

Co-authors of the original paper: Rushi Jayeshkumar Babaria, Gustavo Batista and Vijay Sivaraman
Network flow classification has been an important topic for our Internet community, as it plays an enabling role for network operations tasks ranging from attack detection and usage accounting to application user experience measurement and optimization.
Over the past 20 years, flow classification techniques have evolved from static signature matching on packet header fields (IP address, port number, protocol ID, and so on) and payload bytes, to Machine Learning (ML) classifiers that determine flow types by their time-series packet statistics. ML classifiers address many legacy challenges through their abilities to capture the complex statistical profiles across diversified flow types —profiles that are difficult to extract manually as simple ‘if-else’ signatures. However, ML-based classifiers often require many time-series packets from each flow to construct a statistical profile for accurate classification — not cost-effective when handling millions of concurrent flows in a large network and can cause delays for subsequent network operations (NetOps) tasks.
In this post, I discuss FastFlow, our recent effort to enable ML classifiers to use just sufficient (minimal) numbers of packets for accurate flow classification. Full details can be found in this paper (or the preprint version), which has been accepted to ACM SIGMETRICS 2025.
Classifying network flows early or accurately? A practical tradeoff
Before diving into the design of FastFlow, let’s first look at some synthetic examples of network flows (Figure 1), which consist of time-series packets, to better understand the practical tradeoffs that ML classifiers need to take.
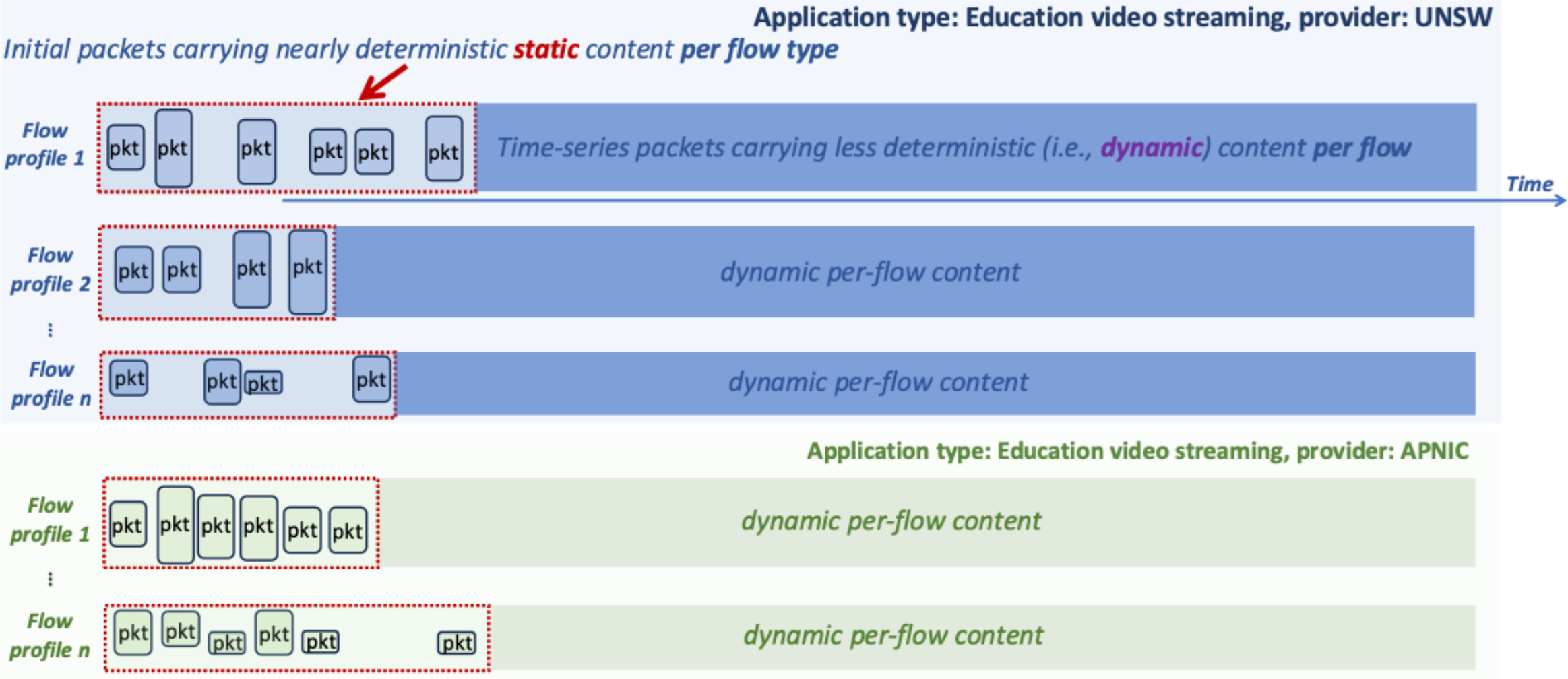
In Figure 1’s example, the five network flows belong to video streaming services offered by two providers, namely UNSW and APNIC. The first few packets (in the dashed boxes) of each flow are likely to carry static content, such as the administrative data and initial requests, and thus exhibit deterministic profiles suitable for accurate classification. The subsequent packets carry dynamic application content that is often unique to each flow (not each flow type) and may contain little or negative value for classification of flow types.
