

Flat L2 networks are simple. Any host can send a packet to another host and the network will deliver it. If a host wants to discover the MAC address of a remote host, it sends an Address Resolution Protocol (ARP) request, and the network will handle it just like any other broadcast packet. The remote host will send an ARP reply and we’re good.
In practice, of course, this doesn’t scale and leads to all kinds of outages due to L2 loops and broadcast storms. This is why everyone hates large L2 networks.
Overlays that extend L2 over L3 attempt to improve scalability and reliability by:
- Getting rid of the L2 core.
- Reducing the amount of broadcast, unknown unicast, and multicast (BUM) flooding.
But if (1) is granted by every overlay, implementing (2) is tricky. Flood-and-learn overlays like VPLS or basic VXLAN don’t even try to deal with ARP.
ARP suppression
Overlays with more advanced control planes try to reduce BUM flooding by implementing ARP suppression. The most notable example here is Ethernet VPN (EVPN), and some proprietary technologies like Cisco OTV or VMware NSX.
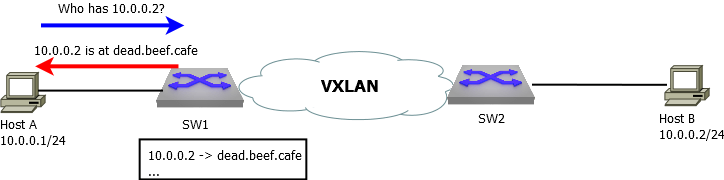
As shown in Figure 1, Host A sends an ARP request to discover the MAC address of Host B, but since SW1 already knows the host B MAC address (from previously intercepted ARP requests), SW1 responds to host A on behalf of host B, without forwarding the ARP request over VXLAN.
Perfect idea! What could ever go wrong?
As it turns out, plenty of things. Since flat L2 networks were so basic and simple, application developers became over-reliant on the fact the network will just deliver anything they put on the wire.
Many application clusters use ARP as keepalives between their nodes. And instead of using unicast ARP or GARP (which should not be suppressed), some send regular broadcast ARP requests. Of course, ARP suppression completely breaks this functionality.
ARP probes are broadcast ARP with the source IP 0.0.0.0. They are commonly used for duplicate IP detection. Proper EVPN implementation should not suppress ARP probes. Some earlier implementations did that, causing issues.
All modern switches forward transit packets with line-rate speeds. BUM packets are not necessarily forwarded line-rate, but the replication capacity is usually still very high. ARP suppression requires that all transit broadcast ARP packets be trapped to the CPU, which is also protected by control plane policy. A large volume of ARP traffic will cause some packets to be lost and queries left unanswered. Various bugs or TCAM misprogramming can sometimes cause all ARP packets to be dropped, or just dropped on a specific VLAN, and so on. Good luck troubleshooting that in a large network.
And then, of course, vendors.
On Cisco nexus switches, ARP suppression is disabled by default and can be enabled with ‘suppress-arp’ under a VXLAN network identifier (VNI). On Juniper QFX, ARP suppression is enabled by default and can be disabled with a ‘no-arp-suppression’ under VLANs. On Arista, ARP suppression is enabled by default only on VLANs with a Switch Virtual Interface (SVI) configured. But you can disable it for some specific subnets (such as running clusters that use ARP as keepalives):
router l2-vpn arp proxy prefix-list NO_SUPPRESS ! ip prefix-list NO_SUPPRESS seq 10 deny 10.0.0.0/24
I don’t even want to get started on Microsoft NLB with its ARP bindings to multicast MAC (explicitly prohibited by RFC 1812). Microsoft is even worse than Juniper when it comes to standards.
Adding some routing
Consider a simple network with an L3 switch separating two subnets.
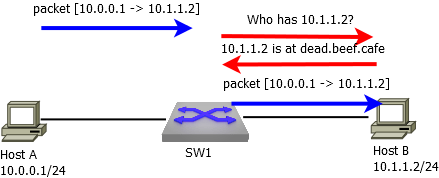
Assuming Host A already has an ARP entry for the SW1 IP, it sends a packet to Host B, but SW1 doesn’t know Host B’s MAC address. So SW1 must do the following:
- Trap the transit IP packet to the CPU.
- Hold the packet in the queue, and create an INCOMPLETE ARP entry while sending the ARP query for the Host B MAC.
- Once SW1 receives the ARP reply, update the ARP entry as REACHABLE and forward the queued packet to Host B.
