

The following is the first post of a three-part series on measuring satellite bufferbloat as well as recommendations on how to solve it.
ISPs that use satellite links for international IP connectivity often block User Datagram Protocol (UDP) traffic because it is deemed ‘unfriendly’ in the presence of Transmission Control Protocol (TCP) on the link and considered too unimportant a protocol to be mission-critical.
Historically, it is certainly true that UDP used to account for only a small percentage of bytes and flows on most links. However, more recent research shows that this has been changing rapidly with the advent of streaming and peer-to-peer applications. In fact, the change has been so radical that, depending on the metric used, UDP traffic has become the dominant transfer protocol on many links. TCP still tends to carry the bulk of the bytes, though.
As an ISP, one might now argue that all that streaming stuff is too wideband to be practical across a shared IP satellite link anyway. This may well be true, but blocking UDP means disabling or severely hampering many popular applications, for example, Skype voice calls, which are not overly bandwidth-hungry.
Polite and impolite TCP
This leaves the argument of ‘unfriendliness’ towards TCP. The core of this argument is that TCP senders ‘back-off’ when they detect congestion (when a congested queue along the path drops their data packets and the packets don’t result in ACKs). In common wisdom, this makes TCP ‘polite’.
For UDP, there is no such mechanism by default, unless the application that uses UDP implements something, for example, Skype’s SILK codec adapts its coding and transmission rate to packet loss. So this makes UDP ‘impolite’.
However, there’s an unspoken assumption behind TCP’s ‘politeness’: that the TCP on your link will actually back off. Backing off means that the TCP senders transmitting across the link must detect the congestion, that is, detect missing ACKs, and must subsequently adjust their congestion window (the number of as-yet-unacknowledged packets allowed for the connection). For the backing off to have any effect, it must reduce the rate at which packets/bytes enter the network after the congestion window adjustment. And that requires the TCP sender to have data to transmit.
If there is no data to transmit, there is no back-off and no politeness in the TCP flow that traverses your link. How likely is this? Regardless of TCP flavour, no TCP sender can readjust the congestion window in less than the satellite RTT. That’s typically around 120 ms on medium earth orbit (MEO) satellites and around 500 ms on geostationary (GEO) satellites. Until this time expires, a TCP sender on a newly established connection can only send the number of packets specified by its initial congestion window size.
The initial congestion window size differs between platforms – on my Windows 10 laptop it’s four packets, on Linux, it’s ten packets. So let’s work with four packets for the moment.
With around 1,500 bytes per packet, that’s 6,000 bytes or 48,000 bits. On a comparatively slow 5 Mbps ADSL connection, these four packets take only about 10 ms to transmit, on faster connections even less. So the last of these packets is virtually guaranteed to have left the sender before the first ACK returns hundreds of milliseconds later.
If the total amount of data that had to be transmitted was under 6,000 bytes, then it is pretty much guaranteed that a connection of this size will never back off unless one of the four packets is lost and needs retransmitting.
If we further consider that most TCP stacks don’t reduce their congestion windows until at least a few packets have been lost, it becomes clear that TCP flows of half a dozen packets or so generally never back off. In other words, they behave like UDP and are just as unfriendly to larger TCP flows.
How common are short TCP flows?
At APRICOT 2016, I showed the following diagram (below). It reflects data collected on the O3b MEO link into Rarotonga, Cook Islands, in mid-2015. It shows that the vast majority of TCP flows fall into the ‘won’t back off’ category, even if the amount of data in these flows amounts to only a few percent of the total amount of bytes in the traffic.
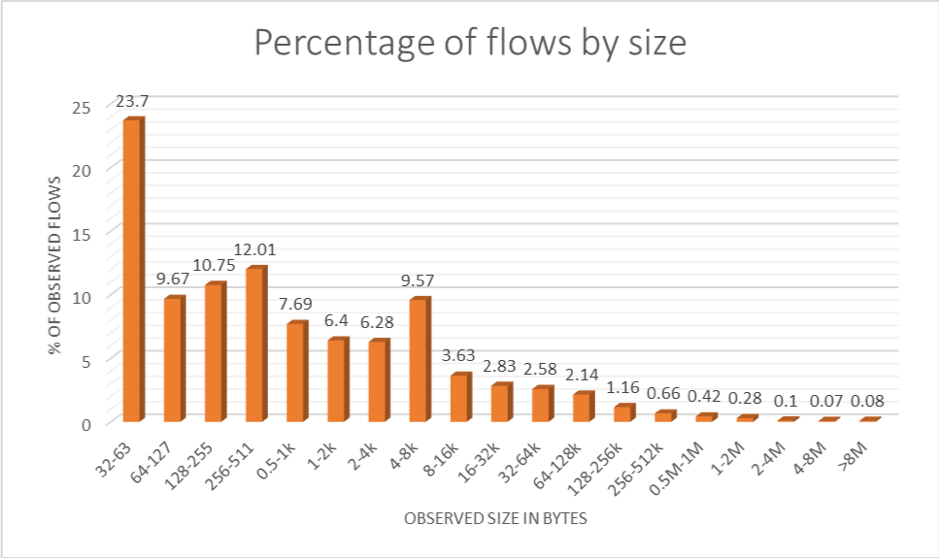
Flow size distributions such as this are quite typical, and the sort of small flows we are seeing here largely map to a category that has been known as mice in the Internet measurement community for about two decades.
Most web flows are mice — downloads of only a few kB, the typical size of HTML pages, thumbnail images, and style files. Most email messages fall into the same size category, too, as do the TCP web service exchanges of many mobile apps. We have ample evidence that these small TCP flows ‘take over’ and throttle the larger ones as load increases on a satellite link.
So, where does this leave UDP?
Many UDP applications do back off, including most audio and video streaming services. So, could UDP possibly be worse than the small TCP flows? Could TCP be its own worst enemy?
One would certainly have to expect an increase in traffic as a result of enabling UDP on a link, simply because users would then be able to use applications or access services that were previously off the menu. But this ability would also add value to their connection, and any detrimental effect could be compensated for by adding capacity.
If you’re worried about letting the genie out of the bottle, perhaps it’s possible to get the genie to pay for the widening of the bottleneck to put it back in?
So, enabling UDP could be worth a try after all.
Ulrich Speidel is a senior lecturer in Computer Science at the University of Auckland with research interests in fundamental and applied problems in data communications, information theory, signal processing and information measurement. His work was awarded ISIF Asia grants in 2014 and 2016.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.