

In the last few years, APNIC has been committed to improving its Registration Data Access Protocol (RDAP) service and making it the de facto replacement for whois. On 1 April, APNIC made major changes to its RDAP infrastructure aiming to improve its availability, latency, and bring NIR data into the RDAP service.
Availability and latency were tackled by moving the service from our data centre to the cloud.
By adding NIR-specific RDAP servers, we are now able to provide the most specific data possible for NIR resources that are not maintained in the APNIC system directly by the NIR.
Moving RDAP to the cloud
Previously, one of the advantages of APNIC’s whois service over RDAP was that whois is deployed in multiple regions around the globe, while RDAP has, until now, only been served from a data centre in Brisbane, Australia. Having a service hosted in multiple regions significantly increases availability since traffic can be redirected to the other regions when one of the deployments is experiencing issues. It also reduces latency since clients can be served by the closest deployment, preferably within their own region when available.
APNIC researched options for having RDAP served in multiple regions and decided to use the Google Cloud Platform (GCP) for this goal. RDAP is now being served from GCP’s facilities in Sydney, Australia, and by the end of this year, we intend to have at least one more deployment in another region. In time we will have more deployments around the globe, helping to provide faster and more reliable RDAP queries.
The GCP deployment model uses Kubernetes, and provides us with significant improvements in service scaling, reporting and monitoring. We expect more APNIC public services to move to Kubernetes over time.
Better NIR results in RDAP
Until now, queries for NIR resources in the whois service have had more specific results than when querying RDAP. For instance, when querying an IPv4 address delegated in JPNIC like ‘58.138.0.0’, the result from the whois service would return the APNIC record for the delegation ‘58.138.0.0/17’ to JPNIC and the JPNIC-maintained record containing the sub-delegation ‘58.138.0.0/18’. By having a copy of the data, JPNIC is maintained as a distinct ‘source’ in the whois service. We have been able to do this because we had a mirror of the state of whois data in JPNIC served from the APNIC whois service.
Previously, RDAP relied only on APNIC’s own whois information, so NIR sub-delegations were not returned in the results. We now have host RDAP servers for the NIRs and when querying RDAP you will always get the most specific information available. Currently, we have RDAP servers for IDNIC, JPNIC, KRNIC, and TWNIC, and we will be including the remaining NIRs over time as they make more specific data available to us.
Architecture
The RDAP deployment comprises several distinct components that work together to serve RDAP queries. The top-level architecture uses Cloudflare for load-balancing and forwarding, with GCP for deployment and replication of each node.
The following diagram presents a high-level architecture of the deployment:
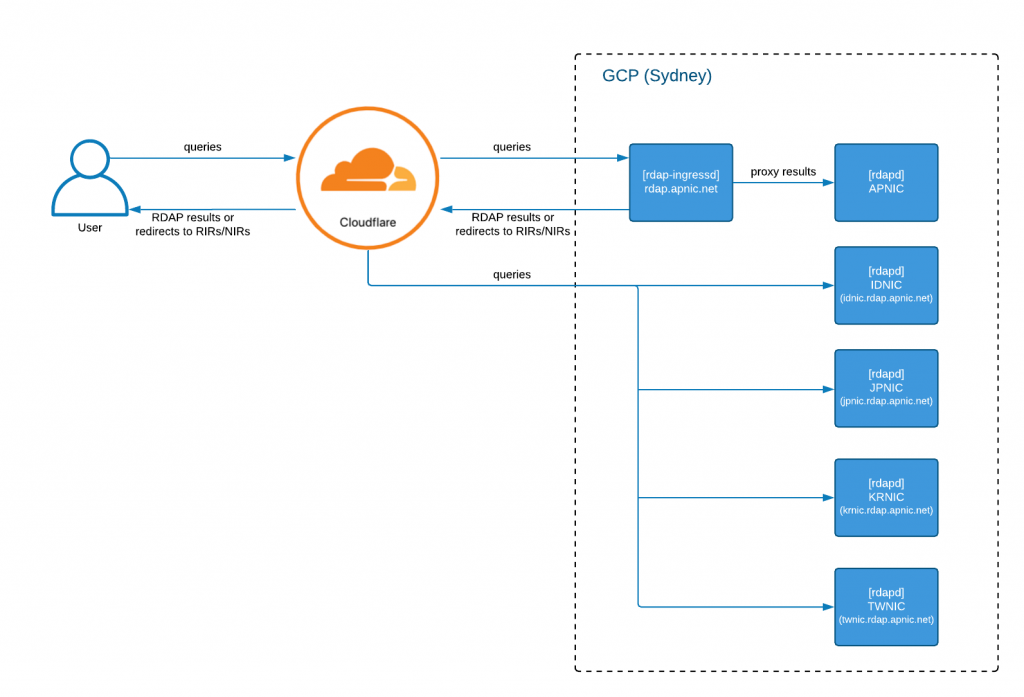
Cloudflare receives the queries for ‘rdap.apnic.net’ and each ‘<nir>.rdap.apnic.net’ and proxies them to the GCP RDAP deployment (currently in Sydney). It also provides us with load-balancing (once we have multiple deployments in GCP) and DDoS attack protection. Cloudflare uses the client’s source address and current ‘liveness’ state of the GCP deployment to pick which service is the best source of data, and forwards the query accordingly.
