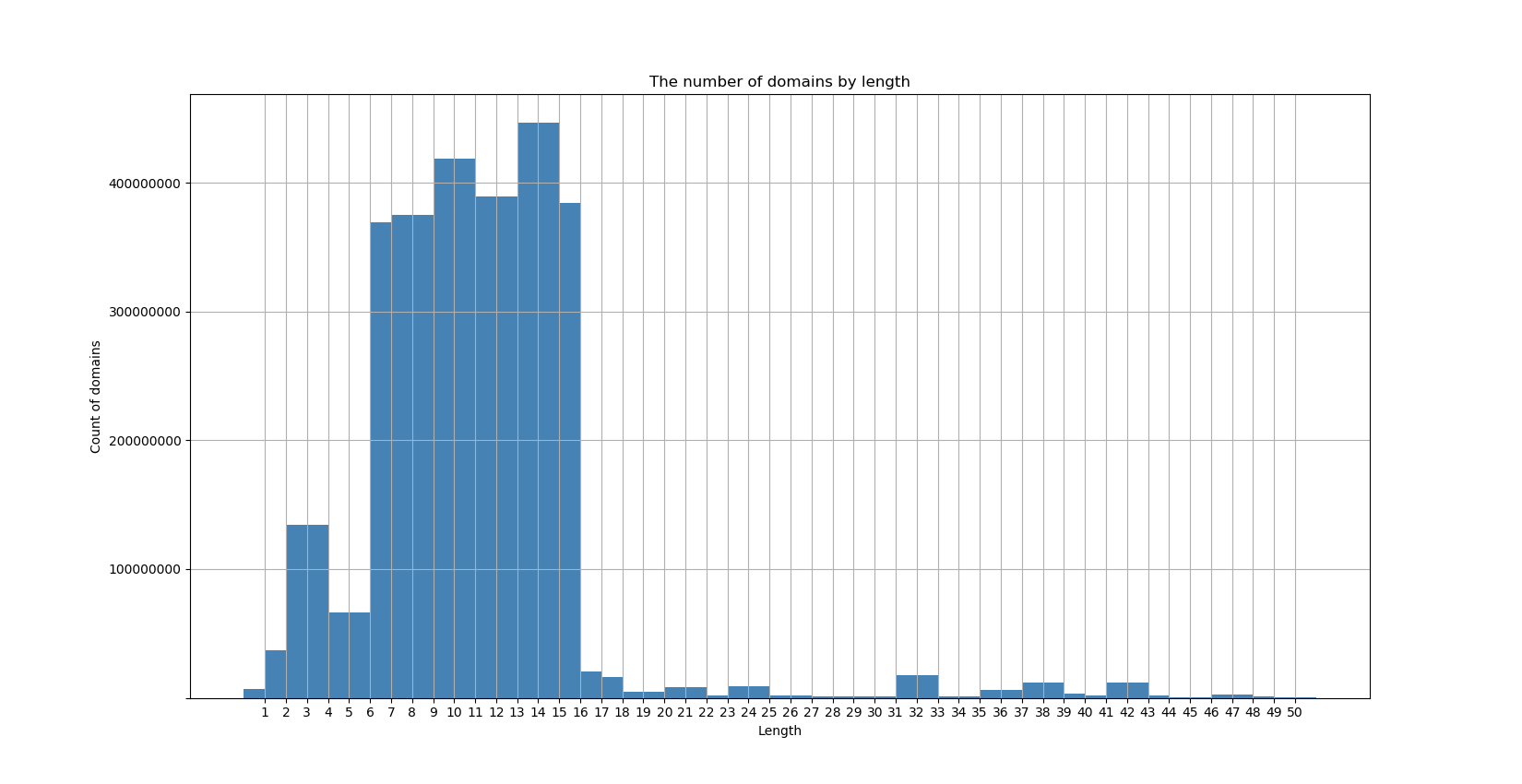
Though the root server system handles this application-specific load sufficiently, it is clear that Chrome’s trick of using randomly generated names to discover whether it’s behind a captive portal contributes significantly to the traffic received at the root zone.
Wes Hardaker is a Senior Computer Scientist at the University of Southern California’s Information Sciences Institute (USC/ISI), where he conducts research on Internet security and is the DNS Root Server operational manager for B-Root.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.