

A colleague recently forwarded me an article about he hazards of browsing on public WiFi with the question: “Doesn’t HTTPS fix this?” And the answer is, “Yes, generally”.
As with most interesting questions, however, the complete answer is a bit more complicated.
HTTPS is a powerful technology for helping secure the web; all websites should be using it for all traffic.
If you’re not comfortable with nitty-gritty detail, stop reading here. If your takeaway upon reading the rest of this post is ‘HTTPS doesn’t solve anything, so don’t bother using it!’ you are mistaken, and you should read the post again until you understand why.
HTTPS is a necessary condition for secure browsing, but it is not a sufficient condition.
There are limits to the benefits HTTPS provides, even when deployed properly. This post explores those limits.
Deployment limitations
HTTPS only works if you use it.
In practice, the most common ‘exploit against HTTPS’ is failing to use it everywhere.
Specify https:// on every URL, including URLs in documents, emails, advertisements, and everything else. Use Strict-Transport-Security (preload!) and Content-Security-Policy’s Upgrade-Insecure-Requests directives (and optionally Block-All-Mixed-Content) to help mitigate failures to properly set URLs to HTTPS.
Mixed content — By default, browsers will block non-secure scripts and CSS (called ‘Active Mixed Content’) from secure pages. However, images and other ‘Passive Mixed Content’ are requested and displayed; the page’s lock icon is silently hidden.
Non-secure links — While browsers have special code to deal with Active and Passive mixed content, most browsers do nothing at all for Latent Mixed Content, where a secure page contains a link to a non-secure resource. Email trackers are the worst.
Privacy limitations
SNI / IP-Address – When you connect to a server over HTTPS, the URL you’re requesting is encrypted and invisible to network observers. However, observers can see both the IP address you’re connecting to and the hostname you’re requesting on that server (via the Server Name Indication ClientHello extension).
TLS 1.3 proposes a means of SNI-encryption, but (unless you’re using something like Tor) an observer is likely to be able to guess which server you’re visiting using only the target IP address. In most cases, a network observer will also see the plaintext of the hostname when your client looks up its IP address via the DNS protocol (may be fixed someday).
.@AP It should be https://t.co/gS8ORydpbb, NOT https://t.co/9zV6XNajsT.
— (@Alby) January 25, 2017
Data length — When you connect to a server over HTTPS, the data you send and receive is encrypted. However, in the majority of cases, no attempt is made to mask the length of data sent or received, meaning that an attacker with knowledge of the site may be able to determine what content you’re browsing on that site.
Protocols like HTTP/2 offer built-in options to generate padding frames to mask payload length, and sites can undertake efforts (Twitter manually pads avatar graphics to fixed byte lengths) to help protect privacy. More generally, traffic analysis attacks make use of numerous characteristics of your traffic to attempt to determine what you’re up to; these are used by real-world attackers like the Great Firewall of China.
Attacks like BREACH make use of the fact that when compression is in use, leaking just the size of data can also reveal the content of the data; mitigations are non-trivial.
Ticket linking — TLS tickets can be used to identify the client (addressed in TLS1.3).
Referer header — By default, browsers send a page’s URL via the referrer header (also exposed as the document.referrer DOM property) when navigating or making resource requests from one HTTPS site to another. HTTPS sites wishing to control leakage of their URLs should use Referrer Policy.
Server identity limitations
Certificate verification — During the HTTPS handshake, the server proves its identity by presenting a certificate. Most certificates these days are issued after what’s called ‘Domain Validation’, a process by which the requester proves that they are in control of the domain name listed in the certificate.
This means, however, that a bad guy can usually easily get a certificate for a domain name that ‘looks like’ a legitimate site. While an attacker shouldn’t be able to get a certificate for https://paypal.com, there’s little to stop them from getting a certificate for https://paypal.co.com. Bad guys abuse this.
