

At the recent linux.conf.au 2020, Dave Täht recounted the story of bufferbloat, explaining how network congestion control works with an often hilarious live demonstration, using human attendees as packets, shuffling them back and forth across the room.
Dave demonstrated TCP and queuing by stepping his volunteers through a series of examples of windowed protocols and TCP Reno/Cubic, then throwing in delay-sensitive data like VoIP and gaming traffic to show how deep buffers affect this class of traffic.
Dave reminisced about when Jim Gettys identified the problem of bufferbloat. “At the time I was living in Nicaragua and just assumed it was my tin cans and string attaching me to the rest of the network, but no, it was a worldwide and difficult phenomenon”.
Dave told the assembled Linux enthusiasts that his dream in 1991 was that he could use the Internet to play in a band with his drummer, who would never show up to gigs. “All I wanted to do then was plug my guitar into the wall and play with him across town, and the speed of light across town was 36 microseconds…I thought this facility would exist by 1998 at the latest, and boy was I wrong!”.
Dave introduced the concept of congestion control, which in basic terms, is algorithms governing how multiple flows from multiple sources share the network when crossing bottleneck links. Without congestion control, “the Internet would collapse — it already did once in 1986. We had to reboot the whole Internet by mailing tapes through the postal service”, Dave recalled, pointing to the work of Van Jacobson and Mike Karels in creating protocols for managing traffic.
Starting in 2011, Dave and Jim, along with a gang of “Internet originals” and over 500 volunteers, started working on the bufferbloat project with the goal of creating new algorithms to manage network buffering better. Their work made its way into Linux, iOS, OSX and FreeBSD early on and was then standardized in the IETF — a process that took six years! With all these achievements behind it, and despite making it into these first billion devices, the project still has “a billion routers and other devices left to upgrade.”
Dave emphasized that the goal of “buffering” was to have “just enough to keep the flow going, and the rest of the time you just want to fill the path”. The bufferbloat problem can be observed as an inverse relationship between latency and throughput, as indicated by the results of a test on the conference venue’s Wi-Fi below.
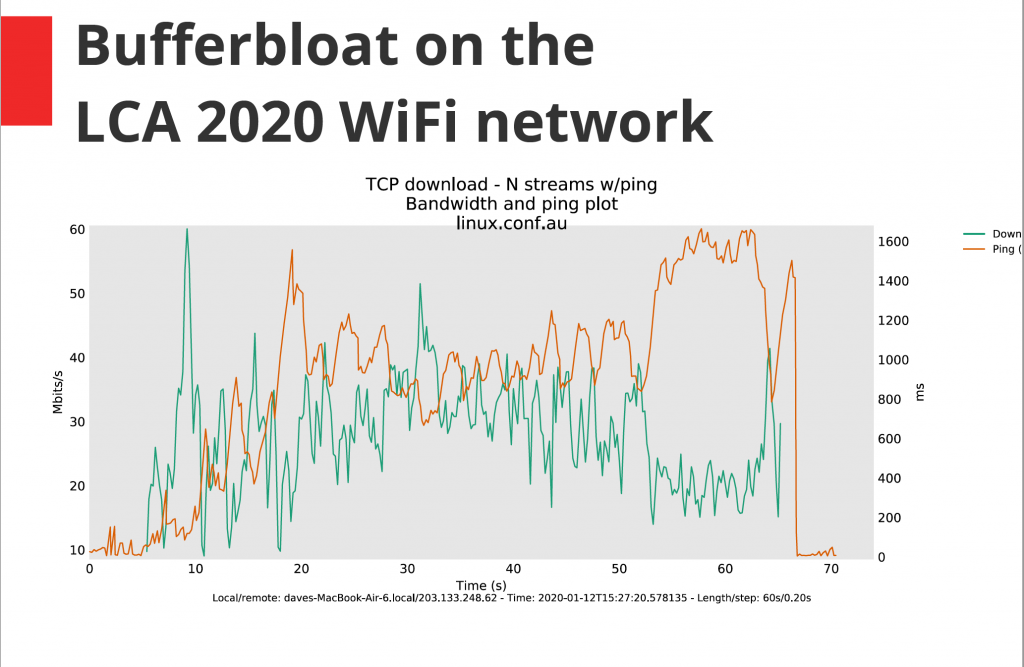
The goal of the bufferbloat project was to “hold latencies low or constant, no matter how much bandwidth you have.” But in the meantime, the Internet adapted in other ways to try and work around the problem. A lot of traffic has moved towards small bursts that are dependent on RTTs to scale up, or uses rate-limited streaming, leaving services like gaming and VoIP to continue to suffer from buffering problems. Dave called these “piecemeal solutions, rather than doing the work to fix all the routers”.