It seems intuitive that an ML classifier could achieve optimal performance — both early and accurately — if it could precisely rely on just the first few packets of a flow, especially since these packets often have relatively static and deterministic characteristics. However, identifying the minimum number of packets needed for reliable classification remains challenging.
In addition to the diversified flow profiles within and across flow types, practical factors in large networks, such as packet delays, drops, retransmissions, and the presence of unknown flow types, make it even more difficult for a pre-trained ML classifier to select the minimal number of packets for each flow. Therefore, prior work often compromises by either using a relatively large number of packets (for example, the first 50 packets or those arriving in the first five seconds) to maximize accuracy, or a small number (for example, the first five packets for all flows) to prioritize early classification at the cost of reduced accuracy.
Estimating the minimal number of packets per flow as a sequential decision-making problem
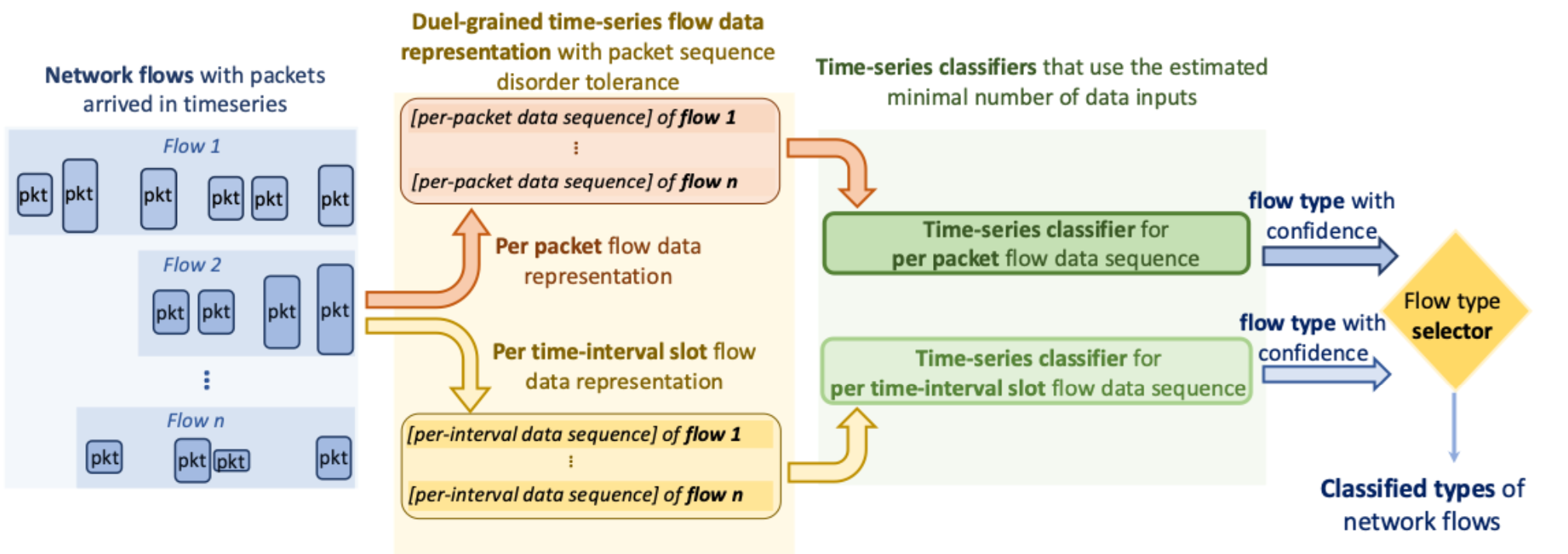
Instead of accepting the common tradeoff, we designed FastFlow (Figure 2), which classifies flow using a minimal yet sufficient number of packets. The number is estimated for each flow dynamically during runtime. Such dynamic decisions (determining the minimal number of packets per flow) on time-series data have been formulated by the ML community as a sequential decision-making problem and can be achieved using classifiers trained with reinforcement learning techniques.
