
As part of a 2014 project supported by ISIF Asia and Internet NZ, we’ve been going to a number of satellite-connected islands in the Pacific on behalf of the Pacific Islands Chapter of the Internet Society (PICISOC) to see whether we could make better use of their satellite links using network-coded TCP. One of the phenomena we came across even before we got to the network coding part seemed a bit of an oddity at first. At second glance offered an opportunity to look and learn.
Let me paint you a scenario: You have a remote Pacific island with a few thousand inhabitants. There’s plenty of demand for Internet, but the place isn’t overly wealthy, so the only affordable way to connect it to the rest of the world is via a geostationary satellite system. Bandwidth on such satellites is very expensive, so our island needs to make do with inward bandwidth in the tens of Mbps – anything more breaks the bank. Both locally and offshore, the satellite link connects to something that can carry hundreds or thousands of Mbps.
Now you talk to plenty of islanders and you get to hear the horror stories of web pages that never load, computers that never see an update, connections that time out, and so on. So if you could eavesdrop on the satellite link, what would you expect to find?
I guess that, like us, you’d expect to find the link hopelessly overloaded, with packets rushing across it nose-to-tail without gaps, and TCP connections timing out as their packets fail to even make it on the link. You’d expect to see nearly 100 per cent of the link’s bandwidth in use nearly 100 per cent of the time. Remember, a satellite uplink is exclusive, so as long as there is data, the link will be busy – we don’t need to leave polite gaps for other parties to barge in like on Ethernet or WiFi.
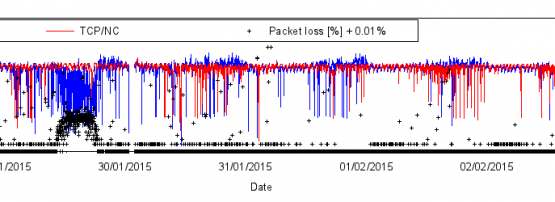
So imagine our surprise when we looked at the bandwidth utilisation in a couple of locations and found it to be well below 100per cent. One large island never saw more than 75per cent even during time periods of just a few seconds, with the average utilisation being around 60per cent. Another island didn’t tap into more than one sixth of the theoretically available bandwidth. Looking at the same links, we found that burst packet losses occurred the moment we started offering a modest UDP load.
Seems weird? Not quite so. The effect is actually quite well described in literature under the heading “queue oscillation”. It’s generally associated with router queues at Internet bottlenecks. So what is it, and why is it happening on geostationary satellite links?
What is queue oscillation?
Firstly, let’s look at what happens when a TCP data packet from the Internet arrives at the satellite link. It’ll have been sent by a TCP sender somewhere on the Internet, generally sometime between a few milliseconds and a few hundred milliseconds earlier. As it gets to the transmitting satellite modem, the packet is put into a packet queue awaiting transmission.
An important factor is that multiple TCP connections – typically at least a few dozen – share our satellite link. These all have senders that are a varying number of milliseconds “away” from the modem. Their packets mix and mingle with ours in the queue. All TCP connections try to reach some sort of steady transmission rate across the link, and all try to “fill the pipe”, i.e., get to the highest rate possible.
To fill the pipe, TCP increases its sending rate as long as it receives acknowledgements from the far end. Now consider multiple TCP connections doing this more or less simultaneously: A little increase in sending rate at each TCP sender turns into a whopping big increase in arrivals at the satellite modem a little while later. A potential consequence is that the queue at the satellite modem may overflow.
An overflowing queue means that any further arriving packets need to be dropped. This means that most packets currently enroute to the modem are doomed. Even those not yet transmitted by the TCP senders are doomed as the senders continue to be oblivious to the queue overflow (and associated packet loss) until the ACKs for the lost packets become overdue at the TCP senders. Here are our burst packet losses.
After roughly one satellite round-trip-time and whatever time it takes for an ACK packet to get from satellite modem to TCP sender, the senders notice that something is amiss. Like a remorseful alcoholic, each sender now reduces its packet transmission rate. With further ACKs remaining overdue from the burst loss, this reduction becomes rather drastic. With multiple TCP senders acting alike, the queue at the satellite modem sees its arrivals slow down to a trickle.
The modem itself keeps transmitting as long as there is data in the queue. However, with almost none being resupplied, the queue can run dry and the link idles. Here is our link underutilisation.
