
Let’s go do some whois!
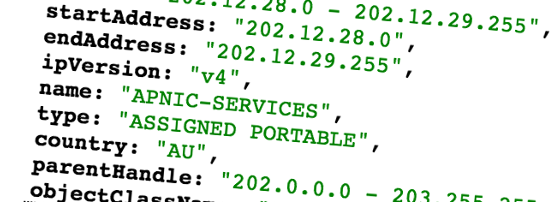
Here’s a whois record for the APNIC Labs research network block 203.133.248.0/24 that I fetched using the command $ whois -h whois.apnic.net 203.133.248.0/24
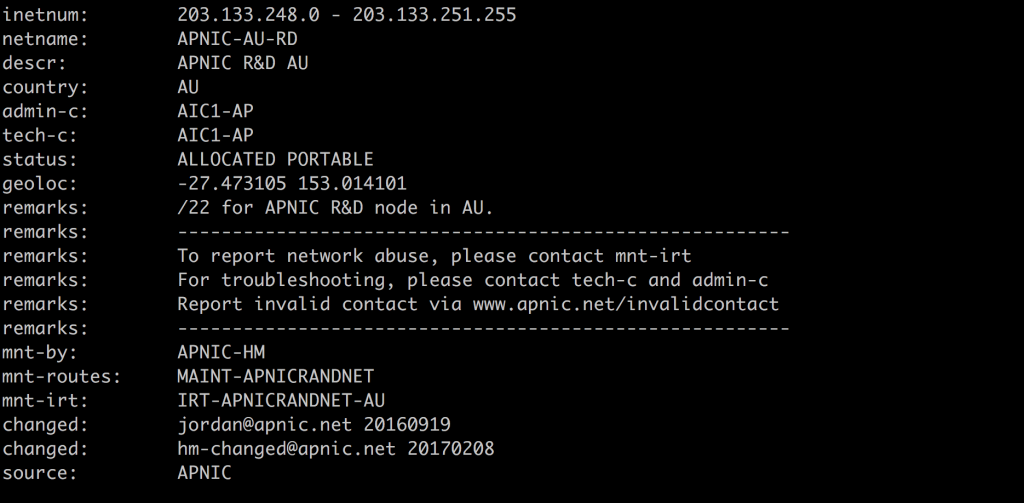
Here’s one for a domain name in Brazil. I got this using whois -h whois.nic.br nic.br
Wait a minute — they are kind of the same, but they use different names for the fields. And anyway, how did you know how to find that whois server? Where did you learn that?
Here’s one for a different domain name. This one is under the .ORG registry. I got this using the command whois -h whois.pir.org pir.org
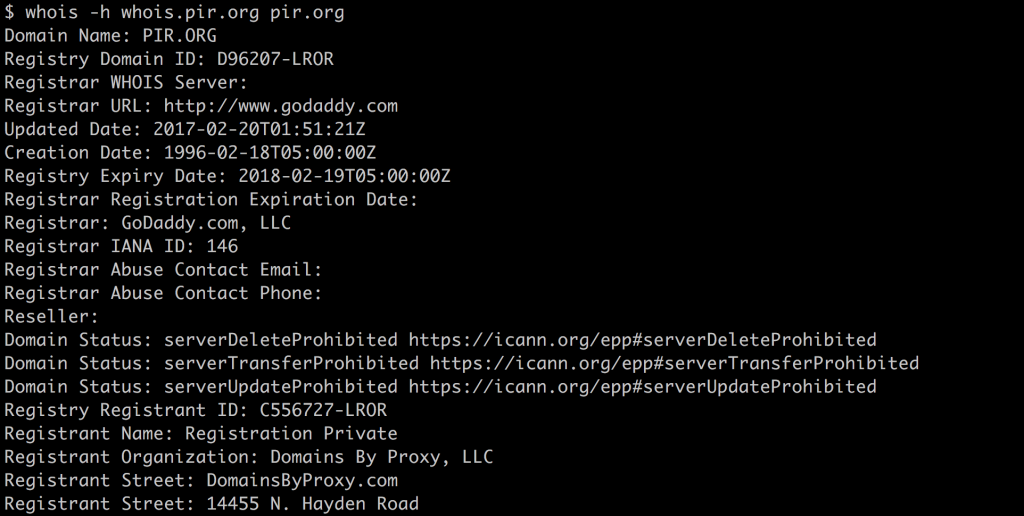
But that’s crazy! It didn’t use the name nic and it uses different labels for the fields, but it’s the “same” as whois for .br, isn’t it? Aren’t they both whois services for names?