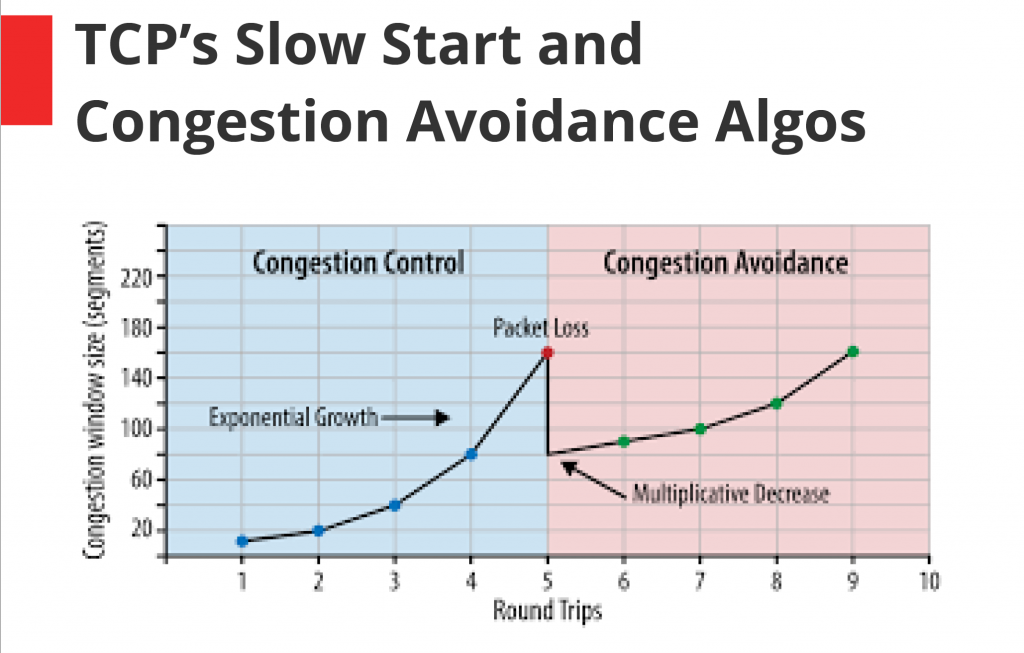
After (literally) walking participants through the workings of the TCP Initial Window, Slow Start and Congestion Avoidance algorithms, which “are here to prevent the Internet from collapsing”, Dave then put the volunteers through the paces of TCP Reno/Cubic, which guarantees a fair share of bandwidth among streams, “if you have reasonable buffers”, in the case of the first demonstration, only 6 – so as to “fill the pipe, and not the queue”.
Dave pointed to some of the less elegant solutions, such as clamping receive windows before introducing fair queuing, which allows for multiple traffic types to be interleaved.
Fair queueing is a technique that is part of the FQ-CoDel algorithm, which the bufferbloat project developed. Even with fair queuing, however, you still need an algorithm to manage the length of the queue, which modern Active Queue Management algorithms such as codel, fq_codel, fq_pie and sch_cake provide. These techniques combine to ensure relatively fixed latency so that jitter-sensitive applications aren’t unfairly affected, and TCP sees its signals rapidly enough to scale up and down invisibly to the user.
Dave said that by combining fair queuing and the codel AQM (in RFC 8290), “we went from a world where we frequently saw seconds of queuing on almost every device in the world to 5ms — we were finally filling the pipe and not the queue”.
So finally, after about 25 years of work on the Internet, Dave can now get about 2ms of latency between himself and a drummer across town in San Francisco, on fibre, even when his Internet is loaded. The experience is probably better for you too, if you happen to run Linux, FreeBSD, iOS or OSX, (which use fq_codel by default) or are using any of the routers that now incorporate these bufferbloat-fighting algorithms, like OpenWrt, dd-wrt, Google Wi-Fi, eero, ubiquiti, evenroute, netduma, fritzbox and so on.
Now the biggest challenge for the bufferbloat project is getting their solution deployed to the remaining billion or so routers on the Internet.
“The future is here… it just isn’t evenly deployed yet”.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
thx very much for covering my talk!
My slides are here: http://www.taht.net/~d/lca_tcp3.pdf
A couple points I’d meant to make:
A) A goodly portion of the intertubes are not governed by the tcp sawtooth anymore, but by the tcp send and receive windows. (this is in the slides not the talk)
B) When walking the ack packets back, I’d meant to send them around the room and stress harder how we needed to manage the queues on *both* sides of the link better. DOCSIS 3.1 modems use the pie algorithm to manage this (and it’s pretty good, as much as I prefer fq_codel) and it’s very cheap in terms of router cpu to put these on the (slow uplink).
(but they got away from me! Unruly packets!)
I keep hoping fiber and 5g folk wake up to these algos in both directions also. Consistently low latency makes for a better user experience on all network technologies. Ethernet over powerline is especially horrible….
I viewed the work we did to improve wifi in linux ( https://lwn.net/Articles/705884/ ) as something that could leveraged in gpon and 5g also.
There is still much left to be done to make wifi 6 better and I wish I could find more (paid) work on it.
C) I mentioned sch_cake a couple times. Doing “sqm” ( https://www.bufferbloat.net/projects/cerowrt/wiki/Smart_Queue_Management/ ) right with software shaping (rather than line rate) turns out complicated (https://openwrt.org/docs/guide-user/network/traffic-shaping/sqm ), so after years of deployment by early adoptors and slower uptake by isps, we poured every improvement on the basic htb + fq_codel algorithm into sch_cake, which had been prototyped in the openwrt distribution for years and was finally mainlined into linux 4.19 ( https://lwn.net/Articles/758353/ ).
While the new features are nifty – notably the per host per flow fq – the goal was to make an sqm so simple, “that even an ISP could configure it”.
D) I’d meant to cover BBR and ECN (two fascinating upcoming alternatives) but ran out of time and felt I’d confuse the audience. Maybe some future talk…
I wanted mostly to leave people with the deep intuition that we only needed enough buffering to fill the pipe and not the queue… and to get ’em laughing at all the folk trying to sell them on deep buffering in their devices! We can now point at a ton of products doing it more right – like the ubnt AP I’d benched at the end – and make all our networks better.
It’s not just my long held desire to play with a drummer across town – but every application, from click to result – can be improved now, under any load, with smarter queues along the edge of the internet.
Thanks for the great presentation and for these follow-up comments Dave!