

Here is a square.

Wait, it’s not just a square.
There’s more of those.
They feel lonely. Can we help them?
Yes! See, they are now connected and can talk to each other. Much better!
Except… Oh no.
As you awoke one morning from uneasy dreams you found yourself transformed in your bed into a software engineer. A calamity that I find all too familiar.
Now it’s on us to figure out how that network should work.
With time and effort, you and I can come up with a protocol that will let bytes go through that cable. We can even make it decently quick and send pictures of exotic tropical fish to each other. It’s relatively easy — both sides of the cable are under our control, so we can agree on the speed of exchange, making sure that the sending computer does not overload the receiving one. All’s good, and the sun is shining 🕶️.
Except… Oh no.
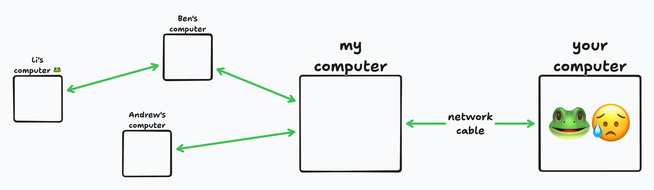
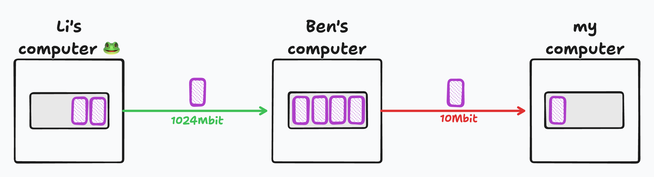
I have more than one cable plugged into my computer. You have an ongoing amphibian emergency that can only be helped by receiving frog pictures. I don’t have any, but someone in my network has them.
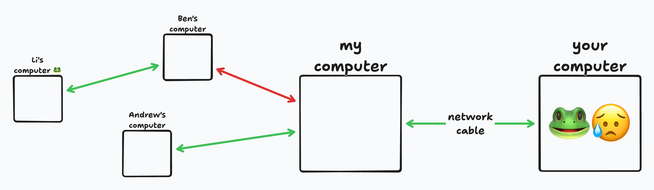
Computers are now interconnected into a large network, and all links are different. A family of magpies made a nest in Ben’s network cabinet, so every time the adult magpies bring food back, the link between me and Ben slows down.
Ben’s a smart guy. He knows that electrons are fickle, and the connection speed varies, so he adds a buffer to his computer. If his link to me is slow, he can still receive more from Li, filling the buffer, and transmit it further as fast as he can. This way, the bandwidth is utilized as efficiently as possible, and transient spikes of traffic or slowdowns are buffered.
Let’s zoom in.
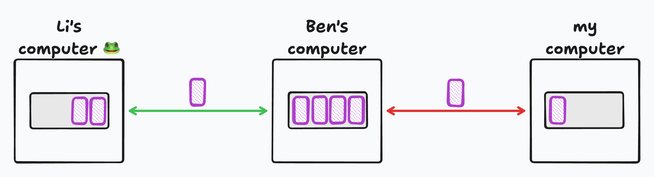
Look closely: Magpie parents are working hard, and the buffer is full. Packets trickle through, but they can only get into the buffer as fast as it is emptied on the other side. Ben’s computer asks Li’s to slow down.
Now imagine that there is more than one type of packet. Some of the packets belong to a voice call that is happening over the same link!
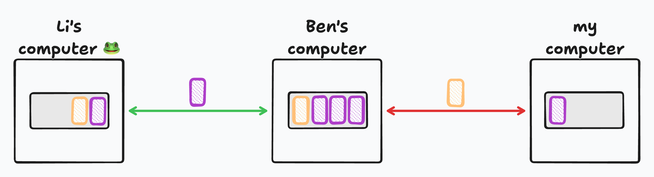
Voice packets need to get through quickly, but instead, they wait in the queue that doesn’t go anywhere. The buffer doesn’t help throughput; it’s not transient anymore and it just sits there. The buffer is actively harmful — it adds a delay! The entire link from Li to me is not only at maximum throughput, it’s also slow to react. The latency gets higher for no benefit.