And again, how come it’s pir.org and not nic.org (oh, that exists, but it’s not a network information centre with whois services…).
This is the problem with whois: It’s a mess.
Here we are in a modern age, and yet the load on the public whois service at APNIC continues unabated. It’s believed they’re mostly queries from automatic systems, checking the authority over an IP address, almost certainly from firewall checks, an amount of manual data exploration by law enforcement and IPR agencies, and at the tail end, ISPs doing semi-automatic router configuration.
APNIC’s had no problem scaling service to meet this demand, nor in keeping the whois servers up to date, with new features added continuously (the most recent is the deployment of Organization objects, to bind whois records to the entities that manage them more effectively).
But, having said that, I’m genuinely confused why this traffic continues, when there is a far simpler, better way to query the same information: RDAP, or Registration Data Access Protocol.
Why RDAP?
RDAP is interesting, because it’s better. It’s better suited to its role, and it’s better able to be scaled, and connected worldwide. It’s also significantly better to interact with, from a data perspective, because it’s JSON-specified data.
Scaling
Scaling RDAP is as simple as normal web load distribution, because it IS normal web. It’s a protocol specified on top of HTTP or HTTPS, so the exact same methods used to scale load for the web in general can be applied. It can be built out in a CDN, cloud provider, outsourced, or use commodity replication and forwarding methods.
Whois, by contrast, is a very simple protocol, but you have to work quite a lot harder to make it distribute and scale. It’s not currently economically viable for CDN providers to target whois protocol, so we have no commercial operators to outsource from.
APNIC has used lower-level data replication systems to manage load, but they require more hand-tuning and management. CDN localization would require APNIC to do explicit DNS-based tricks, or deploy anycast, which some people think has risks in TCP-based protocols (I don’t see it, but the fact remains it is an objection some people state).
Connectivity and global applicability: referrals and JSON over free-form text
RDAP has global connectivity because it operates from an IANA registry. All RDAP services in either names or number space have their entry point in a well-known bootstrap registry in IANA, and because RDAP runs over HTTP, the web redirect code (the so-called 302 redirect) can be used to pass back to a client ‘where to do’ for a specific request.
This is a huge advantage, compared with whois, which has no common bootstrap registry, nor an agreed mechanism to refer clients on (subsets of whois do use some mechanisms, but these are not globally applicable or defined for all whois contexts).
You can’t easily write one client to handle all whois, and even within the Internet number space, you can’t write one client to handle all RIR or NIR data without a lot of effort. As data moves between RIR entities, with market transfers, this becomes a bigger problem. In RDAP, the redirection mechanisms mean you can drive down the delegation tree and find the right RDAP service in almost all cases.
Because RDAP is an encompassing JSON specification, one RDAP client can expect to deal with almost any RDAP server. It’s possible data elements might be seen that aren’t expected, but these will be skipped, if need be. It’s not going to cause data parsing problems. In whois, we have no single specification of data; instead, we have some whois sites using unstructured text, some using type:value forms in records, some using more formally defined type:value constructs like those specified in RPSL.
Internationalisation
Whois has no internationalisation model. It is not clear if data can be specified in anything but ASCII, and the protocol specification actually assumes ASCII is being used. Some NIRs in the RIR system use local-language data, and send UTF-8 with an additional English-language ASCII element, but this is informal.
RDAP, on the other hand, explicitly enables UTF-8 and in the personal contacts information uses VCARD data, which can denote local- and preferred-language options for names and addresses. This is far more useful for law enforcement agents/agencies (LEA) and non-local users who can understand what parts of a contact are naming, addressing or other information, or can be handed off to local agents to work with, irrespective of their English-language abilities (if the data is in both English and a local script, for instance).
A security model
In RDAP, it’s possible to specify credentials for access using HTTPS. The protocol authors have been working on a specification of the use of OAUTH mechanisms, so a common authentication framework could be built. This means that a given data source — for example, Belgium — could authenticate a local user, and give them credentialled access to permit their referred queries into, for example, an American-hosted RDAP server to consume against their budget.
