

The following post is based on the work of John Kristoff, Randy Bush, Chris Kanich, George Michaelson, Amreesh Phokeer, Thomas C. Schmidt, and Matthias Wählisch in the ACM IMC 2020 paper: On Measuring RPKI Relying Parties.
The Resource Public Key Infrastructure (RPKI) is a specialized PKI designed and deployed to improve the security of the Internet BGP routing system. Some of the ‘resources’ that make up the RPKI include IP address prefixes and Autonomous System numbers (ASNs).
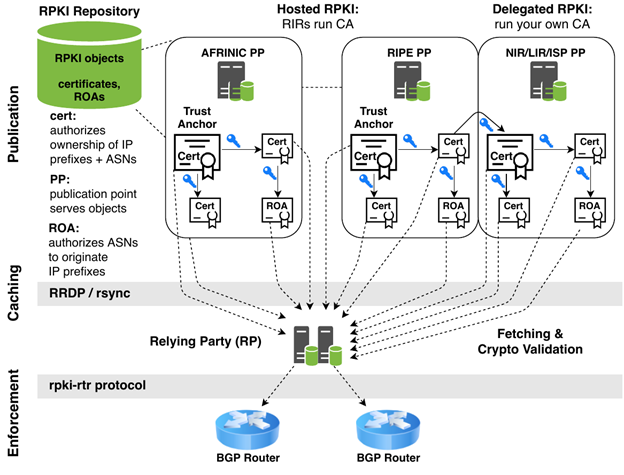
The infrastructure itself comprises three major components: a publication system, an intermediate caching subsystem, and an enforcement layer integrated with a network’s BGP routing policy.
For network operators, the publication system is important because that is where they publish route object authorizations mapping origin ASNs to IP address prefixes. They care about the caching system because to perform Route Origin Validation (ROV), relaying party systems fetch the published data to apply to their own routing policy. And of course, the enforcement layer is where they make decisions on their IP routers about what BGP announcements to accept, reject, or adjust based on RPKI data.
How the caching layer performs is of utmost importance to the network operator so that they are working with current and complete data. See Figure 1 for a depiction of how these three components are deployed and interact.
Several studies have measured the growth of the RPKI by examining the population of signed resources such as Route Origin Authorization (ROA) objects published (see here, here, and here), or the extent of RPKI enforcement by conducting controlled routing experiments (see here, here, and here). In other words, measurement studies have focused on data in the publication system and the use of the RPKI for ROV, but until recently, little was known about the current state of that intermediate caching layer.
The most important goal for all relying party (RP) systems at the caching layer is to maintain a complete and timely set of published object data. An incomplete or stale view of publication data can lead to erroneous validation or invalidation of IP prefixes and lead to widespread loss of network reachability.
Our recent study helps fill a gap by measuring the relaying party (RP) systems in the caching layer, as seen from the perspective of publication point (PP) servers. We shed light on RP behaviour in the wild and uncover a discrepancy between the expectations of protocol designers and the implementation decisions of RP software developers. This post summarizes the results of that work.
Measurement framework
To measure RP behaviour, we leveraged the requirement for RPs to fetch data from all the publication points.
The publication system is a multi-root tree structure. Each of the five Regional Internet Registries (RIRs) serve as the five-headed root, each anchoring the portion of IP address space they are responsible for.
Resource holders, such as ISPs, most commonly use an RIR’s ‘hosted’ RPKI facilities to sign and publish their object data, but they could choose a ‘delegated’ model. Much like the DNS, where a parent zone refers to delegated child name servers for portions of the name space, so too the RIR trust anchors can delegate portions of their resources to child publication points if a resource holder so chooses. We operate our own CA and PP server for our IP resources to observe synchronization behaviour from RPs in the wild.
RPKI objects are stored and made available as files. The RPKI first specified rsync as a required mechanism for RPs to retrieve data from PPs. All RPs must implement rsync, but the newer, optional RPKI Repository Delta Protocol (RRDP) designed to run atop HTTPS is increasingly popular and preferred by most implementations when available. Our measurement framework supports both transport mechanisms and our access logging to either service interface provides the raw measurement data from which we conducted our study.
In addition to our own child CA/PP setup, we also obtained access logs for the AFRINIC and APNIC trust anchor PPs to complement our data and increase the visibility of our measurements.
Trends in RP behaviour
We first show the longitudinal growth trend of RPs on the Internet. In Figures 2 and 3 we show the longitudinal growth trends of RPs on the Internet, first where rsync is used as the access method and then when RRDP is in use.
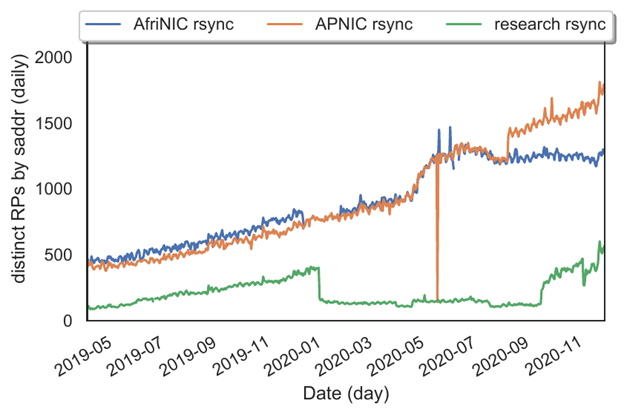
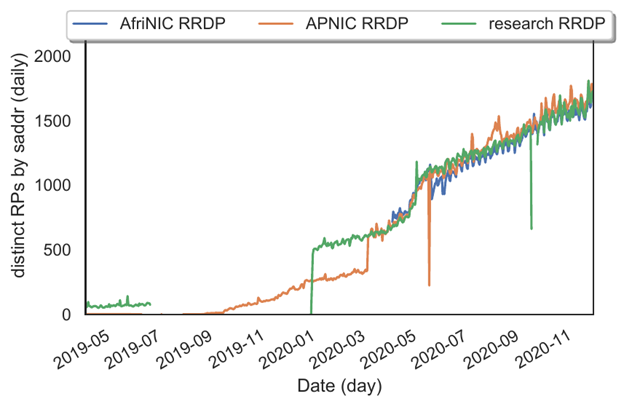
Some RPs may use both access methods for different operations over time. We consider each unique source IP address in our access logs in a 24-hour period to be a distinct RP. While there are some transient and short-lived RPs in operation, over the long run, most RPs maintain stable source IP addresses.