At least, this is how it works on a Linux-based network OS. The exact number of packets that can be queued depends on implementation, but it’s around 256 256-byte packets per unresolved address. If the ARP can’t be resolved after three attempts (state: FAILED), the switch will keep sending queries forever, while discarding extra transit packets and sending ICMP destination unreachables to Host A.
Other network OS might behave slightly differently (for example, Cisco IOS sends ARP requests every two seconds and drops transit packets destined to unresolved ARP requests), but the overall idea will be similar. Also, since SW1 is an L3 switch with SVI, it will also learn Host B’s MAC upon hearing ARP replies.
ARP in L3 EVPN
Now, let’s see how this works when L2 is replaced with VXLAN-EVPN.
L3 EVPN comes in two flavours — asymmetric and symmetric Integrated Routing and Bridging (IRB).
Asymmetric IRB refers to L3 EVPN design in which all VXLAN Tunnel End Point (VTEPs) have an SVI for all L3 VNI configured in the network, and if a packet must be routed between subnets, the ingress VTEP does routing, and the egress VTEP only does bridging.
When a VTEP needs to learn the ARP entry for a remote host reachable over VXLAN, it sends an ARP request, the host responds with an ARP reply, which might reach the VTEP or not — it doesn’t matter, because at this point, we want the remote VTEP to generate MAC-IP routes and advertise them over BGP. Both ARP (L3) and MAC learning (L2) will be populated from the BGP-EVPN control plane. Whether we receive the ARP reply or not is irrelevant. This is important because in multihomed setups, an ARP reply can land on another switch.
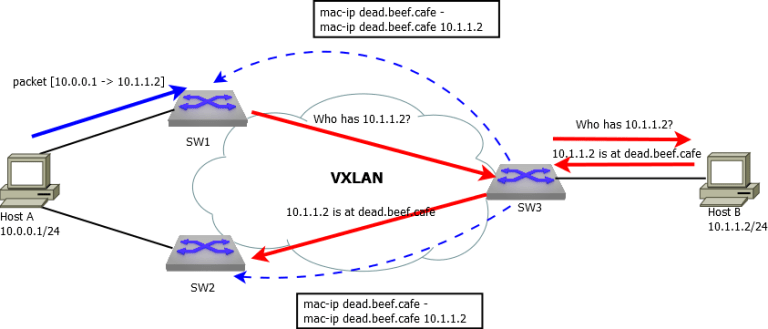
Figure 3 illustrates that even if the ARP reply lands on SW2, SW1 still learns the ARP entry for Host B from BGP-EVPN. It also learns the MAC address of Host B from EVPN.
Now, what can go wrong here?
Consider a TCP-based application that can be silent for longer than five minutes while keeping the TCP session alive. SW3 would age out the MAC address after five minutes and withdraw the MAC-IP route. In EVPN, there are no separate route types for MAC and ARP, so SW3 would withdraw both routes. This will force SW1/SW2 to unlearn the ARP.
If, the next time Host A wants to initiate a conversation, and the whole process of rediscovering the Host B MAC and advertising it via BGP will take longer than on second, it will cause SW1/SW2 to send ICMP unreachables back to Host A, which will reset the TCP session. Depending on implementation, this can fail even if everything takes less than one second. Even if the application doesn’t go silent for five minutes but return traffic is asymmetric and doesn’t come over EVPN, the same problem can occur.
Blacklisted MACs in asymmetric IRB designs can now cause duplicate traffic and TCP resets in the application.
Symmetric IRB is a more advanced EVPN design, where the ingress VTEP does routing to a transit VNI, and the egress VTEP does routing to the destination VNI. It allows for better scalability, and eliminates the problem described above.
Well, almost. Gaps in application traffic longer than five minutes will trigger MAC timeouts, and subsequent withdrawals of MAC-IP routes, which will also cause churn of EVPN host routes.
Conclusion
Reducing ARP timeout from the default four hours to less than five minutes seems to solve all EVPN IRB ARP problems. They can be difficult to detect and isolate, so in my opinion, the MAC age timer should be best practice in all EVPN deployments. On the other hand, I believe ARP suppression was a bad idea in first place. If an L2 network doesn’t scale, design a proper L3 network. But if people want to step on rakes, why discourage them?
Dmytro Shypovalov works as a Network Architect at Eircom and has a background as a TAC engineer at Arista and Cisco. He is primarily interested in routing protocols.
This post was originally published on Routing Craft.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Thank you for this great article!