Or, differential levels of access control could be used to hide and show personally identifying information (PII), or set limits on search response volumes. In whois, some whois servers implement IP address-based credentials, or apply limits to PII, but there is no encompassing model. It’s far harder to manage and there has already been instances of other ad-hoc ‘joint’ whois services hitting service limits, or breaching data privacy assumptions.
If RDAP is so much better, why hasn’t usage taken off?
We don’t know how to sell
Well, the first thing is that the RIRs are not always very good at selling themselves. The RIRs don’t necessarily have a good sense of who the software authors writing whois code are, embedded into firewalls or security application suites, so haven’t been able to talk directly with them to “sell” RDAP as a better platform. In principle, this would pay back faster than almost any other engagement, since the software appears to be the predominant driver for whois queries: it’s coming from machines, more than people.
In a similar sense, it’s early days for outreach into LEA and IP rights legal fields, where people are doing manually driven high-level searches, and communication and training into these communities needs to increase.
It’s good, but it’s not yet complete
Secondly, RDAP doesn’t yet have a profile for specifying routing information like that in RPSL, so there are some whois services and Internet-Routing Registries (IRR) that cannot yet be cut over. Work continues to conceptualize a routing profile in RDAP that probably will not encompass all of RPSL, but enough to make it useful for the basics, which specify the origin-AS routing of any given prefix, used to define routing filters.
And again, more recent whois specifications for how to sign data using RPKI, presented in whois, hasn’t been specified yet for RDAP.
These are corner-cases in volume, but highly significant for a subset of whois load and have to be worked on.
It’s good enough, until the story changes
One of the problems here is that, within limits, whois is a solved problem. As far as a firewall vendor, or a law enforcement agent who has their own scripts, is concerned, “it’s working” and “it’s good enough” because they are able to get the answers they need. It doesn’t matter that I think they could get better answers, more complete, more accurate from RDAP, and it doesn’t matter that you can use the same code (mostly) in names and numbers, as much as the benefit of the ‘sunk cost’ of developing whois code has been met.
However, the story can change. Whois wasn’t written in a time of ubiquitous name or number transfers, and carries problems with it accordingly: if your resources move registrar, or move to a new economy, the assumptions about “where to go” to get information break down. In RDAP, it’s far more likely the movement can be understood and followed. So, the more we move into a world with open transfer of resources, the more likely it is RDAP has a benefit to offer.
And in similar ways, the histories of changes against records is not well understood in whois. RIPE NCC has a model for whois history that tracks back against past states of the whois data, but this is limited to the RPSL/RIPE world — AfriNIC and APNIC have this feature too — and also terminates on object deletion: you can’t search past an erased record.
In RDAP, a new ‘history’ mechanism is being specified that is more flexible and globally applicable, and APNIC has already implemented two clients that show the prior states of RDAP history as differences, and can step over deleted records. The more things move, the more likely it is that historical records are important for audit on WHY they moved and WHO moved them, so this feature has a lot of benefits for future use.
Ease of use, ease of change
The best way to demonstrate why RDAP is going to be so much better for future needs is to play with it.
If you have two simple UNIX commands installed, you can play with RDAP very simply. The commands are curl and jq
Command line tool and library for transferring data with URLs
Curl is available here or on a Mac using the brew system. It can be installed with $ brew install curl (a version ships with OSX)
jq is a lightweight and flexible command-line JSON processor.
The source is available here or on a Mac using the brew system.