Some sites try to help users notice illegitimate sites by deploying Extended Validation (EV) certificates and relying upon users to notice if the site they’re visiting has not undergone that higher-level of vetting. Sadly, a number of product decisions and abysmal real-world deployment choices mean that EV certificates are of questionable value in the real world.
Even more often, attackers rely on the fact that users don’t understand URLs at all, and are willing to enter their data into any page containing the expected logos:
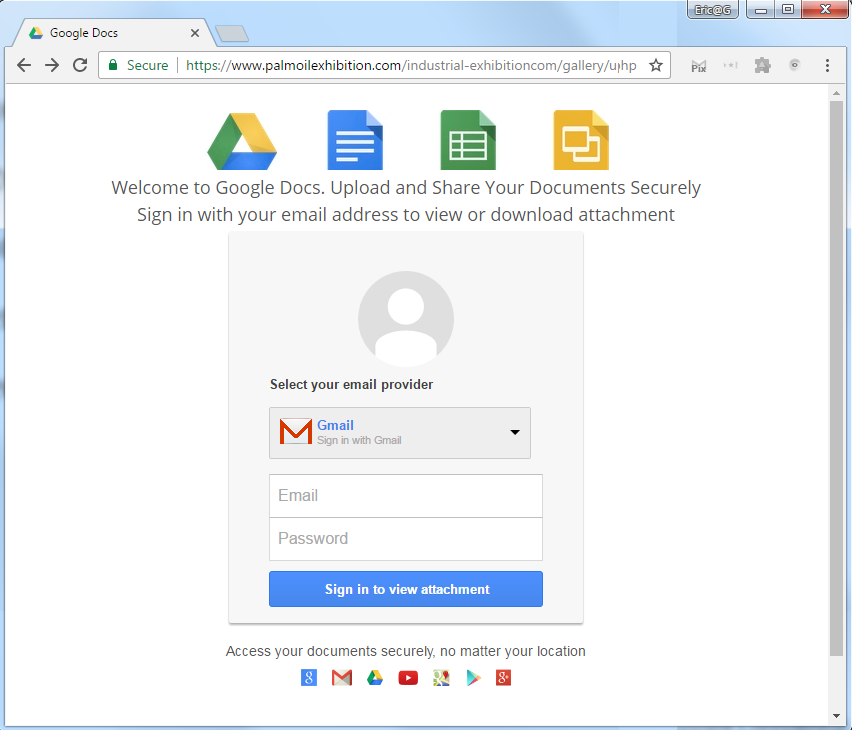
One hop — TLS often protects traffic for only one ‘hop’. For instance, when you connect to my https://fiddlerbook.com, you’ll see that it’s using HTTPS. Hooray!
What you didn’t know is that this domain is fronted by Cloudflare CDN’s free tier. While your communication with the Content Delivery Network is secure, the request from the CDN to my server (http://fiddlerbook.com) is over plain HTTP because my server doesn’t have a valid certificate.
Author’s note: A few days after posting, someone pointed out that I can configure Cloudflare to use its (oddly named) ‘Full’ HTTPS mode, which allows it to connect to my server over HTTPS using the (invalid) certificate installed on my server. I’ve now done so, providing protection from passive eavesdroppers. But you, as an end-user, cannot tell the difference, which is the point of this post.
A well-positioned attacker could interfere with your connection to the backend site by abusing that non-secure hop. Overall, using Cloudflare for HTTPS fronting improves security in my site’s scenario (protecting against some attackers), but browser UI limits mean that the protection probably isn’t as good as you expected — see a nice video on this below.
Multi-hop scenarios exist beyond CDNs; for example, an HTTPS server might pull in an HTTP web service or use a non-secure connection to a remote database on the backend.
DOM mixing — When you establish a connection to https://example.com, you can have a level of confidence that the top-level page was delivered unmolested from the example.com server. However, returned HTML pages often pull in third-party resources from other servers, whose certificates are typically not user-visible. This is especially interesting in cases where the top-level page has an EV certificate (‘lighting up the green bar’), but scripts or other resources are pulled from a third-party with a domain-validated certificate.