Once the senders see ACKs again, the packet rates increase again and the oscillation cycle repeats.
Note that we don’t expect to see queue oscillation at every point where high bandwidth meets low bandwidth, though. For example, think of fibre optic signals heading for a DSLAM to provision residential ADSL connections. We demonstrably don’t encounter the phenomenon there. Why? Note that two key ingredients in queue oscillation are multiple independent TCP connections and the long latency that prevents timely feedback to the sender. Neither of these are typical for residential ADSL connections.
Think of it this way: You’re trying to pour expensive wine from a (wideband) barrel into a bottle, using a funnel (your queue). The goal is to fill the bottle as quickly as possible, while spilling an absolute minimum of the valuable wine. To do so, you’ll want to ensure that the funnel (your queue) is never empty, but also never overflows.
Imagine that you do this by yourself and that you get to hold the barrel right above the funnel. Sounds manageable? It probably is. Now imagine that you put the bottle with the funnel under the end of a (clean) downpipe, and you get a few friends with barrels (your broadband TCP senders) to tip the wine into the (clean) gutter on the roof. You watch the funnel fill level at ground floor and let your friends know whether to pour more or less in. Bet that filling the bottle is going to take longer with a lot more spillage this way, even if you’re all completely sober? Why? Because your friends have no control over the wine that’s already in the gutter and the downpipe – it’s this wine that causes the overflows. Similarly, if you run out of wine in the funnel, new liquid takes a while to arrive from above.
Remember the telltale signs of queue oscillation: Underutilisation of a bottleneck link interspersed with (burst) packet loss.
My queue oscillates: What now?
OK, so you’ve looked at your satellite connection and it’s showing all the signs of queue oscillation. You’re in effect paying for a lot of bandwidth you never really use. What can you do?
First of all – there’s no way of stopping queue oscillation completely: If we could do that, there’d be no point in having a queue. The problem here isn’t so much that our queue oscillates, it’s that it oscillates in the extreme. We want to ensure that the queue never runs out of data.
OK, so your first reaction might be: “Let’s increase the queue memory”. That’s like having a bigger funnel on top of your bottle. This means that as the queue fills up, it takes a little longer to get to the point of overflow. This makes the link look as if it had more latency, which in turn acts as an incentive for the TCP senders to pump more data into the connection while waiting for the acknowledgements to come back. So eventually, the queue still overflows, and we still get these packet losses – except that it now also takes a little longer for the packet losses to be noticed by the senders: This means that we get longer burst losses, and an even more cautious back-off by the senders. So the best we can expect here is that the queue won’t oscillate quite that quickly. But it’ll still oscillate.
Another approach would be to limit the rate at which packets arrive at the queue – but how would we do that? Explicit congestion notification (ECN) is one option. In this case, the satellite modem monitors its input queue and sends a warning of impending congestion to the TCP sender. This only works if the TCP sender understands ECN – not a given: As a rule of thumb, most servers will accept ECN if requested on incoming connections, but most clients will by default not request it on outgoing connections. As most connections are initiated by clients at the island end, such requests are not normally made. Moreover, impending congestion is communicated to the TCP sender by way of the TCP receiver – which means that our senders still have plenty of time to overload the queue until the congestion notification arrives. That’s also not ideal.
Yet another alternative would be to limit the number of connections – remember that it’s the concerted response of multiple connections to the packet loss that aggravates the effect here. So we could in principle divide our satellite link into several parallel links with lower bit rates and separate queues, and only run a limited number of connections across each of these sub-links. Fewer connections per link and a lower processing rate per queue might indeed save us from oscillation here. The price we pay is that connections are now severely rate-limited: If we only have a single connection wanting to use the satellite, it is now restricted to using a single sub-link rather than the whole bandwidth of the satellite. That’s bandwidth inefficiency creeping in again through the back door.
