

Inbound traffic engineering is a complex process, especially for large ISPs. This is because the de-facto protocol for interdomain routing, BGP, is not designed for balancing network traffic.
The FlowDirector is the first fully operational system that has enabled one of the largest eyeball networks to steer the traffic of a leading, and cooperating, CDN. This system has been running since 2017 and, as of 2019, has the ability to influence the network ingress point — where traffic enters the network — for more than 10% of an ISP’s traffic towards its several tens of millions of customers.
At ACM CoNEXT’19, our group, including researchers from BENOCS, TU München, TU Berlin, and Max Planck Institute for Informatics, presented our findings from this multi-year effort about the challenges of designing, implementing, and rolling out such an inter-domain collaboration system.
A system to enable inbound traffic engineering via inter-domain collaboration
Sometimes, the best way to look into the future is to look into the past.
We recovered and adapted PaDIS, a 10-year-old idea on CDN-ISP collaboration, to create the FlowDirector — a system that provides information to hyper-giants in order to improve their mapping systems. This ultimately leads to improved users’ QoE, while also reducing the ISP’s infrastructure costs and investment capital.
The FlowDirector collects topological and routing information by first connecting to the ISP’s network via IGP, and then to each of its border routers as a route reflector. This information is adequate to determine how ingress traffic will be forwarded through the ISP’s network given an ingress point.
With this information at hand, the system can create cost maps automatically in real-time. Maps comprise two sets of IP prefixes: one with the ISP’s prefixes and another with those for the hyper-giant servers. For each pair of prefixes, the system computes the cost metric with a customized optimization function, for example, the number of hops or the distance that bytes would travel. Thus, these maps provide a ranking of the ingress points for a destination prefix. Note, this function could also be extended to use other information feeds such as telemetry or SNMP, for example, to control the maximum link utilization.
Finally, the FlowDirector interfaces with the hyper-giant to recommend the servers that would best serve their users. The hyper-giant can then decide whether to accept the recommendation.
There are several challenges to keep in mind when realizing a system like the FlowDirector — the following are the most significant that we found in our research:
- Scalability. We had highly demanding operational requirements, for example, to support more than 600 BGP sessions and deal with 1Gbps of Netflow.
- Gaining the ISPs’ trust in order to connect to its IGP required several years to pass certifications, and implement design and safeguard measures as well as redundant systems.
- Lack of standardized interfaces supported by/integrated in hyper-giants that is, ALTO. We had to support several methods: out-of-band BGP, in-band BGP (!), and even file transfers.
User-to-server mapping revisited
The need and opportunity for a system like the FlowDirector became more noticeable during the consolidation of large CDNs and content providers — we refer to these as “hyper-giants” — and the “flattening” of the Internet.
This relatively new landscape fosters collaboration among ISPs and hyper-giants: the most popular content and Internet services are just one inter-domain hop away for many users, and the ISPs providing connectivity to these consumers can receive this content via multiple interconnections.
Furthermore, large ISPs peer with hyper-giants at multiple locations for several reasons: to improve Quality of Experience (QoE), increase redundancy, deal with capacity limits, and reduce long-haul traffic. However, establishing a new peering location does not imply that the peering will be used, and even if it is, that this will be used ‘correctly’. The following figure illustrates the problem:
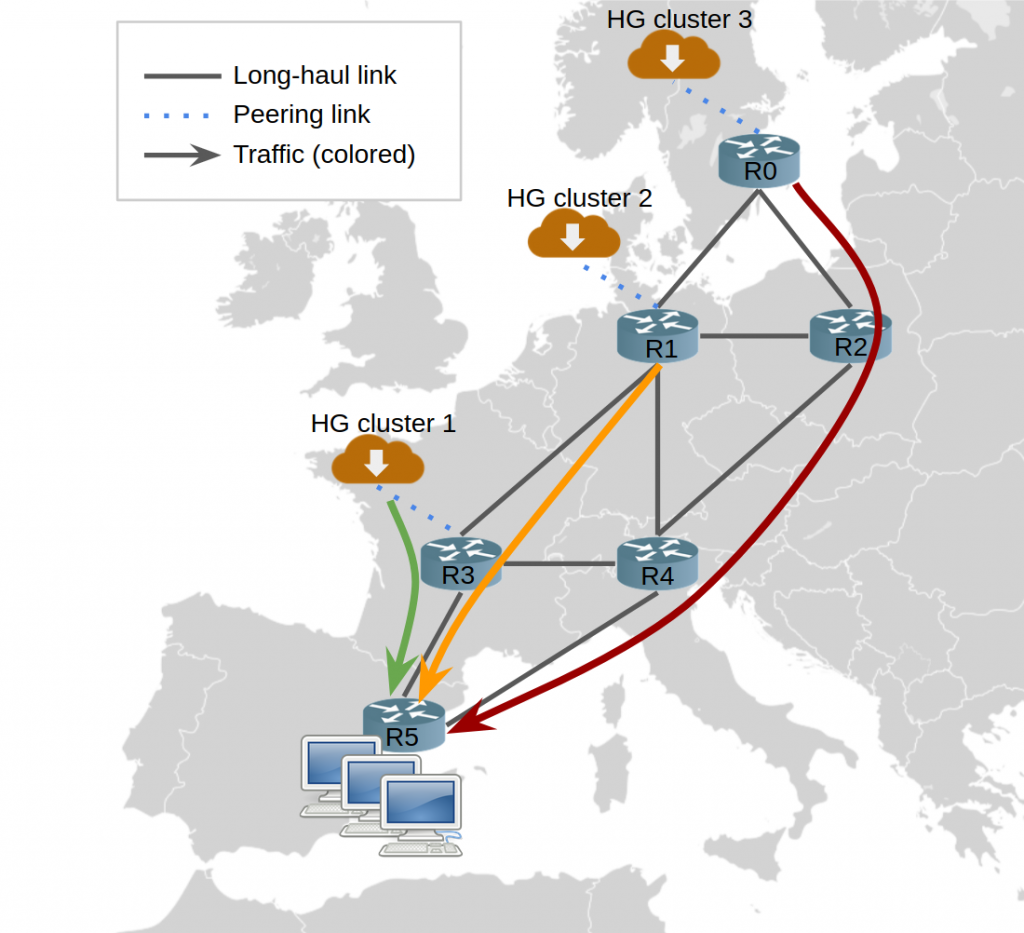
As you can see in Figure 1, the hyper-giant can send traffic over the three ingress points. A response to a query from users in R5 would traverse 1, 2, and 3 backbone links for clusters 1, 2 and 3 respectively. Thus, if all traffic were delivered from cluster 3, the ISP would observe a three-fold increase of this hyper-giant’s traffic in its backbone in this scenario.
Motivated to improve their QoE, many hyper-giants put a lot of effort in finding the proper ingress points, also known as the user-to-server mapping problem. This is often a shared interest with ISPs: to keep traffic as local as possible. In fact, some hyper-giants offer basic interfaces to help ISPs ‘regionalize’ content distribution, for example, Amazon, Netflix and Akamai.
Our study focused on the extent of this problem for one large ISP with more than 10 PoPs. These are some of our initial findings:
- Around 35% of the overall ingress traffic is not optimally-mapped, namely: there is a better ingress point with a lower cost — number of hops and geographical distance. Moreover, this situation is worsening with time.
- If the top 10 hyper-giants could achieve optimal mapping, this ISP’s long-haul traffic could drop by 20%.
- There are several factors within the ISP that alter the best ingress locations for given destination subnets, all of which have different time granularities (see our paper for results regarding modifications of the network topology, changes in the intra-AS routing, and reassignment of the IP address pool).
- External factors causing poor mapping include: limited capacity at network peerings, server loads, or downtimes.
- Some hyper-giants may have less incentives than others to improve their mapping, for example, if they serve latency insensitive content. In this context, the ISP needs to provide the right incentive to the hyper-giant.
Two years of operational experience
Since the FlowDirector was first launched in 2017, both partners have already experienced benefits: lower latency and a decrease in long-haul link usage. These benefits are based on the function agreed on by both sides that includes the number of hops and path distance.
In only two years, the joint work of this ISP’s network planning strategy and the FlowDirector resulted in a 30% reduction of the hyper-giant’s traffic on the ISP’s long-haul links.
To observe the effect that the FlowDirector has exclusively on mapping, we compared the load observed in the backbone against an ideal scenario: hyper-giants follow all provided recommendations (an upper bound). FlowDirector reduced the traffic overhead on long-haul links by 15%.
On the other side, the partnering hyper-giant received benefits from the deployment. Figure 2 below illustrates the results: the normalized gap for the distance-per-byte on the ISP’s backbone reduced by 40%.
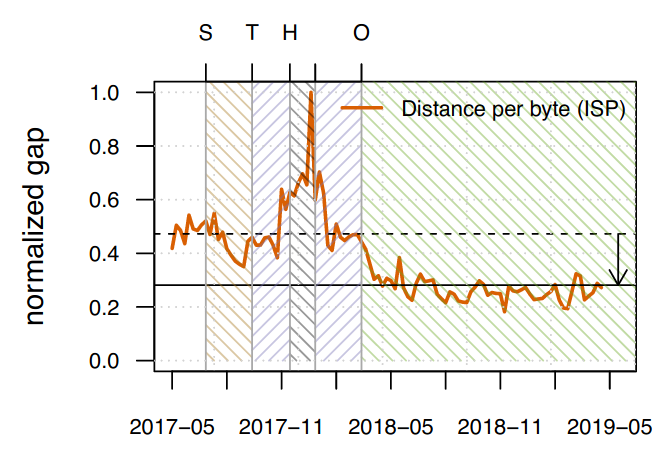
For more details regarding, for example, the progressive rollout results please read our paper.
Enric Pujol is a senior data and research engineer at Benocs Gmbh.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Hi Enric
Really insightful research work on the optimal user – to – NetPOP mapping problem.
Some questions:
a) Can you share any work doing by Standards body (a.k.a RFCs) trying to propose guidelines in setting up such a feedback mechanism between the content provider and the ISP. IOW, if I was a content provider and I would like to use the system that you have presented in the paper, where do I get started?
b) Are there are publicly available URIs where someone can find the list of ISPs that are open to establish such a relationship with the content provider?