Dramatic changes may represent temporary losses in access data or major operational changes.
One noticeable operation at our research PP can be seen at the end of 2019. The sudden decrease in rsync access coupled with a rise in RRDP access corresponds to the activation of the RRDP service interface on our system. This clearly shows the preference many RPs have for RRDP.
The increase in 2020 is related to access limit restrictions on the RRDP service we imposed for our research experiments. The decline in rsync access at the AFRINIC PP coincides with the publication of the HTTPS URI in their trust anchor locator (TAL) file. Some implementations have preferred RRDP and consequently reduced their usage of rsync with the introduction of this change. Child PPs such as our research PP tend to see substantially few rsync accesses when RRDP is available.
RP implementations and the transport protocols are required to not only fetch all published objects, but to do so regularly to ensure networks have an up-to-date view. While there are no strict requirements for the synchronization intervals RP must use, in practice intervals are on the order of a few minutes, which some rsync-only implementations default to 60 minutes via a cron job. We consider RPs to contain reasonably fresh data if they sync at least every 60 minutes to all PPs.
Some large networks, such as Facebook, deploy many RPs across their infrastructure, but we were interested in the typical number of RPs per network. When we grouped the number of RPs by ASN, we found that most networks had two RPs. We also found some large networks, not just cloud providers, that had deployments of dozens of RPs throughout their infrastructure.
Approximately 70% of networks with RPs have one or two RPs. A few outlier cases have many more, with the most extreme case being an infrastructure provider that used a transient container-based deployment model.
Another view of RPKI deployment is through the lens of RP implementation popularity. Most RPs use RRDP, but because RRDP runs over HTTP and each implementation includes its own unique User-Agent string, we can use this token for another measurement.
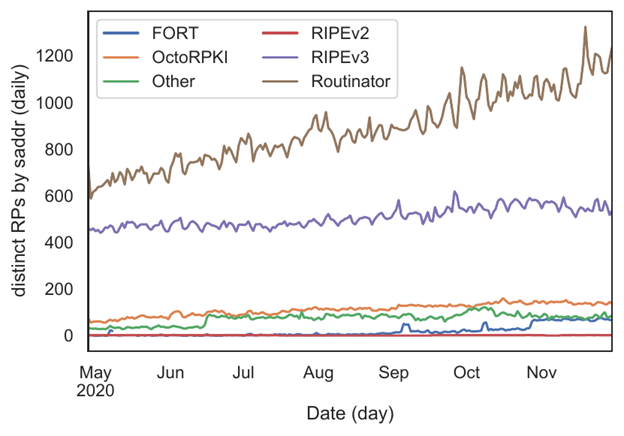
Figure 4 shows Routinator and the RIPE NCC Validator-3 with the largest number of deployed RPs. While we cannot generally measure the RP software implementation directly when rsync is used, the OpenBSD rpki-client by default has a tell-tale signature that we can use to estimate the minimum number of that software in use, because (as of this writing) it does not support RRDP. Our data suggests the rpki-client minimum is roughly on par with OctoRPKI and FORT deployment.
Read: RIPE’s RPKI Validator is being phased out, what are the other options?
A filtering experiment
Perhaps our most impactful result was the discovery that most RP implementations do not automatically fall back to rsync once they have successfully started using RRDP, even if RRDP becomes unavailable for an extended period.
We discovered this behaviour by altering the operation of one child PP we were running. This PP began by servicing RPs over either rsync or RRDP as they preferred. Once we disabled access to the RRDP service interface, we noticed those RPs using RRDP never returned until they were either restarted or the RRDP interface was made available again.
This led to lively exchanges on the IETF SIDROPS Working Group mailing list, and later on the NANOG mailing list.
One implementer, Routinator maintainer NLnet Labs, has indicated its intention to implement fallback to rsync.
Providing the missing pieces to the puzzle
Measuring ROAs and ROV enforcement helps us understand who is using the RPKI, but without considering the caching layer, we would be left with a lot of questions of how networks are using the RPKI. Measuring the relying parties helps provide the missing piece to the puzzle.
We can better understand not only how a network is participating in the RPKI, but we can also deduce several potential problems by conducting filtering experiments, as shown above. Uncovering these insights in controlled experiments is far preferable to discovering them in real-time on production networks.
Furthermore, these measurement activities also help us to better focus future activities when we gauge the community’s reactions to them. What questions have we left unanswered that you would like to see addressed?
John Kristoff is a PhD candidate in Computer Science at the University of Illinois Chicago. He is also a network architect and adjunct faculty at DePaul University, a research fellow at ICANN, a NANOG program committee member, and operates DataPlane.org.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.