While we only have GCP in Sydney, all queries go to the Sydney node, but in time as we deploy to other GCP regions, this will change to selecting the location with the shortest round-trip-time (RTT) to the client.
rdap-ingressd is the component inside each GCP deployment that redirects or proxies RDAP queries to the appropriate RDAP servers. Depending on the resource being queried, it may also redirect the query to other RIRs or to one of the NIR RDAP servers (if they choose to operate outside of this framework).
The decision of which server to route to is based on data the system maintains, sourced from IANA, the NRO and APNIC data about NIR delegations. This aligns our redirection with other public statements of management for resources. The jwhois joint whois service operates in a similar manner. Globally, RDAP is fully connected and coordinated from IANA data and this also naturally aligns with this mechanism: we mirror the IANA redirection to out-of-region RDAP requests in case a request is directed to us when it should have been served by RIPE or ARIN or another RIR.
rdapd is the server that answers the RDAP requests. It holds the current registration state, and for APNIC, queries also hold past state and can service the ‘whowas’ service. We have one instance of rdapd serving data for APNIC and one for each one of the NIRs operating at each local node.
Technologies
Going into a bit more technical detail, both rdap-ingressd and all the rdapd are deployed into a Kubernetes cluster running in GCP.
Kubernetes offers us multiple features for automating our deployment, such as enabling us to auto-scale individual components to respond to variable load demands, which makes the deployment more resilient and cost-effective.
The whole deployment infrastructure is defined using Terraform and the software components are deployed using Helm. The combination of the two tools means that replicating the same deployment in other regions is seamless. It also allows us to rapidly redeploy RDAP in a disaster recovery scenario. We have tested redeployment from scratch during the integration testing and build process, so we align with the APNIC Disaster Recovery Process (DRP), but the actual process is simply our normal deployment engineering.
Helm also enables us to perform seamless upgrades, rollbacks and configuration changes to the software components with no downtime. It allows us to define monitoring and analytics dashboards using tools like Grafana.
All software components expose Prometheus metrics that are consumed by a Prometheus server running in the same Kubernetes cluster. We have alert rules defined in this server that feed Prometheus’ AlertManager to notify APNIC staff of application issues. We use Sensu for monitoring infrastructure components.
Tests
Before switching the public service endpoint ‘rdap.apnic.net’ to the new infrastructure, reliability and performance tests were performed on the cloud deployment.
Sustained normal- and high-load tests were performed by querying simultaneously from five different machines (hosted in AWS, to ensure we had no major bandwidth constraints from the test clients) across the globe for 24 hours. Each machine would first issue queries at a rate of 50 per second, and then at 100 per second. It used a combined query set containing multiple queries for each one of the rdapd servers (that is, APNIC and NIRs). The results of this test gave us confidence in the reliability of the new deployment because we have demonstrated it can sustain service at a considerably higher baseline query rate than we normally see at present, with only one GCP node. With the future deployment to more than one node, we will have even higher resiliency in the face of increased baseline load.
We have also performed tests to measure and assess how the new deployment can handle spikes in RDAP queries. We observed that it can successfully serve traffic up to 15 times greater than its normal load. Spike tests were also used for testing other infrastructure aspects such as the GCP/Kubernetes horizontal scaling.
The test results allowed us to define the appropriate resource allocation for the deployment components, and better understand how they behave when subjected to different volumes of traffic. We have been able to ‘tune’ the deployment, which helps manage our cloud computing budget for 2020.
Next steps
We are currently fine-tuning the new RDAP infrastructure to ensure it is as reliable, fast and cost-effective as it can be. In the next months, we will be setting up a second deployment in a different region. This will make RDAP more fault-tolerant by allowing it to failover if one of the deployments is experiencing difficulties, and will also improve latency for clients closer to the new deployment. Our initial deployment in Sydney has delivered a net ‘no worse’ standard of service from a location close to APNIC infrastructure and development, whereas the next deployment will deliver significant reductions in RTT to many clients worldwide. We intend to continue this reduction in RTT, as we deploy more nodes.
Some NIRs have indicated they are in early stages of deployment of local RDAP services, which will hopefully include internationalized data, and we will therefore be able to offer service for these NIRs, with both English and local-language content. Our GCP deployment is capable of offering a ‘mirror’ of these sources, or forwarding queries to the NIR if they prefer.
APNIC continues to work in the IETF regext working group on RDAP standardization and explores improvements in the data model, service profiles, and protocol with other RDAP providers in the number resource and domain name contexts.
APNIC is committed to providing a better RDAP service for our Members and the Internet community. We will have more news on this space later this year, so stay tuned!
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.