

At first glance, the University of the South Pacific network is not your usual university network. Our network operates across 26 sites in 12 different Pacific economies and is spread over 33 million square kilometres of ocean — about three times the size of Europe.
Our user base of students and staff combined is around 40,000 people. To connect them all we use a combination of terrestrial and undersea fibre, satellite and wireless. Given the limited resourcing at our disposal, running a network doesn’t get more challenging than that.
With that said, our objectives in running the network are much the same as other operators’. Our network designs and technologies resemble those of other networks; just more widespread and carefully selected for our purpose.
With so much infrastructure to operate, monitor and maintain, it’s important that we are organized and efficient in our approach. We also need to simultaneously progress the planning and deployment of major upgrades and new infrastructure projects.

Figure 1 — About USP.
Making network management efficient
For the day-to-day management of the network, we have invested heavily in monitoring and trying to automate our services. We have tools such as iCinga, PRTG, Perfsonar and other proprietary tools specific for the technology areas we implement. We realized that given the limited number of engineers within our team, things were not going to improve so we had to rethink our approach. If there was a way our team could handle tasks a bit more efficiently but still operate with the same number of people, it was something worth exploring.
Other tasks we also had to carry out included preemptive planning such as using our ServiceDesk system to automatically log tickets for software upgrades based on timelines. This ensures we don’t fall behind on our software and patch management processes.
Other works include meeting every two months to map out our technology path and decide which direction we need to take given the funding available. With much of our planning and designs, the most critical aspect of our entire operations is ensuring our decisions as a team take place collectively with all members discussing our direction. This ensures we are of one mind in our direction going forward and that we also fact-check our opinions.
Managing the hardware lifecycle: C-band satellite dish replacement
The lifespan of a C-band satellite dish is about 15-20 years, and ours were installed in 1999. The age of our satellite platform posed challenges such as fading signal strengths within our campus deployments, which no amount of new modems was going to change. This became evident after we observed the much-improved readings after our first dish replacement in Nauru.
In total, we are installing seven new regional dishes, refurbishing the current dish, and building a new antenna at our Fiji hub. We have also upgraded to a new IP satellite system that provides us with a 32% gain in outbound bandwidth.

Figure 2 — USP Tuvalu campus’ newly commissioned satellite dish (source: USP Tuvalu Campus).
Planning these upgrades began by understanding what our direction should be moving forward, then scoping what technology is required to revamp our satellite platform. Through a series of long discussions, planning and technical assessments, the team was able to map out our exact requirements. At times, our choices were limited by what satellite services are available to us within the region.
Once we have secured supply chains, the challenge is then shipping, customs clearance and coordinating deployment teams for the works. Of course, there are also project timelines and budgets to work within.
Major infrastructure project: Fibre Ring

