

In November 2014, after quite some controversy in the IETF OPSEC working group (for those interested look at the archives), the Informational RFC 7404 “Using Only Link-Local Addressing inside an IPv6 Network” was published. It is authored by Michael Behringer and Eric Vyncke and discusses the advantages and disadvantages of an approach using “only link-local addresses on infrastructure links between routers”.
So it’s (merely) about “infrastructure links”, which some people call “transit networks” or “point to point” (ptp) links. I’m aware that there might be subtle differences between all these, depending on your specific use of the terms. Still, I assume that most readers will have an understanding of what types of links are in focus of the RFC, and subsequently of this post.
Eric Vyncke explained RFC 7404 on the APNIC Blog earlier this year.
The RFC lists the following potential advantages of such an approach:
- smaller routing tables (and subsequently less memory consumption on routers and possibly faster convergence times).
- simpler address management (as one doesn’t have to allocate and manage address ranges for these links). I’d like to add that in enterprise space this may lead to significant resource savings in their IPAM systems also (see case study below).
- lower configuration complexity (as of the RFC assuming that no configuration is needed at all). Many people have pointed out that the approach might only make sense when actually specific link-local addresses (= potentially the same ones on many links) are configured which might decrease the / render this (perceived advantage) debatable. On the other hand there are people who think that exactly this capability – to configure the same addresses on many links – can be very helpful, namely in the space of (decreasing) complexity. (again, see case study below)
- simpler DNS (less addresses to put into DNS). Of course (and the RFC mentions this) this only applies once every link address actually has corresponding DNS entries, which from our experience, quite often does not apply.
- reduced attack surface, as link-local addresses can not be reached (=> attacked) from remote networks. Here, some critics have pointed out that the same goal can also be achieved with other means (like the “Generalized TTL Security Mechanism (GTSM)” mechanism laid out in RFC 5082. See also section 5.2 of RFC 7454 “BGP Operations and Security”.
On the other hand, the RFC lists the following potential disadvantages of the LLA-only approach:
- interface pings can only be performed from a node on the same link. While some people on the mailing list have cited this one as major disadvantage as well, I don’t fully share this. From my experience being able to ping the loopback address (combined with traceroute when the actual path is needed) is good enough for most troubleshooting scenarios.
- same for traceroute. Here many people have pointed out that in case of traceroute having the actual interface addresses would be very helpful. I partially agree with this one but, again, I’d say that seeing the loopback address in a traceroute is good enough in quite a few cases.
- hardware dependency (in case of LLAs based on EUI-64). Pretty much everybody I know wouldn’t go with an EUI-64 based approach anyway (but with something along the lines of fe80::1 and fe80::2) so I don’t really consider this relevant.
- NMS tools (might need different data collection approach), as any NMS functions directed at interface addresses obviously will no longer work. I consider this one as the most significant obstacle as this would require a somewhat different data collection/monitoring paradigm in some environments I know. Which in turn can certainly be done but requires effort, and in general operations people (like most humans) don’t like changing their practices and procedures…
Overall the RFC does not provide a final recommendation but states:
“A network operator can use this document to evaluate whether or not using link-local addressing on infrastructure links is a good idea in the context of his/her network.”
Let’s now have a look at a case study in one of our customer’s environments. That organization is a very large enterprise (200K+ users, many subsidiaries) in the manufacturing industry sector. They have an own wholly owned IT operations provider (think “XY systems”), hence the OEs within the group are considered “customers” (from that internal provider). XY systems operates a company-wide MPLS network spanning several countries. The main platform for PE devices is Cisco ASR 1006 and 1013 running IOS XE 03.10.
