

Those that have used the traceroute tool can agree its slowness can be frustrating at the best of times, let alone if you need to explore routes to a large number of targets, for example, to produce a snapshot of the routing topology as seen from a given vantage point.
Naively implementing such a scan as a python script that sequentially invokes your standard traceroute on every target will take a very long time. However, two notable advances have been developed to address this problem.
Doubletree
The first is the Doubletree algorithm, which offers ways to reduce redundant probes by avoiding rediscovering overlapping sections of routes to multiple targets.
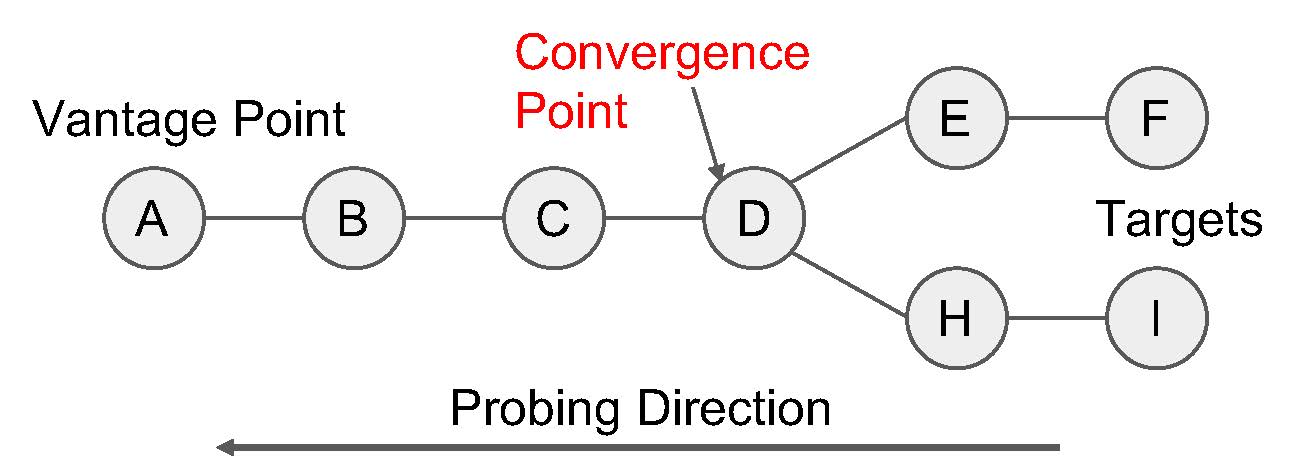
In particular, it exploits the observation that the routes emanating from the vantage point to all the targets tend to form a tree as illustrated in Figure 1. Thus, by probing the routes backward from the targets to the vantage point, a given route exploration can stop once it encounters a hop previously discovered through another target. The remaining part of the route from this ‘convergence point’ to the ‘vantage point’ will likely be common and will be explored by whichever target was first to reach the convergence point.
Yarrp
The second is a tool called Yarrp, which has made probing stateless. Instead of storing the probes and matching them with responses, Yarrp encodes the TTL and timestamp of the probe (the only information needed to produce a data point about the responding hop) within the probe headers. Since the ICMP responses quote probe headers in their payload, both pieces of information can be extracted from the response itself — no matching with the corresponding probe required. With this, Yarrp can simply blast probes to all targets at all TTLs (within the range of one through 32) as fast as it can and forget about these probes. It then simply logs whatever responses come back for offline reconstruction of the routes.
In fact, Yarrp even avoids loading the target list into memory. Since it is designed to traceroute one IP address from every /24 block, it simply generates a random sequence of all combinations of /24 prefixes and 8-bit TTLs on the fly using a 32-bit RC5 block cipher.
Avoid redundancy and increase speed with FlashRoute
The above innovations pursue two distinct directions in improving efficiency.
Doubletree reduces redundant probes but does not improve probing speed as it retains the need to store probes, match them with responses, and expire lingering probes sent to non-responsive hops. In particular, Scamper, a prominent tool from CAIDA that incorporates Doubletree, places a limit of 10,000 probes per second for the probing speed.
Yarrp, on the other hand, increases parallelism dramatically but largely gives up the ability to eliminate redundant probes through smart probing strategies, that is, Doubletree.
Our new tool, FlashRoute, developed by my PhD student, Yuchen Huang, at Case Western Reserve University, strives to get the best of both worlds — eliminate redundant probes and preserve Yarrp’s probing speed.
FlashRoute’s key idea is the realization that not all state is evil: as long as the scanning host can fit the required footprint into its memory, making the tool completely stateless is not a worthwhile goal. Thus, FlashRoute retains Yarrp’s innovation in encoding all needed measurement context in probe headers to enable high probing speed but keeps a limited amount of state to facilitate smart probing strategies and, in particular, preserve Doubletree’s redundant probe elimination.
Our current implementation focuses on tracerouting one IP address from every /24 prefix. This is a typical topology measurement, pursued by ongoing CAIDA measurements using Scamper and also implemented by Yarrp. We currently are extending FlashRoute to allow:
- Scanning of finer-grained prefixes, and
- Scanning of an arbitrary set of full addresses rather than one representative per prefix.