Tackling queue oscillation with network coding
A solution that we have been experimenting with as part of the project is the use of network-coded tunnels. Network coding is a technology fresh out of the labs, and in this case we’ve been using a solution pioneered by colleagues at the Massachusetts Institute of Technology (MIT) in the U.S. and Aalborg University in Denmark. The idea behind network coding is quite easy: Remember the good old days at school when you were made to solve systems of linear equations? Like these:
4x + 2y + 3z = 26
2x + 5y + 2z = 19
3x + 3y + 3z = 24
From these three equations, we can work out that x = 3, y = 1, z = 4. Remember that as a general rule, you need at least as many equations as you have variables to work out the value of the variables. Now, packets are really just binary numbers, so we can treat them like variables. At the entrance to our tunnel (the “encoder”), we take a certain number of incoming data packets (say, 3, and let’s call them x, y and z for simplicity). That’s called a “generation”. We then generate 3 random coefficients to multiply x, y and z with, add the results up, and voila – we have an equation. If we repeat this three times, then with a little luck we have enough equations to compute x, y, and z from. Just to be on the safe side, we could also generate another couple of equations this way.
We now absorb the original packets and, in their place, send the coefficients and result for each equation in a “combination” packet. So our first combination packet would include (4, 2, 3, 26), the next (2, 5, 2, 19) and the third (3, 3, 3, 24), and so on. At the far end of the tunnel (the “decoder”), we use the combination packets to recreate and solve the system of linear equations – and out pop x, y, and z, our original packets!
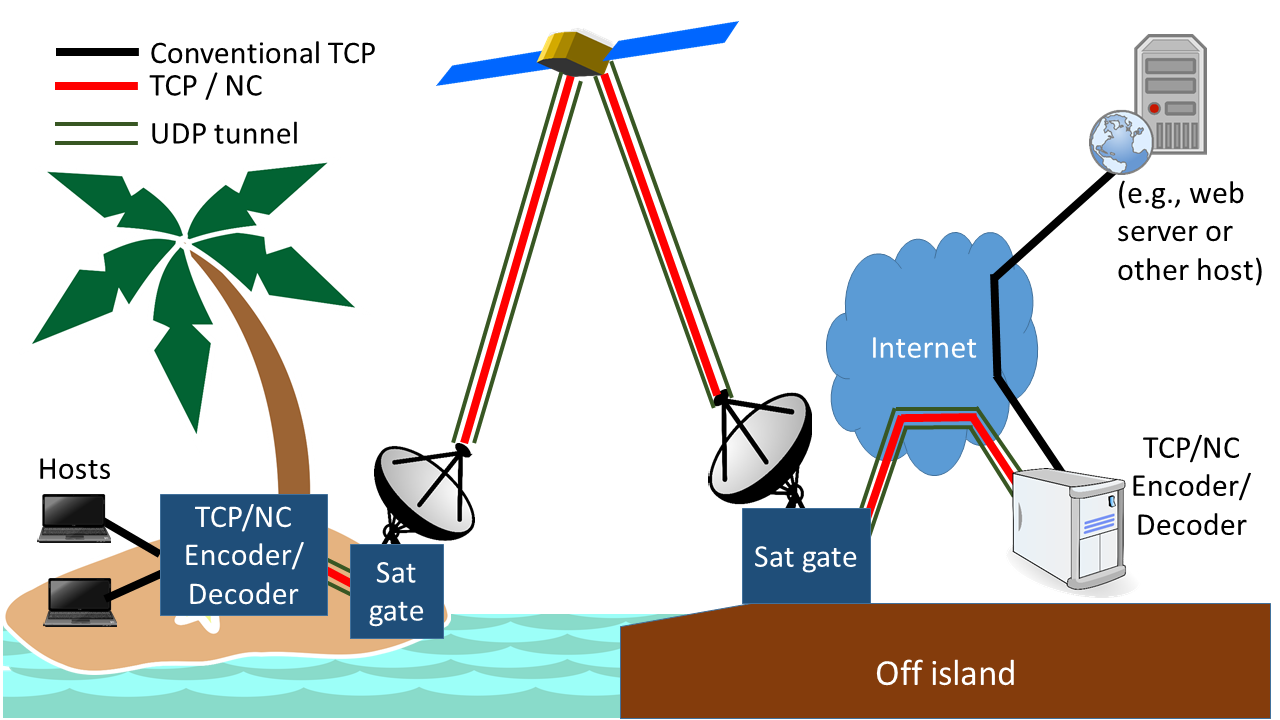
Network topology of a network-coded TCP tunnel. Note that the “mainland” encoder can be anywhere on the Internet – except on the island, of course
We build our tunnels such that one end is on the “mainland” and the other on the island. Between them, the coded combination packets travel as UDP. So how does this help with queue oscillation? Simple: We generate a few extra “spare” combination packets, so that we now have more equations than variables. This means we can afford to lose a few combination packets in overflowing queues or elsewhere – and still get all of our original packets back. So TCP doesn’t see the packet loss, and as a result there’s no need for the TCP senders to reduce their sending rates.