Sadly, in many cases, third-parties are not worthy of the high-level of trust they are granted by inclusion in a first-party page.
Server compromise — HTTPS only aims to protect the bytes in transit. If a server has been compromised due to a bug or a configuration error, HTTPS does not help (and might even hinder detection of the compromised content — in environments where HTTP traffic is scanned for malware by gateway appliances, for instance). HTTPS does not stop malware.
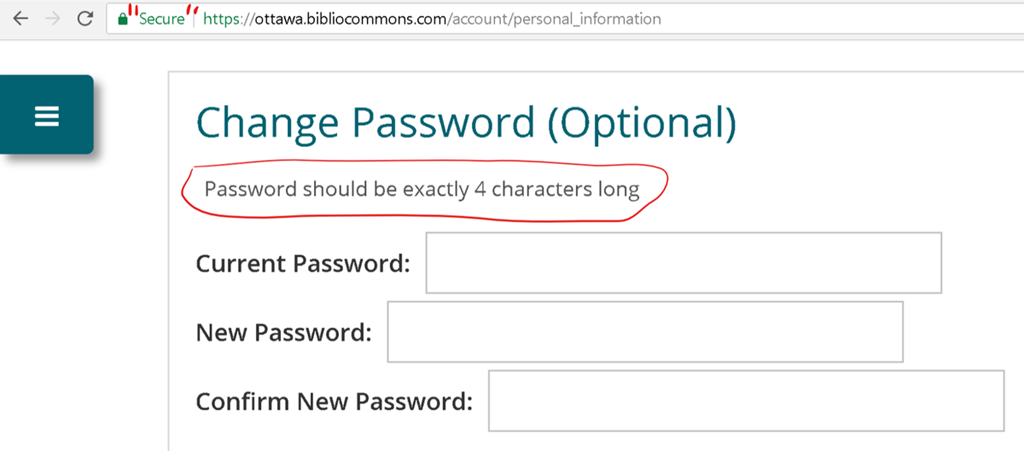
Server bugs — Even when not compromised, HTTPS doesn’t make server code magically secure. In visual form:
In 10 years, I have not found a more effective picture to explain software security. #swsec pic.twitter.com/ondb5fV6FY
— Eric Baize (@ericbaize) July 25, 2014
Client identity limitations
Client authentication — HTTPS supports a mode whereby the client proves their identity to the server by presenting a certificate during the HTTPS handshake; this is called ‘Client Authentication’. In practice, this feature is little used.
Client tampering — Some developers assume that using HTTPS means that the bytes sent by the client have not been manipulated in any way. In practice, it’s trivial for a user to manipulate the outbound traffic from a browser or application, despite the use of HTTPS.
Features such as Certificate Pinning could have made it slightly harder for a user to execute a man-in-the-middle attack against their own traffic, but browser clients like Firefox and Chrome automatically disable Certificate Pinning checks when the received certificate chains to a user-installed root certificate. This is not a bug.
In some cases, the human user is not a party to the attack. HTTPS aims to protect bytes in transit but does not protect those bytes after they’re loaded in the client application. A man-in-the-browser attack occurs when the client application has been compromised by malware, such that tampering or data leaks are performed before encryption or after decryption. The spyware could take the form of malware in the OS, a malicious or buggy browser extension, for example.
Real-world implementation limitations
Early termination detection — The TLS specification offers a means for detecting when a data stream was terminated early to prevent truncation attacks. In practice, clients do not typically implement this feature and will often accept truncated content silently, without any notice to the user.
Validation error overrides — HTTPS deployment errors are so common that most user-agents allow the user to override errors reported during the certificate validation process (for example, expired certificates, name mismatches, even untrusted CAs). Clients range in quality as to how well they present the details of the error and how effectively they dissuade users from making mistakes.
Further reading
Original post appeared on textslashplain.com
Eric Lawrence is helping to bring HTTPS everywhere on the web as a member of the Chrome Security team.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.