

RPKI Relying Party (RP) software is used by network operators and others to acquire and verify Internet Number Resource (INR) data stored in the RPKI repository system. RPKI data, when verified, allows the RP to verify assertions about which Autonomous Systems (ASes) are authorized to originate routes for IP address prefixes.
RPKI data also establishes a binding between public keys and BGP routers, and indicates the AS numbers that each router is authorized to represent. This latter functionality is essential for the BGPsec protocol, which is in line to be published as an IETF standard later in 2017.
Each RP links the INR allocation hierarchy and the Internet routing system for itself, making a connecting thread from the RPKI to BGP speakers. Significance is therefore attached to the RP actions.
The essential requirements imposed on RPs are scattered throughout numerous RFC documents that are protocol specifications or that document best practices. To sum up, requirements for RP software, for use in the RPKI, are as follows:
- Fetching and caching RPKI repository objects
- Processing certificates and CRLs
- Processing RPKI repository signed objects
- Delivering validated cache data to BGP speakers
Each of these functions is to some extent independent or at least “de-coupled” (they could be run independently asynchronously).
At present, at least three open source packages exist. These are the RPKI Toolkit ‘rpki.net’, RIPE’s RPKI Validator, and RPSTIR.
As one of the administrators of RPSTIR, I would like to briefly describe the implementation of this software, which is in alignment with those requirements described above and with the design considerations described in a paper authored by Mark Reynolds and Stephen Kent.
RPSTIR is available on GitHub.
Implementation
Figure 1 illustrates the architecture of RPSTIR, which has five components:
Synchronization Module, Verification Module, RTR Module, Database Module, and Validated Cache Query Module.
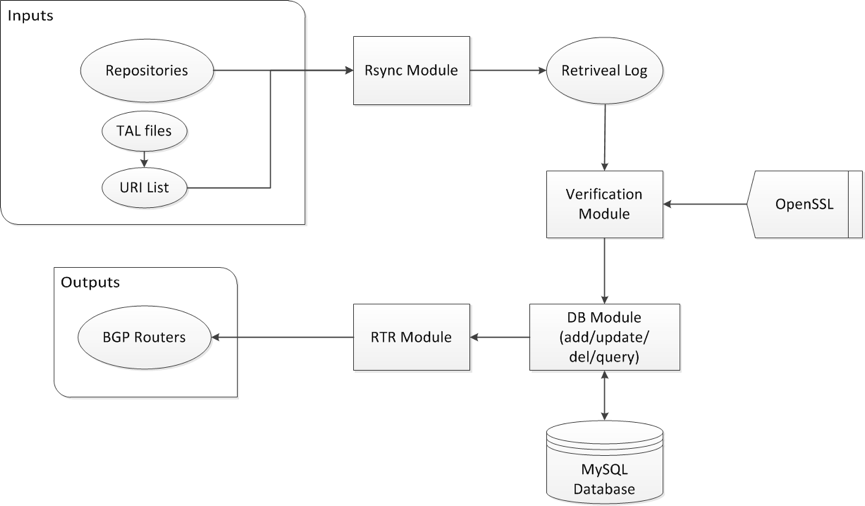
Figure 1 – Architecture of RPSTIR
The Synchronization Module of RPSTIR relies on the open source tool Rsync; by executing the ‘rpstir-synchronize’ command recursively the module downloads certificates and signed objects with a set of preconfigured Trust Anchor Locators. RPSTIR calls the Verification Module immediately after it downloads each updated certificate or set of signed objects, which means synchronization and verification are performed simultaneously by RPSTIR.
The Verification Module constructs the certificate-chain path and delivers it to OpenSSL for validation. Certificates that pass (or those that do not pass) the validation process are both then saved to the Database Module using MySQL, with successfully validated certificates marked in the database explicitly.
The RIR Module of RPSTIR periodically creates snapshots of validated signed objects, with a serial number to mark the version of the validated cache. This module sets a query frequency limit per connection in order to avoid some types of DOS attacks.
The Validated Cache Query Module of RPSTIR shows the validation results to an RP operator. Invoked by ‘rpstir-results’, it uses query functions offered by MySQL to print the states (valid/invalid/unknown) of signed objects and statistics in terms of states per type of signed object.
Here are some commands that are used to operate RPSTIR:
- ‘rpstir-initialize’: To initialize the application.
- ‘rpstir-synchronize’: To synchronize with the global RPKI repository with TAL as optional the parameter.
- ‘rpstir-rpki-rtr-update’: To generate RTR output from the validated cache.
- ‘rpstir-rpki-rtr-daemon’: To enable the RTR service.
- ‘rpstir-results’: To show the state of the validated cache.
- ‘rpstir-query’: To inquire about specific information from the database of RPSTIR.
Note that all those commands are performed manually. An operation script is needed if an ISP wants to set up RP servers based on RPSTIR.
Work in progress
The IETF community has been reconsidering the RPKI tree validation to specify an alternative to the certificate validation procedure to go with resource transfers. The RPSTIR team has updated the algorithm validation, and is waiting for the Object Identifiers (OIDs) to be seen, signalling this alternative procedure after the document is published as an RFC.
Many RPs desire some form of ‘local control’. SLURM is therefore implemented and in test in RPSTIR. An analogous capability is available in RIPE NCC’s validator.
RPSTIR is going to support the RPKI Repository Delta Protocol (RRDP) as its next step in the days to come.
Documentation
As previously noted, the different functional elements of an RP system can be considered as components with orthogonal functionalities, so that those components could be distributed across the operational timeline of the user.
Since there is no single reference point for requirements for RP software for use in the RPKI, Dr Stephen Kent and I have written a draft on the technical requirements of the RP. We hope to publish this document as an Informational RFC, to make it easier for implementers to become aware of these requirements that are capable of being segmented, with orthogonal functionalities.
Note
RPSTIR was developed initially by the RPKI team at BBN Technologies. ZDNS has now assumed responsibility for maintenance of RPSTIR, with Dr Di Ma (Labs Director of ZDNS) as one of the administrators of RPSTIR. Dr Stephen Kent acts as an advisor to ZDNS for this effort.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.