it can be installed with $ brew install jq
With these two commands, you can immediately see the JSON structure behind RDAP, with a simple query:
$ curl -s https://rdap.apnic.net/ip/203.133.248.0/24 | jq | less
This shows you something like this (this is just an extract):
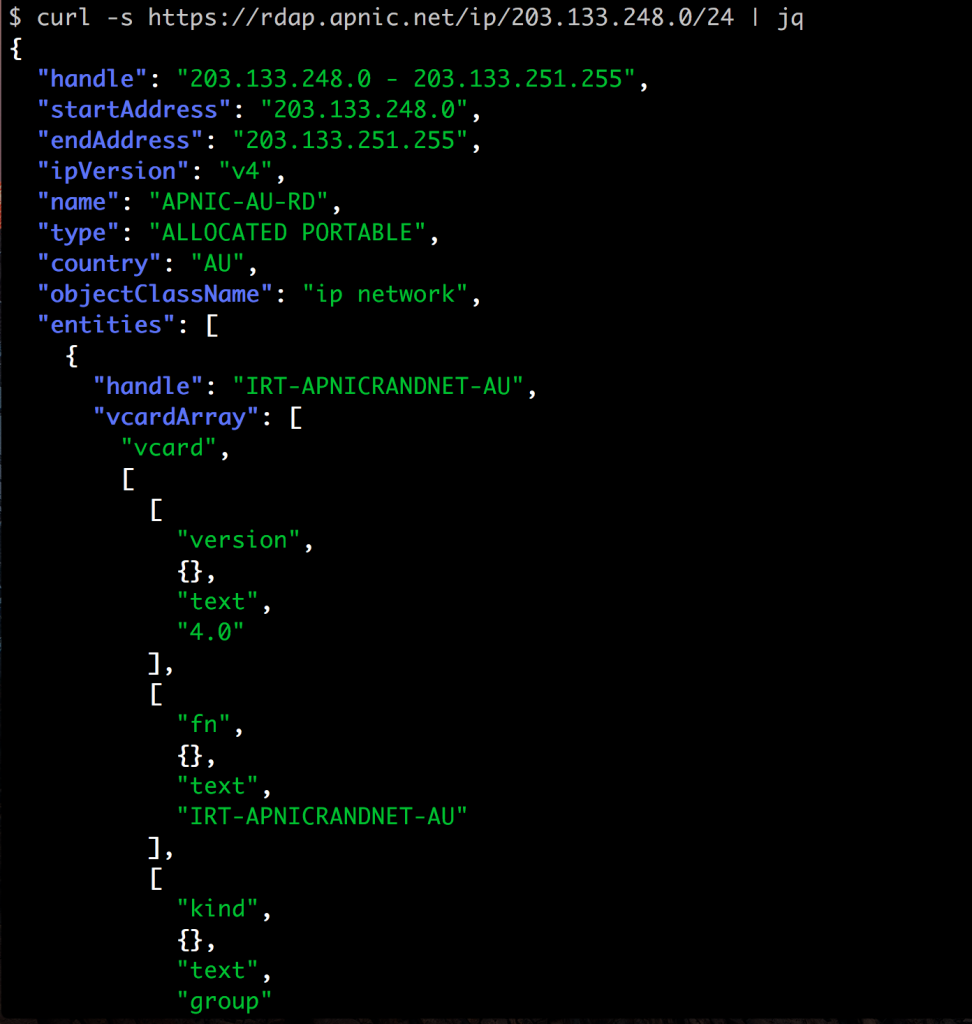
The real power of this tagged data form is that you can use the jq command to extract specific fields. For example, the command curl -s https://rdap.apnic.net/ip/203.133.248.0/24 | jq .events returns this data:
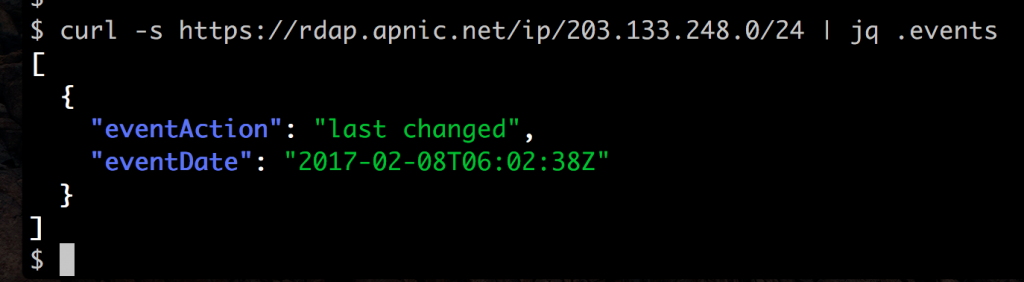
That’s how simple RDAP is to work with. You don’t need a special parsing library to read the data, or have to deal with four or five different formats — you can use standard command line tools (and can use standard JSON code in programming languages like Perl, Python, Ruby or JavaScript) to extract the data elements directly.
And it’s the same form of JSON for names
Here’s an RDAP response from a ccTLD. It’s for the same .br domain I did a whois lookup for. This was fetched from
curl -s https://rdap.registro.br/domain/nic.br | jq which I found from the central RDAP registry at IANA.