TCP over network coded tunnels
Does this actually work? Yes it does. How do we know? We have two indicators: Link utilisation and goodput. In our deployment locations with severe queue oscillation and low link utilisation, we have seen link utilisation increase to previously unobserved levels during tunnelled downloads. The tunnelled connections (when configured with a suitable amount of overhead) provide roughly the same goodput as conventional TCP under non-oscillating low packet loss conditions. Tunnelled goodput exhibits a high degree of stability over time, whereas that of conventional TCP tends to drop mercilessly under queue oscillation.
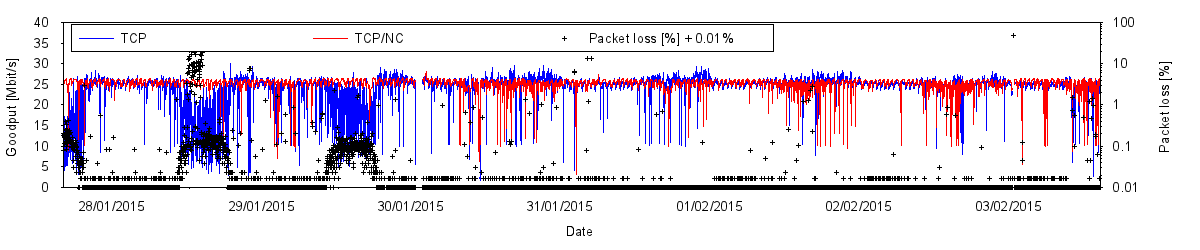
Performance of a network-coded tunnel (red) with 20% overhead compared to standard TCP (blue). During periods of high packet loss on 28/1 and 29/1, standard TCP performance collapses while the network-coded tunnel shows no impairment. At times of low packet loss, goodput can still decrease as a result of heavy traffic load in the shared bandwidth. A network-coded tunnel with lower overhead would outperform standard TCP by up to 20% during these periods
“So, tell us, how much better are the network-coded tunnels compared to standard TCP?” Let me note here that we can’t create bandwidth, so this question can be largely reformulated as “How bad can it get for standard TCP?” We’ve seen standard TCP utilise between roughly 10per cent and 90per cent of the available bandwidth. On the island with 60per cent average utilisation, we were able to achieve goodput rates across our network-coded TCP tunnel that were up to 10 times higher than those of conventional TCP – during the times when conventional TCP struggled badly. At other times, conventional TCP did just fine and a network-coded tunnel with 20 per cent overhead provided no extra goodput.
So far for the good news. The trick to getting this to work well in practice is to get the amount of overhead just right. If we don’t supply enough combination packets in a generation, we risk that burst losses aren’t covered and the encoded TCP connections will suffer packet loss and slow down. If we supply too many combination packets, we’ll have large numbers of surplus combination packets taking up valuable satellite bandwidth. That’s also undesirable. What we really want is just enough combination packets to cover the burst packets losses.
Now, that’s nigh impossible in practice. However, consider a link that frequently idles due to queue oscillation. If network coding lets us use some of this capacity, then we can afford to pay a small price by spending some of the spare capacity on transporting redundant combination packets. Our observations to date indicate that overhead requirements fluctuate relatively slowly over the day, so we’re currently discussing with the supplier of the software we’ve been using, Steinwurf ApS of Denmark, to see whether they can add feedback from decoder to encoder for us.
Deploying network-coded TCP tunnels requires careful network design, too. Any TCP packet destined for a machine served by a tunnel has to be able to find its nearest tunnel entrance. These entrances are best positioned close to where we’d expect most of the data to come from. In most cases, that’s not the location of the off-island satellite gateway! Simultaneously, we can’t simply route the whole traffic for the island to the tunnel endpoint – we still need to ensure that the on-island decoder can be found via the satellite gateway. That’s a topic for another day, though!
[Joint work with ‘Etuate Cocker, Péter Vingelmann, Janus Heide, and Muriel Médard. Thanks go to Telecom Cook Islands, Internet Niue, Tuvalu Telecommunications Corporation, MIT and, close to home, to the IT operations people at the University of Auckland for putting up with a whole string of extremely unusual requests!]
