

To achieve semantic security, an attacker must have only a negligible advantage in guessing any plaintext value, but the cryptographic algorithms in TLS only meet the lesser goal of indistinguishability of the plaintext from messages of the same size.
For example, a cipher meeting the lesser goal of indistinguishability fails at semantic security when applied to the message space consisting of the strings YES and NO. While a primary goal for TLS is confidentiality, our work presented at ACM CODASPY ’19 and ANRW ’19 explores places where this goal fails due to the gap between theory and practice.
Specifically, we show that it is possible to infer HTTP protocol semantics from observations of HTTPS connections to provide “Limitless HTTP in an HTTPS World”, to adapt Michael Scott’s unwittingly incongruous slogan from The Office, “Limitless Paper in a Paperless World”.
Collecting ground truth
The basic hypothesis was if a machine learning classifier was given a dataset linking the encrypted observables present in a TLS session with the underlying HTTP features, it could then be trained to identify the HTTP features without needing to perform decryption.
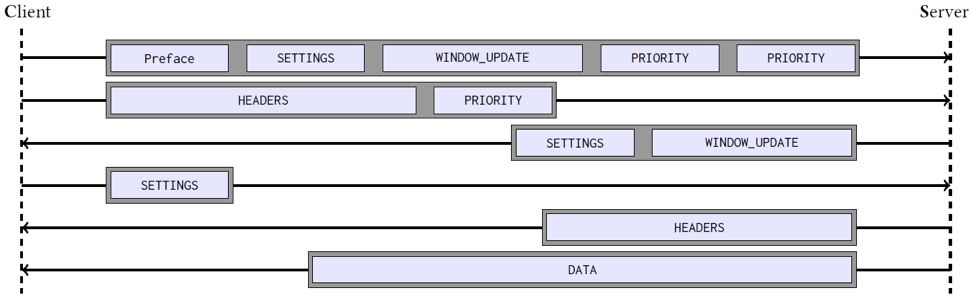
Figure 1 — Firefox 58.0 HTTP/2 connection to google.com inside of a TLS encrypted tunnel. The grey boxes indicate a single TLS application_data record, and the light blue boxes indicate HTTP/2 frames.
This dataset was generated by running the latest versions of Chrome, Firefox, and Tor browsers against popular websites and collecting the relevant key material through either memory snapshots or the SSLKEYLOGFILE environment variable. Data from a malware analysis sandbox was also collected, which offered more diversity in the observed clients and extracted the key material via memory. With the packet captures and key material in place, we created a custom decryption program that produces JSON data correlating the underlying HTTP requests, responses, and data with the observable TLS record protocol. This created a mapping similar to the above figure where HTTP/2 frames map to TLS application data records.
Generalizing to sessions without ground truth
The end goal of understanding HTTP semantics with only HTTPS observations was broken down into several sub-problems, each solved with supervised machine learning. Each sub-problem had a specific label and feature set. Multi-class classification algorithms modelled problems with a small, well-defined label set such as the method field or Content-Type header, and binary-class classification algorithms modelled problems that had a potentially unbounded label set such as the Referrer or Cookie header. In the case of the binary-class problems, the algorithm was simply trying to learn if the header field was present in the request or response.
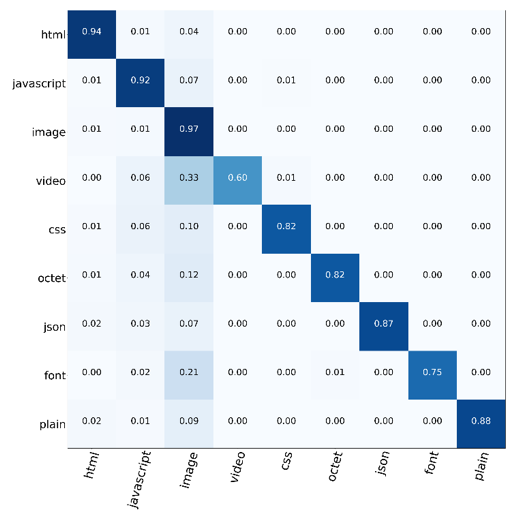
Figure 2 — Confusion matrices for the HTTP/1.1 response Content-Type header field. The y-axis is the true label and x-axis is the predicted label.
The feature sets of most problems considered locality within the TLS session by extracting features like the preceding and following TLS record types/lengths, packet sizes, and TCP flags. We used cross-validation to analyze the performance by either splitting the data by hostnames or by the date collected.
In both cases, the results reinforced our hypothesis. The above figure shows the confusion matrix for the multi-class Content-Type problem. In this problem, the classifier is given a TLS record identified as containing a HTTP response by another classifier and asked to determine the Content-Type as specified by the encrypted response. Despite the training data being heavily skewed towards the image class, the classifier was able to perform reasonably well across all labels.
Implications
First, it might be useful to add some caveats: these techniques will not be able to identify random values in the HTTP data and they do rely on a relatively good approximation of the client to reach higher levels of accuracy. But the results are intriguing, and as with all traffic analysis research, this work has implications for both attackers and defenders. With DoH, TLS 1.3, and encrypted SNI, techniques as described in this blog post may be refined to aid website fingerprint with the goal of blocking censored content.
On the other hand, these techniques could offer an alternative to TLS decrypting middleboxes that better respects the privacy of end users while still delivering valuable security features. As an example, limitless traffic analysis could be used to identify the sizes of files uploaded to an unmanaged server (say, Gmail). This information could then be correlated with an internal repository of sensitive files each user has access to. The benign network monitor could then alert the user to any potential data loss without the need to perform decryption on all private communication.
To learn more, watch our presentation at the Applied Networking Research Workshop 2019 or read a pre-print of our research paper here.
Contributors: David McGrew, Andrew Chi and Scott Dunlop.
Blake Anderson currently works as a Senior Technical Leader in Cisco’s Advanced Security Research team.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.