There’s a group level IPv6 project ongoing in the course of which going with an LLA-only approach for PE-CE links (with identical addresses on all affected links) was identified as one of the main architecture benefits of IPv6. This would roughly look like this (illustration from lab):
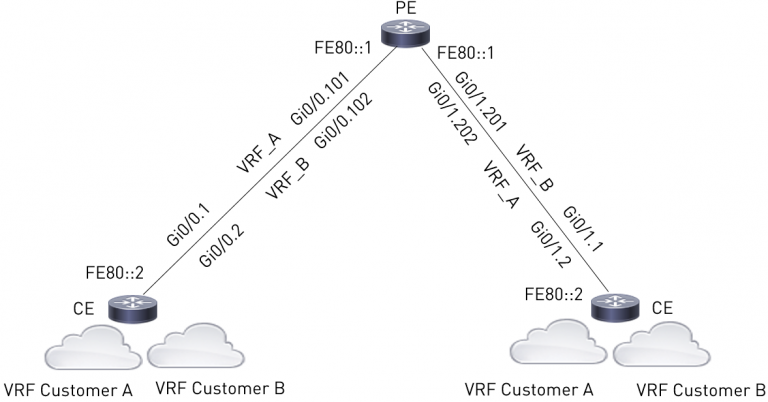
I won’t discuss their reasoning in detail here, but trust me: they’re smart people and they have good reasons for this decision. Amongst others it should be noted their IPAM database currently holds 43,200 networks, 20,600 (47.7%) of which are point-to-point networks.
Unfortunately, when testing the planned configuration in the lab, the following happened (during configuration of the second BGP peering):
muc-pe3(config-router-af)#neighbor FE80::2%GigabitEthernet0/0/0.4711 remote-as 65000
muc-pe3(config-router-af)#
*Jan 1 00:17:46.964: %BGP-3-NOTIFICATION: sent to neighbor FE80::2%GigabitEthernet0/0/1 6/6 (Other Configuration Change) 0 bytes
*Jan 1 00:17:46.964: %BGP-5-NBR_RESET: Neighbor FE80::2%GigabitEthernet0/0/1 reset (Remote AS changed)
*Jan 1 00:17:46.965: %BGP-5-ADJCHANGE: neighbor FE80::2%GigabitEthernet0/0/1 vpn vrf customer42 Down Capability changed
*Jan 1 00:17:46.965: %BGP_SESSION-5-ADJCHANGE: neighbor FE80::2%GigabitEthernet0/0/1 IPv6 Unicast vpn vrf customer42 topology base removed from session Capability changed
*Jan 1 00:17:59.391: %BGP-3-NOTIFICATION: sent to neighbor FE80::2%GigabitEthernet0/0/1 passive 2/2 (peer in wrong AS) 2 bytes FC58
*Jan 1 00:17:59.391: %BGP-4-MSGDUMP: unsupported or mal-formatted message received from FE80::2%GigabitEthernet0/0/1:
What happens here is that the configuration of the remote-as statement corrupts (actually: overwrites) the first BGP peering’s remote-as which, evidently, brings down the first BGP session. It turned out that this is common behaviour (on different platforms and releases) and it’s documented in the Cisco Bug Report CSCuy05100.
So essentially the planned design and configuration approach currently does not work, due to lack of vendor support at the moment (May 2016). They hope it will be fixed soon, though.
(One may note that, ironically, guys from the same vendor authored the RFC laying out the approach).
To summarize I’d like to draw some conclusions from the above:
- Enterprise organizations start to realize that IPv6 can bring (not only pain and increased ops effort, but also) architecture benefits, based on paradigm shifts. This is a good thing!
- There might (still) be severe limitations with regard to vendor support of certain features. This is, well, unfortunate. I mean, it’s 2016…
- If planning for IPv6 you MUST test things. Of course you all have well-equipped test labs, right?
I gave a talk on the topic at RIPE72 last week. The slides and the video of the RIPE72 talk can be found here and here.
Furthermore we’re working on a post on the recently published “IPv6 Neighbor Discovery Crafted Packet Denial of Service Vulnerability” (I hesitate calling it a “new” vulnerability…), so stay tuned.
Original post appeared on Insinuator
Enno Rey is a long-term IPv6 enthusiast with lots of practical experience in the space.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.