

The Internet routing system is vulnerable to attacks and that is a problem. But what is the scale of the problem and how does it evolve over time?
When it comes to MANRS these are not hypothetical questions
Mutually Agreed Norms for Routing Security (MANRS) is a community-driven initiative coordinated by the Internet Society that provides a minimum set of low-cost and low-risk actions that, taken together, can help improve the resiliency and security of routing infrastructure.
One of the key elements of MANRS is the measurable commitments by its members. Network operators demonstrate their commitment to improving routing security by implementing four MANRS actions: Filtering, Anti-spoofing, Coordination and Global Validation (for the description of these actions please see the MANRS website and figure below).

Figure 1 — MANRS actions: Filtering, Anti-spoofing, Coordination and Global Validation.
While checks are made at the time an operator joins the initiative, continuous measurement of ‘MANRS readiness’ (MR) and increased transparency are essential for the reputation of the effort.
We need to be able to better understand the state of routing insecurity and how it evolves. This is needed to support the problem statement, demonstrate the effect our efforts have and see where problem areas are. This is the idea of the MANRS observatory — a tool where one can see how routing security, expressed in terms of MANRS readiness, evolves for a specific network, economy or region.
So what can we observe, given our tool is passive measurements?
Unfortunately, we cannot measure MANRS readiness with 100% assurance — this would require on-site inspection of router configs — but we can get a good indication by looking at publicly available data relevant to the four MANRS actions:
- Filtering requires a network operator to ensure correctness of their own announcements and announcements from their customers to adjacent networks. For an indication of how well this action is implemented, we can look at routes leaked or hijacked by a network or its customers. There are several tools that provide such information, such as BGPStream (based on RIPE RIS and BGPlay).
- Anti-spoofing requires that a network operator implements a system that blocks packets with spoofed source IP addresses for their customers’ and own infrastructure. One can look at CAIDA’s Spoofer database and look for tests that indicate spoofable IP blocks of the network and its clients.
- Coordination requires a network operator to maintain globally accessible up-to-date contact information, which we can check by looking at contact registration in RIR, IRR and/or PeeringDB.
- Global validation requires a network operator to publicly document routing policy, ASNs and prefixes that are intended to be advertised to external parties. To assess this, we can measure the percentage of announcements with corresponding routes registered in an IRR, or valid ROAs registered in the RPKI repository. We can also look at whether an operator documented their routing policy in an IRR.
Metrics
For some of these actions, devising and calculating metrics is straightforward. For others, less so.
For example, with filtering, do we calculate a metric based on the impact of an incident, such as a route hijack (how much wreckage such an incident produced), or on conformity (whether an incident demonstrated that the action was not implemented properly)? In the case of the latter, it doesn’t matter if 1 or 1,000 prefixes were hijacked — in any case it means a lack of filtering. Since the objective of this project is to evaluate readiness, we take the second approach.
In our model, routing incidents are weighted depending on the distance from the culprit. It means that if a hijack happened several hops away from a network, it is considered a less severe mistake than if that is your direct neighbour causing the incident.
Non-action is penalized. The longer the incident takes, the heavier it is rated. For example:
< 30min -> weight = 0.5
< 24hour -> weight = 1.0
< 48hour -> weight = 2.0
Also, multiple routing changes may be part of the same configuration mistake. For this reason, events with the same weight that share the same time span are merged into an incident. This is shown in Figure 2.
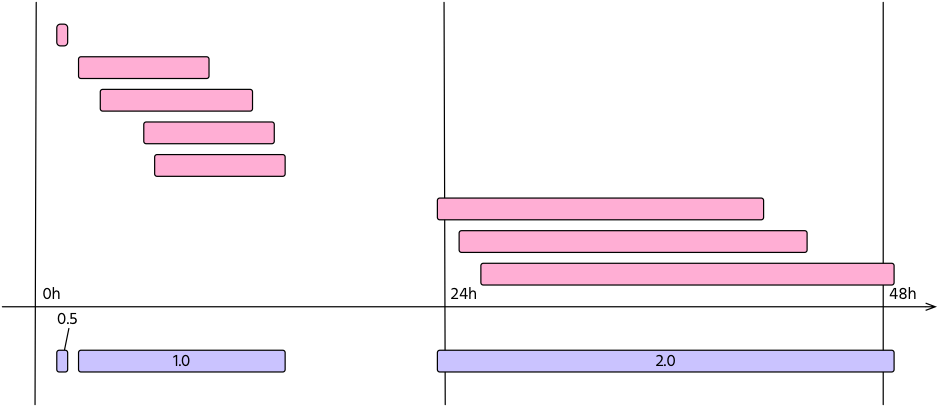 Figure 2 — Routing changes, or events (in pink), may be part of the same incident (violet). In this case, an operator experienced three incidents with a duration of 29 minutes, 13 hours, and 25 hours respectively. The resulting metric will be M=0.5 + 1 + 2 = 3.5.
Figure 2 — Routing changes, or events (in pink), may be part of the same incident (violet). In this case, an operator experienced three incidents with a duration of 29 minutes, 13 hours, and 25 hours respectively. The resulting metric will be M=0.5 + 1 + 2 = 3.5.
Based on this approach, for each of the MANRS actions, we can devise a composite MR-index and define thresholds for acceptable, tolerable and unacceptable — informing the members of their security posture related to MANRS.
And because we are using passive measurements we can calculate metrics for all 60K+ ASes in the Internet and track it over time.
This approach was presented at RIPE 76 [PDF 698 KB]. This project is now in a prototype phase and we hope to present results online later this year.
Let us know your thoughts on the above method and other ways you are measuring routing insecurity in the comments section below.
Andrei Robachevsky is the Senior Technology Program Manager at the Internet Society.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.