To alleviate the impact of practical network factors such as packet drops, retransmissions and arrival delays, Fastflow processes each flow at both per-packet and per-slot (a group of packets) granularities and algorithmically selects the most confident flow type. Other choices we have made for FastFlow are not discussed in this post, but you can find them in this paper.
| Application | Provider | Macro F1 (%) | Accuracy (%) | Packet (#) | Time (s) |
| Video streaming | Microsoft | 98.70 | 99.29 | 3.25 + 2.32 | 0.05 + 0.44 |
| YouTube | 97.98 | 97.14 | 4.25 + 3.98 | 0.15 + 1.51 | |
| 89.77 | 86.32 | 8.32 + 4.68 | 0.19 + 0.36 | ||
| 91.01 | 91.56 | 5.78 + 5.43 | 0.11 + 0.40 | ||
| Software update | Fastly | 99.05 | 99.33 | 4.76 + 1.56 | 0.01 + 0.02 |
| Adobe | 98.09 | 98.24 | 4.75 + 2.44 | 0.02 + 0.09 | |
| Windows | 93.84 | 94.20 | 6.40 + 2.97 | 0.08 + 0.51 | |
| Apple | 95.20 | 93.12 | 6.61 + 4.16 | 0.06 + 0.46 | |
| Video conferencing | Ubuntu | 98.77 | 99.38 | 6.63 + 1.55 | 0.13 + 0.15 |
| Discord | 98.74 | 99.70 | 1.20 + 1.59 | 0.04 + 0.03 | |
| 99.22 | 99.38 | 2.99 + 2.30 | 0.39 + 2.45 | ||
| Google Meet | 98.41 | 96.87 | 4.00 + 4.09 | 0.13 + 0.05 | |
| MS Teams | 98.68 | 99.20 | 2.51 + 1.45 | 0.57 + 2.51 | |
| FaceTime | 97.77 | 95.65 | 3.65 + 3.60 | 0.38 + 1.80 | |
| Zoom | 97.41 | 98.62 | 4.12 + 4.45 | 0.99 + 3.62 | |
| Social media | TikTok | 83.51 | 86.36 | 6.31 + 3.52 | 0.13 + 0.18 |
| 85.17 | 88.97 | 11.16 + 5.57 | 0.29 + 1.39 | ||
| 82.35 | 82.12 | 9.90 + 5.23 | 0.06 + 0.28 | ||
| 81.16 | 89.09 | 10.52 + 5.26 | 0.27 + 1.62 | ||
| 84.61 | 88.85 | 9.09 + 4.62 | 0.67 + 4.10 | ||
| 84.06 | 88.14 | 3.85 + 4.11 | 0.02 + 0.10 | ||
| File storage | Apple iCloud | 96.44 | 95.00 | 11.89 + 4.62 | 0.05 + 0.10 |
| MS Sharepoint | 91.94 | 95.65 | 7.35 + 4.40 | 0.05 + 0.27 | |
| Dropbox | 96.42 | 97.29 | 8.12 + 2.63 | 0.08 + 0.12 | |
| Google Drive | 97.77 | 96.24 | 3.85 + 4.11 | 0.02 + 0.10 | |
| OneDrive | 88.37 | 84.73 | 9.63 + 3.95 | 0.03 + 0.07 |
Table 1 — FastFlow classification performance in our campus network deployment.
FastFlow has been prototyped in our campus network for a proof-of-concept deployment. The classifiers are trained to classify flows belonging to six application types from 26 popular providers, as shown in Table 1.
Flows that do not fall into these categories are expected to be labelled as the unknown type. The accuracy of FastFlow, measured as Macro F1 and Accuracy metrics, is satisfactory compared to state-of-the-art ML methods that use many (more than 50) packets per flow for accurate classification. FastFlow achieves such classification performance using only a very small number of packets (an average of 8.37 packets in 0.5 seconds), dynamically estimated at runtime for each flow, making it more cost-effective for deployment in large networks.
Minzhao Lyu is a lecturer at the University of New South Wales, Sydney, NSW, Australia, where he received the B.Eng. degree (First Class Hons.) and the Ph.D. degree in 2017 and 2022, respectively. His research primarily focuses on developing network measurement technologies for the security and performance of the Internet and telecommunications networks.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.