

The Domain Name System (DNS) is critical to all that is good and bad on the Internet. In most cases, the purpose for malicious actors using the DNS as part of their cybercrime is relatively clear: they need to lure users, deliver malware, or otherwise control devices on the network.
At Infoblox, we’ve spent a lot of time over the last few years studying a form of cyberattack, ostensibly a denial of service, for which the motivation is much less clear. These attacks, commonly referred to as Random Subdomain attacks or Slow Drip attacks, have morphed significantly over time, remain unabated, and are somewhat perplexing.
Attacks are not what they seem
First observed in 2009, Slow Drip attacks hit the world stage in a dramatic fashion in early-2014, wreaking havoc on the important middle-level infrastructure of the DNS, particularly on ISPs. Japanese service provider QTNet described the disruption not just of caching resolvers, but of load balancers too.
The structure of these attacks is relatively simple. A large number of queries for random subdomains of an established domain — for example, airbnb.com — are made through intermediate resolvers, propagating to the authoritative name servers, and overwhelming their resources. This attack flow is shown in Figure 1.
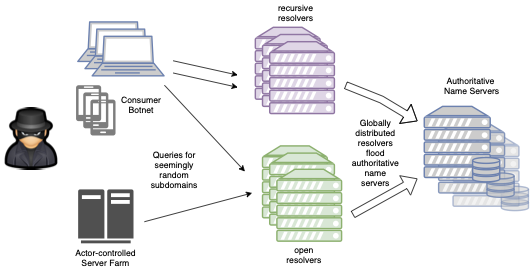
While these attacks target the authoritative name servers, the real damage from this version of this attack (which was prominent through mid-2018) was inflicted upon intermediate resolvers and load balancers. The attack itself has no direct impact on the associated domain, airbnb.com, in our example here.
Surprisingly, although the attacks were observed nearly daily for four years, no specific malware was associated with these attacks. While Mirai contains a variant of the attack, that implementation bears little resemblance to the large-scale attacks typically associated with the name.
The disruptive Slow Drip attacks were high volume and broadly associated with Chinese targets. A former colleague and I previously published signatures that tied those attacks to a single codebase. But in late May 2018, that actor went quiet and we’ve not observed any of those attacks since. In contrast, a much more diverse set of similar attacks with a much lower volume has taken their place.
Categorizing attacks shows they are anything but random
As threat researchers, we’re driven to understand the nature of the attackers, their characteristics and motivation. While we still observe this form of traffic daily, the lower volume and lack of a consistent signature have made them more difficult to detect.
I’ve spoken with top-level domain (TLD) operators who told me they first observed this variation in 2017. We use a combination of statistics, comparing traffic on a given day with previous days, to locate the activity with a high degree of confidence. The lack of volume at various points in the DNS make it particularly unclear whether this is a lacklustre attack by actors without resources or if it has some other purpose.
In an effort to make sense of it, we studied detections from June 2018 to January 2019. Our goal was to characterize the attacks, perhaps determining how many different attack generators might be active, as well as a motivation for the attacks, if they are to be considered attacks at all.
Using unsupervised machine learning techniques, with a big dose of passive DNS analysis experience, we found that this newer activity differs significantly from the original. Moreover, there are a number of very strong features that allowed us to separate the activity into groups.
While early versions of the attack used only A record (IPv4) queries, some new attacks leveraged other query types. In Figure 2 we see a distribution of such attacks observed during late-2018. This behavior is very distinctive from other attacks.

Most notable, perhaps, is that current variants of the Random Subdomain attack are anything but random. They are often built from a dictionary and contain very specific sequences in building hostnames. Where the large attacks that occured in 2014-2018 contained queries for hosts such as nbpqefghvjklm.111f.com, more recent attacks often contain terms such as those shown in Figure 3.

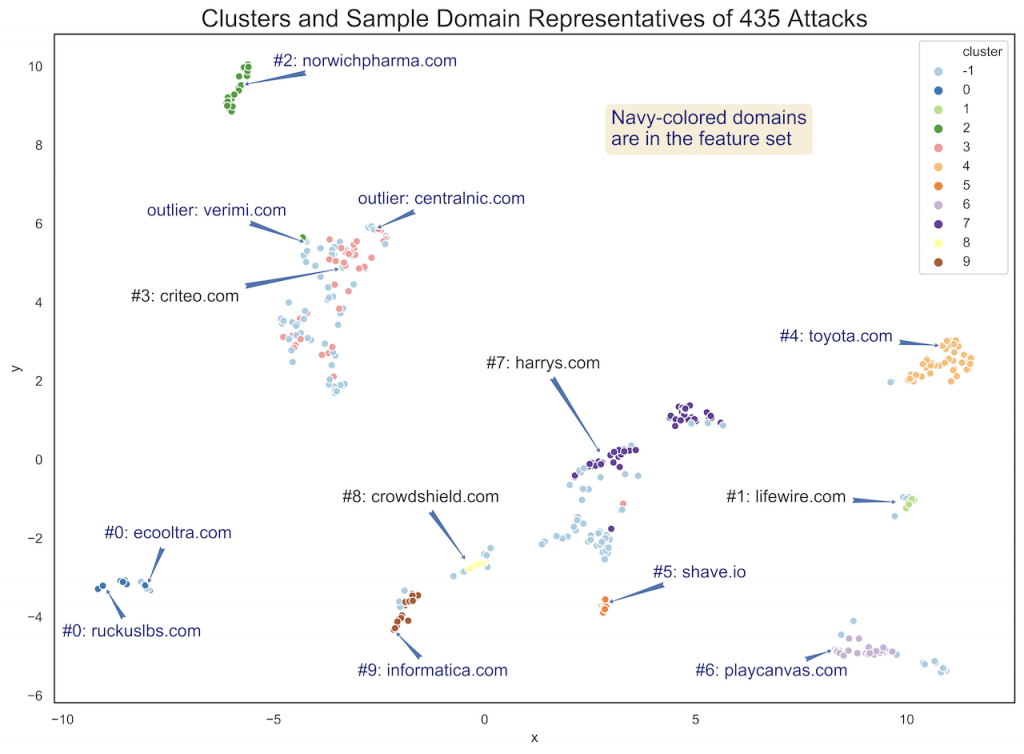
Figure 4 shows conceptually the clustering of the attacks by the victim second-level-domain. While this version shows ten distinct groupings, we suspect there are likely fewer — perhaps four — different hostname generators.
There is still no known malware that creates these attacks. Their tempo is consistent, with many ‘attacked’ domains a day, and the domains in question range from the well-known (amazon.com) to the obscure (91y.com).
In 2019, we saw the use of a large number of known malicious domains as well. The queries are inconsistent with scanning campaigns, especially when you consider this new trend. And, as occasionally discussed in DNS forums, their volume is too low to be anything but noise. So what is the motivation? Ideas welcome in the comment section below.
A pre-print of the research paper to appear in ACM’s Digital Threats Research and Practice journal is available on Arxiv.
Renée Burton is a Senior Staff Threat Researcher at Infoblox.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.