

The exponential growth of both Ethernet speeds and the number of CPU cores calls for a new processing model for high-speed networking.
While the current literature typically focuses on load-balancing among multiple servers, we have demonstrated in our latest paper, as presented at CoNEXT ‘19, the importance of load-balancing within a single machine (potentially with hundreds of CPU cores).
In this context, we propose a new load-balancing technique (RSS++) that dynamically modifies the receive side scaling (RSS) indirection table (Figure 1) to spread the load across the CPU cores in a more optimal way.
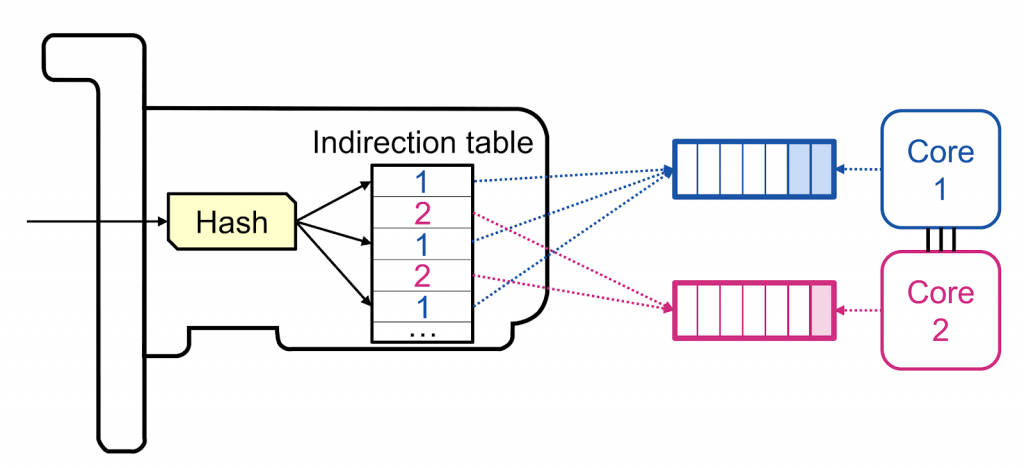
RSS++ has been implemented for both (i) DPDK and (ii) the Linux kernel. As shown in Figure 2, we counted the number of packets received per each indirection table bucket to compute a certain notion of load for each bucket. Then, we used an optimization algorithm that migrates some buckets of the overloaded cores to the underloaded cores.
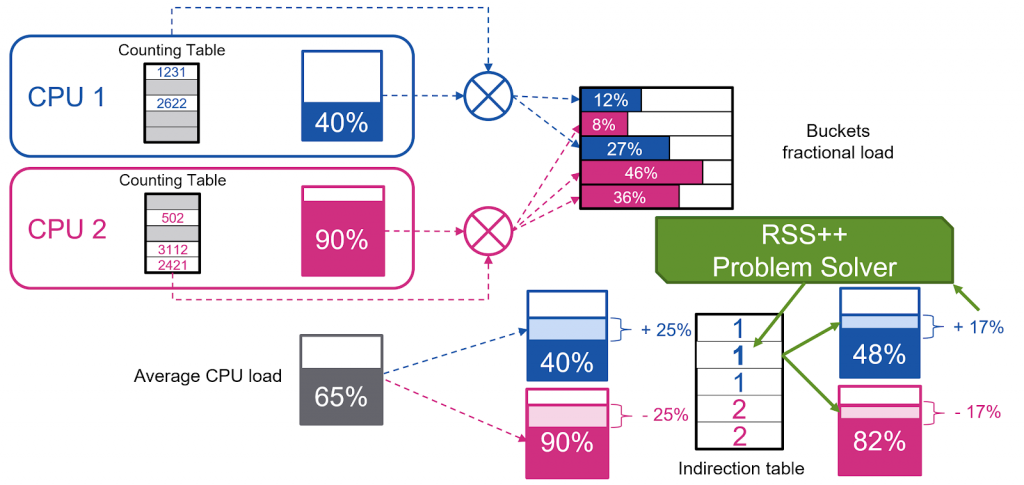
This algorithm runs up to 10 times per second, to ensure a good load spreading, as shown in Figure 3.
