

I’ve written several blogs about how IPv6 is faster, and how that results in higher Google search rankings, which is good for sales.
My presentation at NANOG 76 went into it at some depth. Still, the question everyone asks is “Why is IPv6 faster?”, to which I answer, “I don’t know” but the measurements hold some clues.
The graph below is developed from APNIC data, using the ten largest mobile carriers in the world, where I know what transition mechanism they’re using. There are four carriers shown who provide native IPv4-IPv6 dual-stack to the handset: they’re all right at 1% failure rate. I should note that the two at 50ms and -50ms are in Bhutan and Trinidad and Tobago, so there may be other factors at play in the speed of their connectivity. The other two dual-stack wireless carriers are in the US and Taiwan, and IPv6 and IPv4 are nearly exactly the same speed.
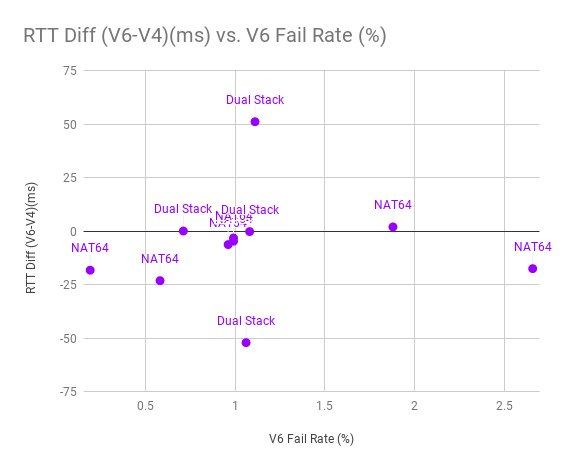
Figure 1 — RTT Diff (v6-v4)(ms) vs. V6 Fail Rate (%) for the 10 largest mobile carriers in the world.
Among the mobile carriers running NAT64, only the Australian has a faster IPv4, by just one millisecond — @jeremyvisser on Twitter says the Australian provider switched to native dual-stack, so, IPv4 is slower for all NAT64 carriers shown. For all the rest, IPv6 is faster. Why?
With native dual-stack, the carrier provides both an IPv4 address and an IPv6 address to the handset. With NAT64, the carrier provides only an IPv6 address. If the client needs to reach an IPv4-only server, it has to go through translation (Network Address Translation, NAT64). Apple requires that all iPhone apps just work with NAT64. For Android, if there’s something in the app that uses IPv4 explicitly (or just an IPv4-only library), there’s a little NAT46 function in Android that translates to IPv6, since that’s the only address the handset has. That function is called CLAT (client translation), and when combined with NAT64, is called 464XLAT.
It’s possible that going through NAT64 introduces some latency, though I’ve never seen NAT64 add measurable latency. Maybe the NAT64 is on a suboptimal path.
It’s also possible that the latency difference is not in the NAT64 end, but on the CLAT end: maybe the handset translates from IPv4 to IPv6 before sending traffic out, and the handset software is causing the speed difference.
What about all the fixed line providers with speed differences?
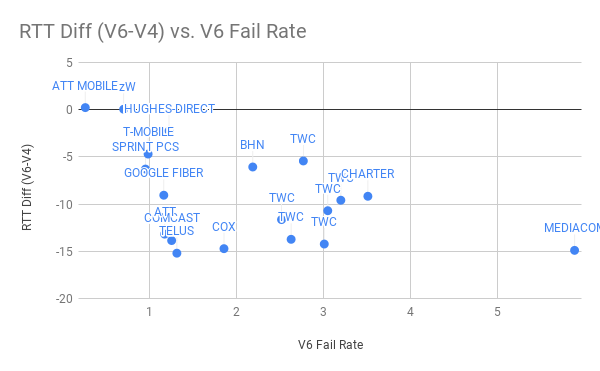
Figure 2 — RTT Diff (v6-v4)(ms) vs. V6 Fail Rate for fixed line providers in North America.
These are just the largest networks in North America (Figure 2). This does suggest a loose correlation between failure rate and latency. Generally (but not closely) networks with more IPv6 failures show better IPv6 performance.
Most operating systems and browsers, including mobile handsets, use an algorithm called Happy Eyeballs (RFC 8305) to make sure the deployment of IPv6 doesn’t harm performance. That algorithm basically says:
- Send DNS queries AAAA then A, as separate queries but in quick succession.
- Send to an IPv6 name server if you have both an IPv6 name server and IPv4 name server configured.
- Don’t wait for both responses.
- If A comes first, wait (for example, for 50ms for AAAA) in case it was just that the resolving name server didn’t have it cached.
- Begin your connection.
- If connection fails (for example, no response in 250ms), and you got multiple DNS responses, try another: maybe use the other address family.
There’s an odd race condition here, I think. Let’s say you fire off your AAAA DNS query (IPv6) and your A DNS query (IPv4) within a millisecond. For whatever reason, the resolver you’re querying only has the A record cached, so it looks up the auth server for the AAAA query, but immediately responds with the A response. Your system waits 50ms for the AAAA response, and if it doesn’t arrive, it begins the connection, sending a TCP SYN over IPv4. Then the AAAA response arrives, so it begins the connection, sending a TCP SYN message over IPv6. Based on that timing, the TCP SYN-ACK is received over IPv4 before it’s received over IPv6.
That’s just an example. Any time the TCPSYN-ACK is received over IPv4 after the TCP SYN is sent over IPv6, but before the TCP SYN-ACK is received over IPv6, the system will use IPv4, and APNIC Labs will count it as an error.
There could be reasons other than DNS why the SYN-ACK is received over IPv4 first. Maybe the TCP ACK required retransmission? Maybe the IPv6 attempt took 260ms (or whatever the connection timer was) and the IPv4 attempt completed in 9ms? Maybe there are different timers than the ones suggested by RFC 8305 and some operating system gives a smaller head start to IPv6 but on some networks IPv4 is faster than the IPv6 round trip time? Maybe we’re measuring old implementations of Happy Eyeballs (RFC 6555)?
Too long did not read
I think Android CLAT hurts IPv4 and I think there’s a race condition in Happy Eyeballs that can make IPv6 look faster in statistics by dropping some cases where it’s slower.
Adapted from original post which appeared on Retevia.net
Lee Howard is CEO at Retevia.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.