How it works
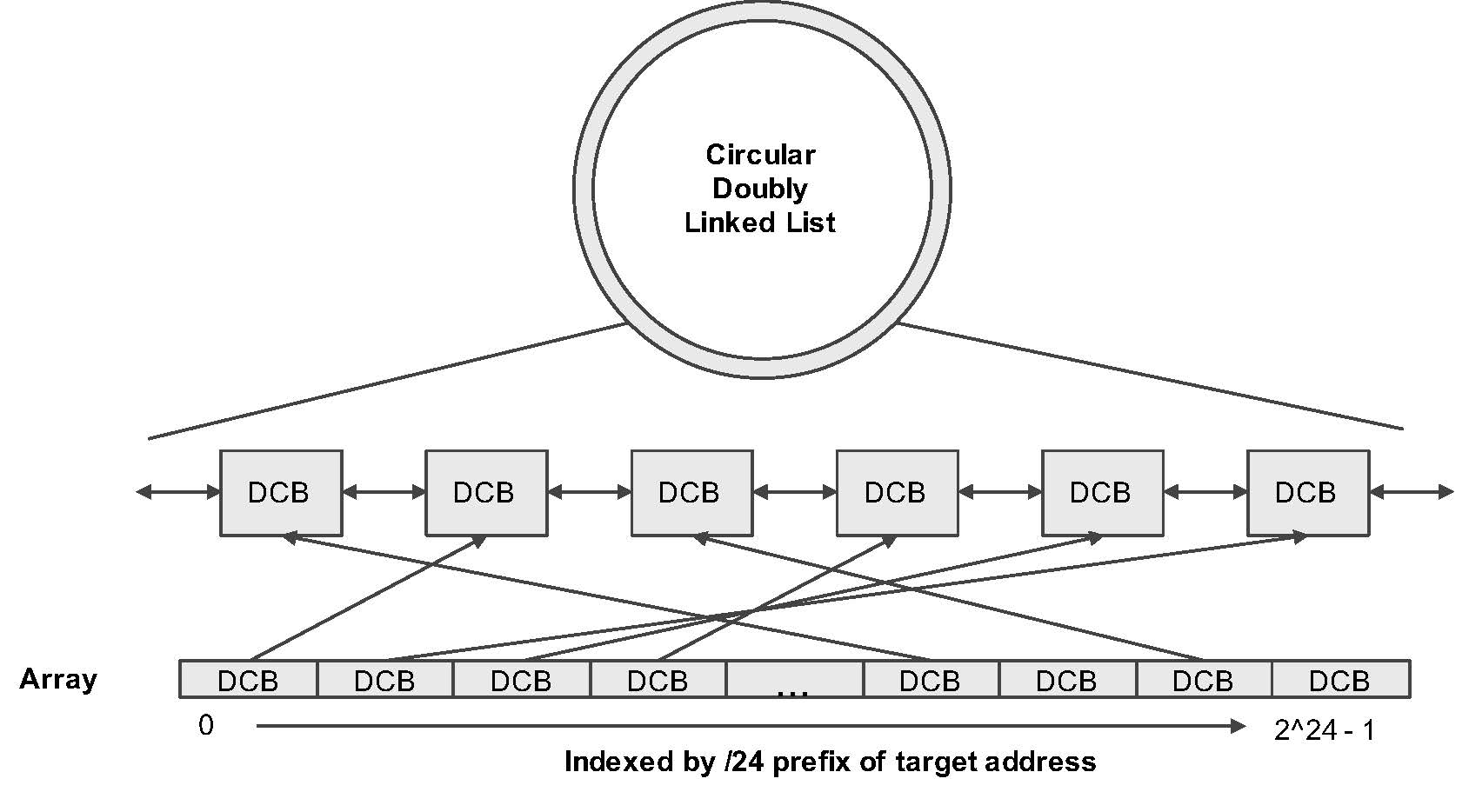
FlashRoute uses a small structure for each target, Destination Control Block (DCB), to track the progress of route exploration to this target. A DCB records the TTL of the next hop to be probed in the backward direction towards the vantage point and in the forward direction towards the target, starting from some initial TTL called the ‘split point’. A probing thread cycles through a random permutation of the DCBs and issues one probe in each direction.
Given the large number of targets (~16M of /24 prefixes), a cycle duration provides enough time for responses to arrive before another probe for the same target will go out, even with a high probing rate. Only towards the end of the scan, when most of the targets complete their probing and drop out from the loops, does FlashRoute introduce some waiting to ensure that each cycle takes at least one second. Asynchronously, another thread receives responses and updates the corresponding DCBs to reflect the state of the scan.
To allow the response-receiving thread to quickly access the DCB to update, the DCBs are kept in an array indexed by the targets’ /24 prefix as shown in Figure 2. To allow the probing thread to quickly go through a random premutation of the DCBs in each cycle, we superimpose a circular doubly linked list on this array by adding successor and predecessor links to each DCB.
FlashRoute: 3x faster than Yarrp
By running full scans from our campus using FlashRoute, Yarrp, and Scamper, we found that FlashRoute revealed virtually the same number of router interfaces, 0.8% less than Scamper and 1.4% more than Yarrp, but used drastically fewer probes than Yarrp, by 73% (and, incidentally, also 26% fewer than Scamper). Consequently, FlashRoute completed the scan over three times faster than Yarrp (17 mins vs. 1 hr) with both tools probing at 100K pps.
We also compared the maximum probing rate FlashRoute and Yarrp could sustain by running partial scans with each tool at unthrottled speed. FlashRoute showed 10% lower probing rate (215K vs. 239K pps on a 10-year-old server). However, this decrease is more than compensated by many fewer probes FlashRoute requires: considering the probes needed to complete the scan, the observed probing rates translate into the full scan time of 7 mins 34 secs for FlashRoute vs. 24 mins 47 secs for Yarrp.
FlashRoute is available for download. For more information on our study refer to our IMC AMC 2020 paper, FlashRoute: Efficient Traceroute on a Massive Scale. The work on FlashRoute has been supported by NSF through grant CNS-1647145.
Contributors: Yuchen Huang and Rami Al-Dalky
Michael Rabinovich is a professor in the Computer and Data Sciences Department at Case Western Reserve University.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.