Ulrich Speidel is a senior lecturer in Computer Science at the University of Auckland with research interests in fundamental and applied problems in data communications, information theory, signal processing and information measurement.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Take a look at Kwicr (http://www.kwicr.com/) which uses similar coding technique to deploy on mobile video.
Disclaimer: I am one of developers of the RLNC kernel module at Steinwurf ApS.
We are delighted to see the ongoing discussion about this blog post on Hacker News: https://news.ycombinator.com/item?id=9208644
Let me address some of the questions raised there:
1. Note that we have no control over the satellite link. We cannot change its underlying properties. We intend to improve the apparent link quality by “masking” the packet losses.
2. RED is typically used with ECN which we discussed in this post. When using RED, the TCP senders would not learn about the packet losses at the sat gate before the expiration of at least one end-to-end RTT . RED would not protect against the concerted rate adjustment action of multiple TCP senders.
3. The precondition for using a Performance-enhancing proxy (PEP) is having a TCP variant that works well over your satellite link (in the presence of losses). Unfortunately, our measurements indicated that Hybla and H-TCP are not up to this challenge. Fairness among the concurrent TCP connections is also a huge concern. In theory, a PEP could also operate over the NC tunnel (we could use Cubic TCP in this case).
4. TCP/NC is not more aggressive than vanilla TCP. We have not modified the congestion control algorithm in any way. The tunnel operates on the IP layer, so it does not even distinguish TCP and UDP traffic. Actually, we send more packets with TCP/NC, since we do forward error correction. For a fair comparison with vanilla TCP, we can envision a scenario where most connections of an island nation go through the NC tunnel. The aggregate goodput of these TCP connections would be much higher, since they would not be destroyed by packet loss. There were some attempts to create TCP variants which “ignore packet losses” (e.g. Hybla), but providing fairness seems to be a major challenge even for a very small number of connections. In practice, low fairness also means low aggregate goodput.
5. RLNC was chosen here, because it is an efficient rateless code, both in terms of throughput and redundancy. Other rateless codes might also work, but they generally require higher redundancy, very large block sizes or they are just very expensive.
6. The RLNC patent rights are licensed to Steinwurf ApS. In fact, our user-space RLNC library is available for free for non-commercial research and teaching: http://steinwurf.com/license/
OK, I understand that network coding could overcome the effects of queue overflows, especially when you have a traditional single queue and no way to change this. (So would a smarter scheduling policy in the satellite bottleneck router, but that wasn’t an option – or deploying an appropriate PEP on the end of tunnel outside of the satellite equipment).
I see two cases:
(1) All endpoints using the satellite share a network-coded tunnel: In which case this becomes a form of PEP.
(2) Not all flows use the network-coded tunnel:
Masking loss from TCP would then seem like a major change to the TCP congestion control algorithm. Without this you just seem to have disabled TCP’s ability to share and react to congestion using a layer below TCP, which also isn’t really a new solution for a dedicated satellite link. How does the network coding layer handle congestion and fairness?
Two comments here:
Firstly, the encoders/decoders do not need to sit topologically close to the satellite gateway (in the case of the plot in the blog, the off-island encoder sits in New Zealand and the satellite gateway in Hawaii). Also, the tunnel doesn’t break the TCP connection like a PEP does – the IP packets that go into the encoder are the same that later egress from the decoder. A PEP breaks the transport layer connection and establishes a data pipeline between separate connections at the application layer. TCP/NC breaks the flow at the network layer but keeps the transport layer intact (NB: this also makes it possible, in principle, to use both PEP and TCP/NC).
Second: We don’t tamper with the TCP congestion control at all. What we do is replace a lossy section of the end-to-end link with one that doesn’t exhibit (as many) losses, and we do so by utilising the spare capacity that the queue oscillation leaves behind. If there is no spare capacity from queue oscillation and the sat link carries near 100% of its capacity as goodput with only the inevitable packet header etc. overhead, then network coding gives no advantage. Ideally, all TCP flows ought to be going through the tunnel, however in practice this is difficult to achieve in a pilot project when you’re experimenting with the only link that the island has to the outside world 😉
So when there’s a conventional and network coded flows on the sat link at the same time, the network coded flows will not back off as much as the conventional ones will once there is packet loss. However, this simply means that they keep feeding the queue when it would otherwise run empty. Remember that the back-off here is largely a concerted over-reaction aggravated by the long RTT.