This is called bufferbloat.
Bufferbloat is so common that we don’t even think about it. Of course, video calls drop out and glitch when you download something, duh! The Internet is working hard, it’s only natural that it’s a bit slow to react.
It doesn’t have to be this way.
Chances are, your connection is faster than 30Mbit up/down. You only need less than 10% of it for a perfectly good Zoom call. If bandwidth is split equally, it should be pretty hard for a home network to not be able to support a video call. Yet in practice, latency-sensitive traffic glitches all the time when the network is busy! People often think it’s the lack of bandwidth, but it’s usually the extra latency caused by bufferbloat.
How bad is bufferbloat, really?
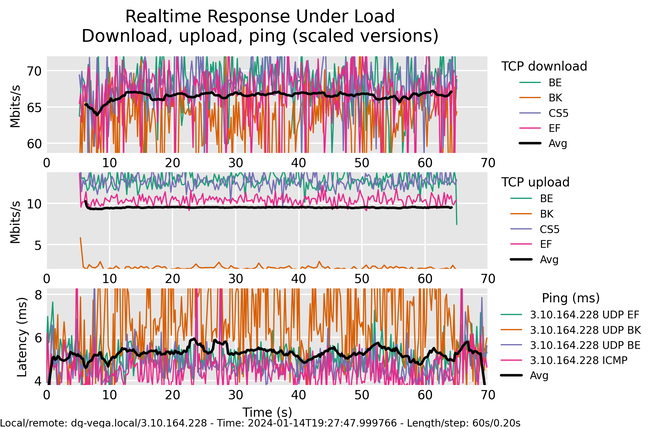
I tested my home connection with Flent.
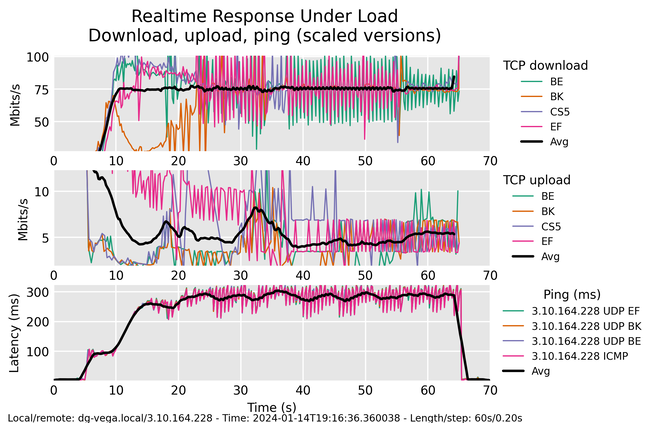
Here is what happens in Figure 1’s graph:
- Flent starts pinging the remote server (both via ICMP and UDP).
- Five seconds into the test, Flent starts uploading and downloading in parallel.
- Flent runs multiple TCP streams with different priorities in parallel. BE/BK/CS5/EF are different priorities.
- Both bandwidth and ping are charted five times a second.
Some conclusions:
- The download is pretty stable at 75Mbit per stream.
- Upload is all over the place, floating from 10Mbit to 5Mbit per stream.
- Ping raises from a few ms to almost 300ms — 0.3s just for one packet to go there and back again! That makes video calls unusable.
- Priorities are ignored.
I also tested pure, non-parallel bandwidth to the same server with iperf3. On my connection, iperf3 shows a total speed of 305Mbit down/48Mbit up. Compared with the numbers above, the total download matches Flent precisely, but the upload slows down two to four times because of the parallel download.
This is not ideal.
If you want to try this at home, I recommend bringing your own Flent test server to the closest AWS data centre instead of the ones provided by Flent. Also, install fping instead of using netperf’s native pinger.
What can I do about it?
Let’s look again at what happens when I’m trying to download something from Li:
The reason why packets bunch is that there is a bandwidth bottleneck on the way. If I could just sign up for a faster contract, the problem would go away, right? To an extent this is true — a faster connection makes it harder to saturate the network.