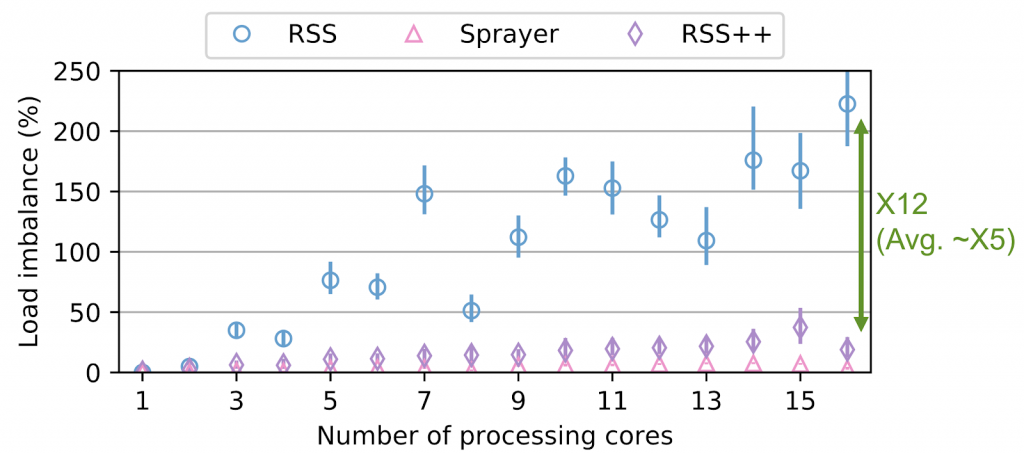
RSS++ also incurs up to 14 times lower 95th percentile tail latency and orders of magnitude fewer packet drops compared to RSS under high CPU utilization. RSS++ allows higher CPU utilization and dynamic scaling of the number of allocated CPU cores to accommodate the input load while avoiding the typical 25% over-provisioning.
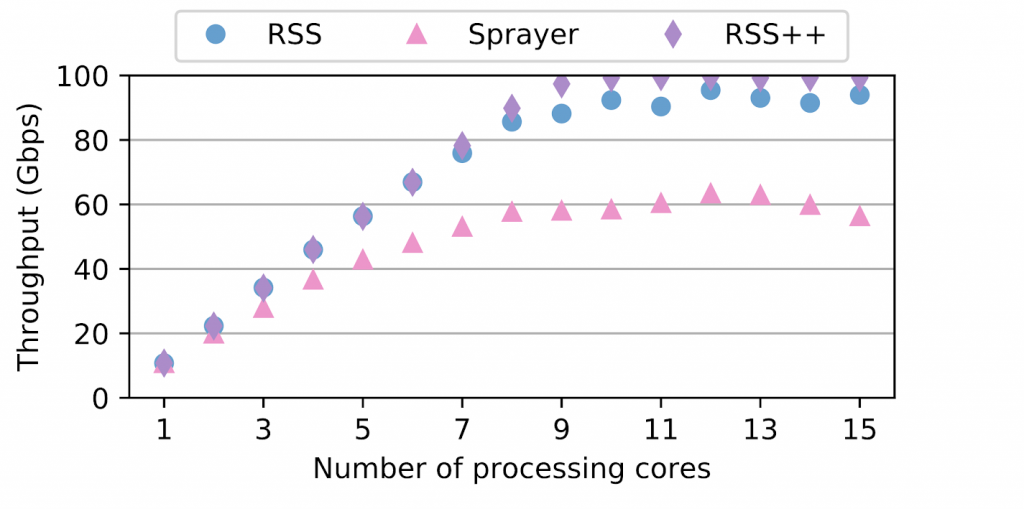
Additionally, we’ve implemented a new state migration technique which facilitates sharding and reduces contention between CPU cores accessing per-flow data. RSS++ keeps the flow-state by groups that can be migrated at once. Figure 4 evaluates this new design, which enables lockless and zero-copy migration of state between CPU cores, leading to a 20% higher efficiency than using a state of the art shared flow table and enabling linear scaling.
The RSS++ paper is now available and the full code is released at Github. Watch our presentation from CoNEXT 2019 below and download the slides.
Tom Barbette is a post-doc researcher in the Networked Systems Lab of Dejan Kostic at KTH Royal Institute of Technology, Sweden.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.