Figure 3 — Fibre Ring Journey.
The slide above shows the complete timeline of events. It all started with the idea of connecting our buildings in a huge mesh-like environment. Ambitious at the time, such bold moves are required if we intend to truly improve services within our campus.
Given all our fibre works are in-house, it took us time to implement each phase of the project to completion, with our major setbacks being the lack of standardized cabling carried out by our predecessors. While the funding for the fibre ring was secured, additional funding was sourced through the department to ensure we could clean up and audit all our cabinets, pits, backbone paths and structured cabling to ensure our fibre works were not hindered.
While these works were being performed by our cabling infrastructure team, our engineers were busy mapping out the drawings for our switching to determine daisy-chained paths and identify possible bottlenecks in the connections between switches. Even with a super-fast fibre network, it would be pointless if we could not pass such improvements down to our end users, so review and design was everything to our team.
As you can imagine, balancing daily support work in conjunction with all these small side projects takes time and tedious planning. However, given that the team planned the entire design, there was a vested interest from members in completing their assigned tasks — inclusiveness played a major role.
Fibre ring enables wireless mesh and supports growing IT network
At the time when the Fibre Ring Journey was initially proposed, wireless wasn’t as affordable or readily available for many end users as it is today. But it soon became evident that with the change in global trends, the convenience of having a well-planned fibre project proved critical.
As the demand and convenience of wireless connections grew, the load on our backend links also saw a quick rise in bandwidth use. It was fortunate that our monitoring systems could identify areas where we had 90% congestion, which provided us with the baseline we needed to start augmenting our switching hardware. Essentially, if all our baseline designs are well planned, adjusting for changes in network operations becomes an easy task.
At present, our wireless mesh consists of over 350 access points and connects over 2,000 users.
Given the large ICT infrastructure required to hold things together, many of our technology selection decisions stem from analytical data gathered and assessed as a team to find the right fit. From selecting the model of switch to selecting the right server, we evaluate and discuss options available within our budget. We also attend technical conferences and workshops, which is also another good way to learn from colleagues in the field about how they are approaching challenges within their networks. This essentially fosters better understanding on what not to do as its already been field tested. As the saying goes “don’t reinvent the wheel”.
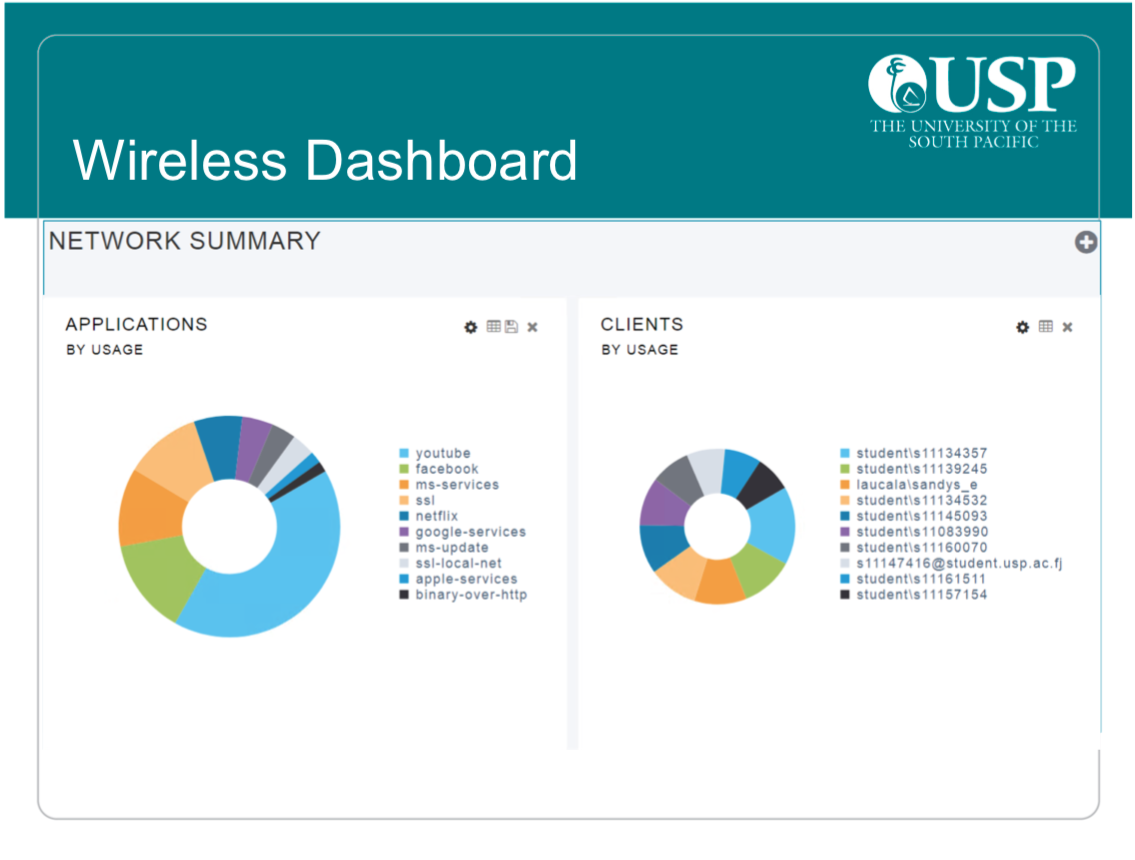
Figure 4 — Wireless Dashboard.
As you can see, running such a large and diverse network comes with many challenges. To keep things running smoothly, we rely on making sure we have good monitoring and documentation of our entire operation. This is the fundamental building block that then allows the team to manage the network efficiently and scale for changes in service offering to our users.
This article was adapted from a presentation given at PacNOG 24.
Edwin Sandys is Manager Enterprise Systems & Network Infrastructure at the University of the South Pacific.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.