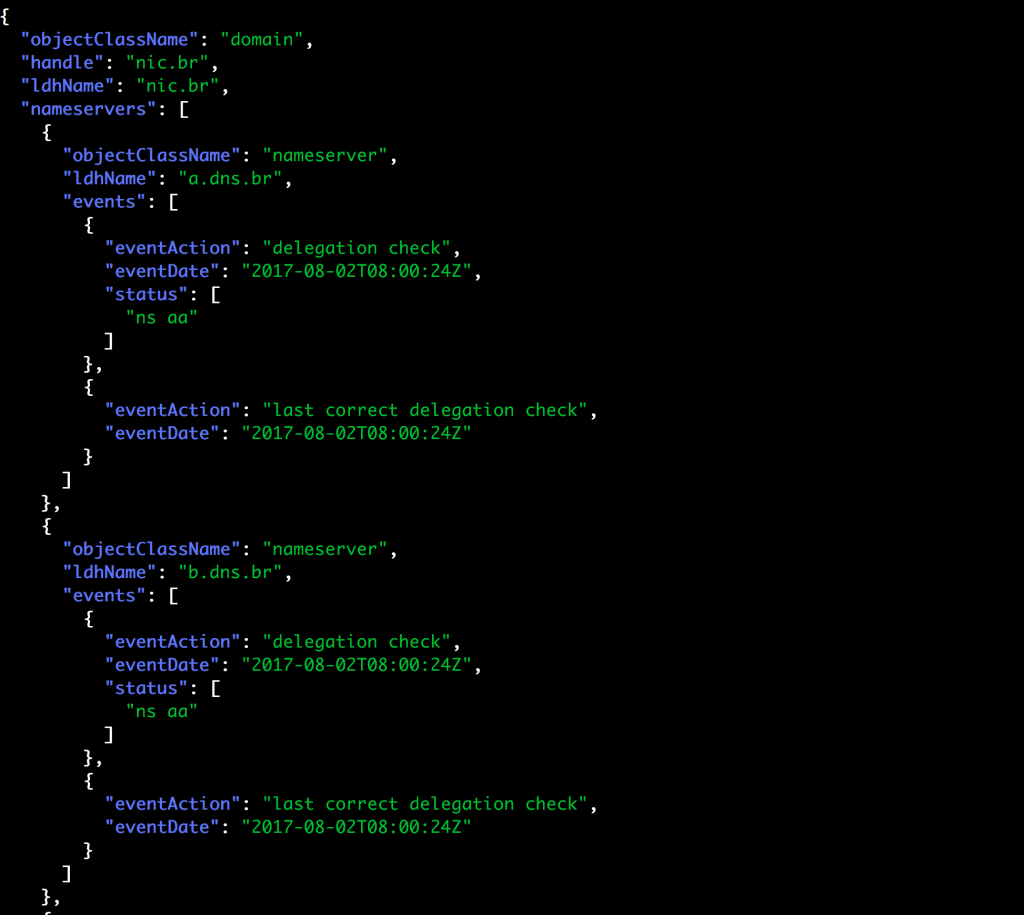
Field ordering may not be the same as the RIR RDAP example, but the field names and their meanings are the same, and it’s far easier to see how we can write one library to handle both forms.
So I ask again: What is holding RDAP back?
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Thats real nice to have data in json which can be easily parse in any applications to show in frontend.
I’m integrating RDAP into a BGP webtool. Very nice to be able to show information automagically without having to code 35 different formats.
I, however, ran into a problem, most of the APNIC delegated ASNs seem to 404 for me. I don’t know if this is a temporary problem or some unfinished work or something broken nobody noticed. Those ASNs which 404 over RDAP, work very well using whois 🙁
My bad, I have found the issue.
Not working: https://rdap.apnic.net//autnum/1234
Working: https://rdap.apnic.net/autnum/1234
Instead of curl … | jq, using NicInfo would be easier:
https://github.com/arineng/nicinfo
For most Unixy OSes, its easy to install:
gem install nicinfo
Hey are the bulk files for registries like AFRINIC, APNIC, LACNIC, RIPE are available in JSON format after RDAP protocol enforcement or are they still using flat-text format ?
The bulk files for each registry are available in flat-text format only at the moment, though the RIRs are working on a common RDAP bulk file format that will be used for publishing that data alongside the flat-text version.
So do you know if they are going to stop publishing flat files in near future which they are currently doing through ftp ?
And is there any blog or QNA post which states if they are working on creating the RDAP standard bulk files ? If there is, could you please share it. Thank you.