

This post looks at improvements PeeringDB has made to keep data quality high by improving automation, giving users better tools, and making it easier to find and export data in PeeringDB in 2022.
Data quality and search were ranked most important by respondents to our last three user surveys. To summarize what PeeringDB delivered for its users in 2022, let’s start with some numbers that help describe the scale of the work we’ve done.
Last year, we put out 10 major releases resolving over 100 issues. These included:
- Search and export improvements
- Continued improvements to support IX-F Member Export
- Better tools to support organizational admins
- 10 more HOWTO documents
We received contributions from several community members, including engineers at Amazon and Google.
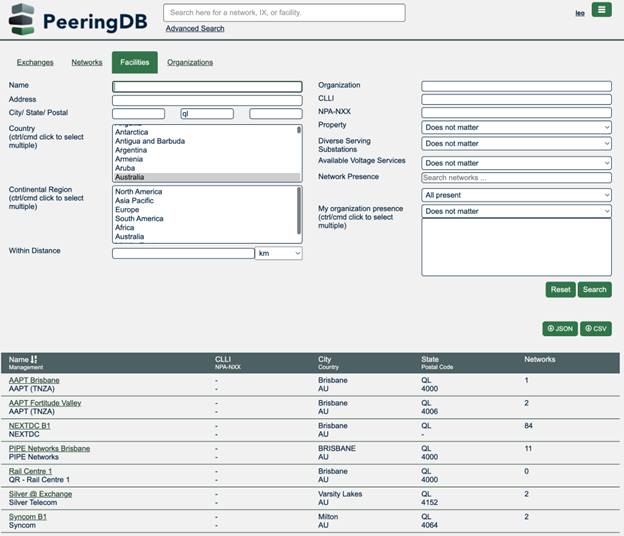
Search
We normalized the names of states and provinces to improve search results. This builds on the improvements to advanced search deployed in 2021, which allow users to drill down to get very specific information and export in structured formats.
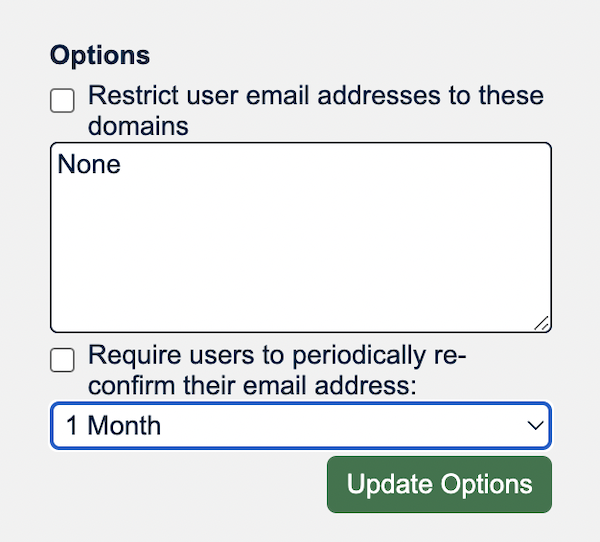
Managing your organization
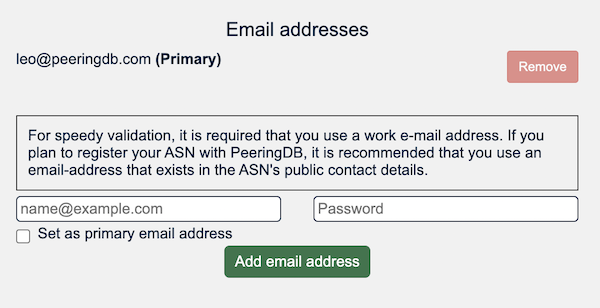
As shown in Figures 3 and 4, we improved the way organizational admins can manage their users. Features include the ability to require affiliated users to enable Multi-Factor Authentication (MFA) using authenticator apps or a hardware token or use a particular email domain.
Automation
We implemented a process to ensure that old networks are removed from PeeringDB when the Regional Internet Registries (RIRs) or National Internet Registries (NIRs) deregister their Autonomous System Numbers (ASNs). In combination with regular improvements to our support for the IX-F Member Export Schema, we are ensuring that PeeringDB’s data remains fresh.
Operations
We built on last year’s improvements to API Key support. We introduced query throttling with authenticated users getting more queries. We also worked with developers of third-party tools that query PeeringDB so that they make efficient queries.
We want users to have the best experience they can. So, we teamed up with members of the community at the NANOG 86 Hackathon to install our local cache, peeringdb-py, on a wide range of systems. Having tested that we have documented the installation process to make it easier for users to sync PeeringDB to their own infrastructure.
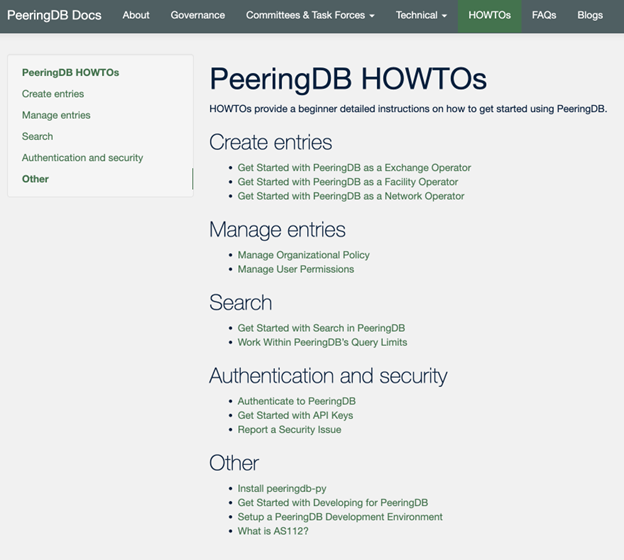
Documentation
Last year we introduced our HOWTO series. This year we expanded it and have had to organize it into five sections. If you find it’s missing an explanation of how to do what you want, then please let us know and we’ll work to add it.
User support
Noting that sometimes users need support, we’ve improved many support tools, so we can help users more quickly and effectively. On average, tickets are resolved in under eight hours, with automation managing 40% of this workload.
What’s coming next?
Two major improvements scheduled for early 2023 include further improvements to search and translation for anonymous web users. We’ll publish a more detailed product roadmap towards the end of January.
The improvements we make are only as good as the requests we get from you. We want to make sure that we understand what you need and why. If you have an idea for an improvement you can create an issue in GitHub but you can also reach out to anyone on the Product Committee.
We’d love to hear from you and listen to you describe what you need to achieve, so we can work out how to make PeeringDB meet your needs.
Leo Vegoda is developing PeeringDB’s product roadmap.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.