However, my provider still has a much faster network on their side, so the problem is still there, it’s just less likely to occur.
If only there was a way to adjust those queues dynamically, shrinking them if the network is saturated!
This is precisely what Active Queue Management (AQM) does.
I’m glossing over a lot of complexity here. For one, upload and download are very different. While my router can delay upload it doesn’t really control download traffic that comes from my provider — when a packet falls out of my provider’s fibre, it’s already here, and the router can’t push it back. It can only signal to the sender that they need to slow down. However, in practice, a good enough AQM implementation can throttle senders effectively using Explicit Congestion Notification (ECN) and packet drops, so it’s alright to assume that AQM can control senders.
CAKE is real
There are many AQM implementations, but the most modern, performant, non-fiddly one is CAKE (a very tortured backronym).
Better Internet is one configuration option away (and a beefy enough router to do AQM on your network speed).
I traded about 10% of bandwidth (263Mbit down/41Mbit up per iperf3) for:
- Constant average bandwidth on both upload and download.
- No impact of download on upload.
- Network load has no visible impact on latency.
- Effective traffic prioritization.
I believe I can be less conservative with the bandwidth and fiddle with CAKE settings more, but I am happy with this trade as it is. Here’s the entirety of VyOs config changes.
I really like VyOs on my home router. It’s good old Debian adapted for routing and comes with a handy configuration tool. Don’t be scared by the ‘official’ pricing; it’s free to use non-commercially on the rolling release, or if you’re happy to, build it yourself with just a few commands.
VyOs supports CAKE; it just isn’t documented yet. The ifb0 is described here.
interfaces {
input ifb0 {
}
pppoe pppoe0 {
...
redirect ifb0
}
}
qos {
interface ifb0 {
egress CAKE-WAN-IN
}
interface pppoe0 {
egress CAKE-WAN-OUT
}
policy {
cake CAKE-WAN-IN {
bandwidth 280mbit
flow-isolation {
nat
}
/* This should be above 98% of observed physical
round trip times. If your network is slower,
set it higher */
rtt 70
}
cake CAKE-WAN-OUT {
bandwidth 45mbit
flow-isolation {
nat
}
/* Same here */
rtt 70
}
}
}No more frog picture delays!

There’s more of ^this^ on Mastodon, RSS, or a very occasional newsletter. Or just let me know what you think at dan@dgroshev.com!
UPDATE: it was an incredible surprise to find a very positive email from Dave Täht, one of the people behind CAKE and bufferbloat.net, in my mailbox! He pointed out a problem in the configuration above:
rtt 30 is REALLY low for most networks. 100ms the default is designed to scale to about 280ms physical in the real world. In general the recommendation is 98% of your typical observed real world rtts. In most cases today I use 70ms.
…[It’d be better to] comment in your rtt setting, so that people in Africa do not copy/paste – at low rates that RTT setting will hurt, and at longer rtts common elsewhere, it hurt too.
…In Africa (about 80% the rtts > 300) we have been recommending 200ms for it, but it makes it really slow to react. See [this google doc] for some thoughts toward improving cake in Africa, on Starlink etc.
And on HN, where this post sparked a lively discussion:
…there is one thing that bothers me about his default config. He set CAKE rtt to 30ms which is OK, so long as 98% or so of the sites he wants to reach are within 30ms. Otherwise the default of 100ms is scaled to be able to manage bandwidth efficiently to sites around the world, and has been shown to work pretty well to real RTTs of 280ms. In general I have been recommending the rtt be set lower with the world consisting of CDNs, but not to 30ms.
I amended the post (and my config) accordingly.
Dave also pointed out that the rrul test I was using has its limitations. It would be interesting to look closer at TCP behaviours in the future.
Thank you Dave (watch Dave’s amusing talk on bufferbloat and networking, it’s great)!
Dan Groshev is making digital whiteboards and measuring latency. He made a play happen and helped teach kids science.
This post is adapted from the original on Dan’s blog.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Please post configuration commands used to get this configuration ( you could use “show configuration commands “