I see, but I disagree a little.
You comment on PEPs: These come in a wide variety of forms – some products can be used across tunnels in exactly the same topological placement as you describe. Most (?) would perform some split-tcp function – probably not splitting the initial SYN to allow end-to-end negotiation. I agree your approach is different and avoids transport splitting.
However, by “hiding” the loss from the end-to-end TCP (or other transport) session, I assert that you are in fact modifying the flow’s congestion control behaviour relative to other traffic sharing the network. This is in effect using a TCP protocol variant that is resilient to loss and inhibits congestion response. That’s a significant change that can have many undesirable side-effects for other non-NC flows (especially ones that react differently to loss than TCP).
You say “Remember that the back-off here is largely a concerted over-reaction aggravated by the long RTT.” – it’s due to the buffering choices implemented in your equipment. (We have satellite equipment that does not have this specific issue). It seems likely to also be due to lack of a modern queue management in your satellite equipment, (e.g. use of FQ, SFQ, etc).
It’s a chicken and egg type situation. Not all satellite links oscillate badly. Those that don’t can get their link utilisation up to very high percentages, with almost all of the traffic being goodput. If we mix NC and non-NC flows in those scenarios, the NC flows eat into the bandwidth of the non-NC ones as you suggest, but in these cases, we don’t need NC in the first place. In cases where the links oscillate heavily, the impact on conventional TCP is low because the conventional flows are already badly impaired by the oscillation and the NC flows simply take up capacity when the others don’t.
In cases where the oscillation is so-so, there is some impact, but ultimately ideally in cases like these we’d only have NC flows, in which case things would even out again as any losses are spread across the NC flows. The splitting into NC and non-NC is really just a feature of pilot projects (although one ISP involved wondered whether they might be able to use NC as a premium service).
Basically, think of NC as an answer to the question “How can I access the spare bandwidth on the satellite link that queue oscillation leaves me with?”
Queue management: Fair comment indeed, but neither we nor the ISPs we work with have any influence over this (or even insight into how the queues are managed) – the ISPs simply buy the satellite service and in some cases, the satellite provider even manages part of the island side infrastructure on behalf of the ISP. The problematic queue is in all cases within the satellite providers’ equipment.
The satellite providers might have choice here, but in how far they are exercising this choice wisely is obscured from us. There is also the question in how far different queue management can prevent the oscillation effect while the RTT delay in the feedback loop persists. The only queue management tools the satellite modem has at its disposal – regardless of algorithm – is to drop packets or send congestion notifications, and these all take at least one RTT to have an effect on the queue arrival rate.
Useful discussion ! I loved the information ! Does anyone know if my company might be able to get a sample a form copy to type on ?
Hi Luis, my business partner accessed a blank a form with this link https://goo.gl/PX25xN.
Hello Ulrich,
Have you considered testing what benefits you might have from using SCPS-TP or TCP Vegas? Alternative implementation of more specialized TCP stacks have been a focus in particular to address defense related challenges. 1000ms+ link characteristics are not atypical in particular when dealing with “double hop” satellite links. Implementation of these stacks is support on most routers ( at a relatively modest cost ) and network optimizer ( Cisco and Riverbed to name two – but there are many others ) . Good on you for helping improve the user experience in the Islands!
Hi Mike,
We sure have – in fact we tried with various stacks point-to-point – the results were quite mixed. The basic problem is that it’s relatively easy to develop a TCP stack that will support multiple large parallel downloads over sat link for a small number of sessions (and I note here that the traditional view of a sat link is more or less that). Queue oscillation doesn’t occur on every link – it takes a combination of significant demand, restricted capacity and delay in order to see it in the wild. In one of our links, QO doesn’t show its ugly head until demand grows to around 2000 connections/second. We’re also currently learning how difficult (and expensive) it is to build a test bed that can truly replicate such scenarios.
In our specific scenario, we really have no control over the TCP stacks at either end of the connections that the sat link carries – the offshore server might be Google in California and the on-island machine might be that of an old codger running Win XP. So it’s a choice between either breaking the end-to-end principle or tunneling the IP (which is what we do).
Have a look at my more recent blog entry http://blog.apnic.net/2016/06/15/life-internet-satellite-link/ for some more discussion on the topic.